











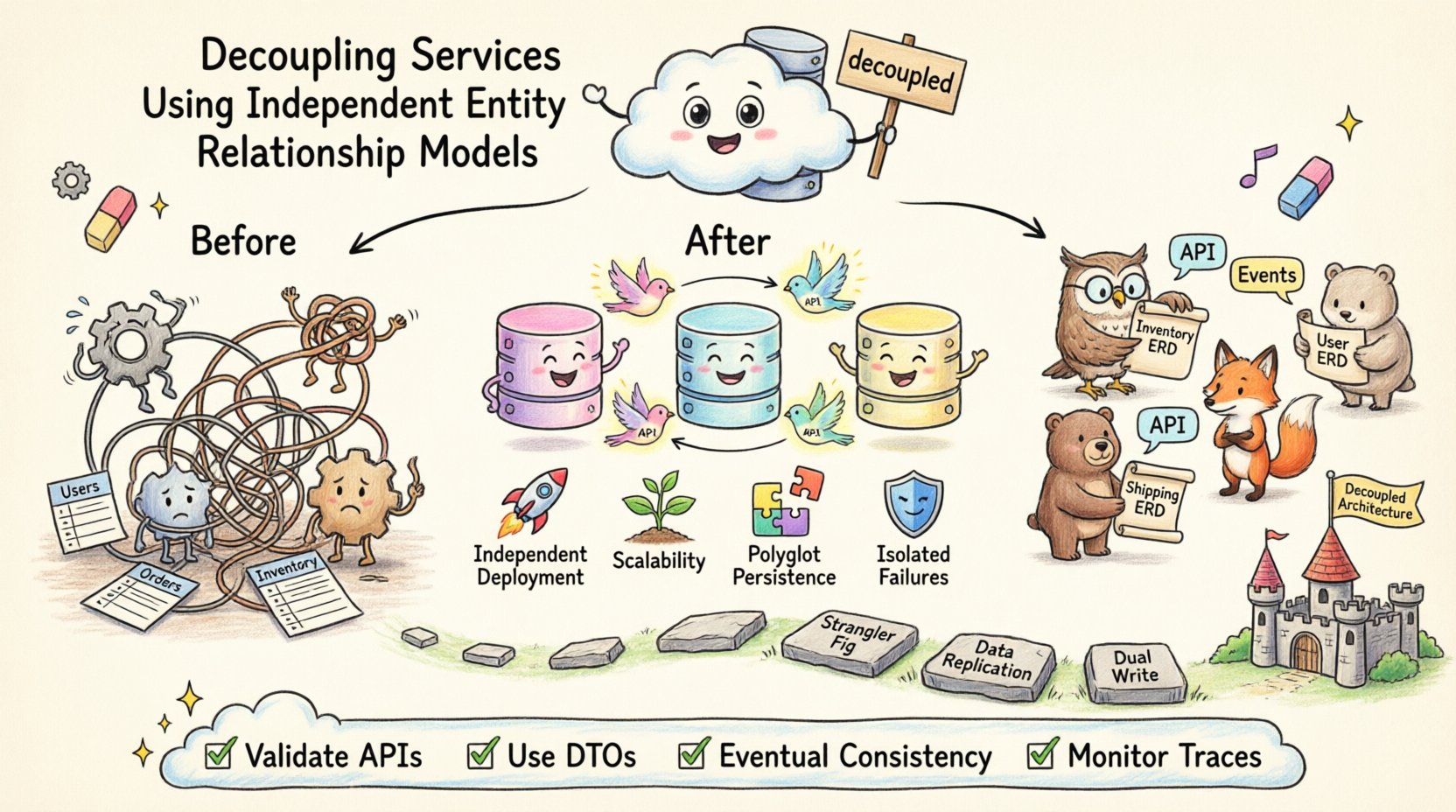
En la arquitectura de software moderna, la separación de responsabilidades se extiende más allá de la lógica del código hacia la propiedad de los datos. Cuando los servicios comparten un único esquema de base de datos, inevitablemente se vuelven dependientes de las implementaciones internas de otros servicios. Esta acoplamiento estrecho genera fragilidad, limita la velocidad de despliegue y complica los esfuerzos de escalabilidad. Para lograr una modularidad verdadera, los equipos deben adoptar modelos de relación de entidades independientes para cada frontera de servicio. Este enfoque garantiza que las estructuras de datos permanezcan privadas para el servicio que las posee, promoviendo resiliencia y autonomía.
🤔 El desafío de los datos compartidos
Los sistemas heredados a menudo dependen de una base de datos monolítica donde múltiples módulos de aplicación consultan las mismas tablas. Aunque esto simplifica el desarrollo inicial, introduce riesgos significativos a medida que el sistema crece. Un cambio en los requisitos de datos de un módulo puede romper la funcionalidad de otro módulo que dependa de la misma estructura de tabla. Este fenómeno se conoce como el anti-patrón de base de datos compartida.
Considere un escenario en el que el Servicio de Usuario necesita agregar un nuevo campo a la tabla de perfiles. Si el Servicio de Pedidos consulta directamente esa tabla para obtener nombres de usuarios, la actualización podría requerir un despliegue coordinado o una migración de base de datos que afecte a ambos equipos simultáneamente. Esta sobrecarga de coordinación ralentiza la innovación y aumenta el riesgo de incidentes en producción.
-
Dependencias de despliegue:Los servicios no pueden desplegarse de forma independiente si comparten definiciones de esquema.
-
Límites de escalabilidad:Una sola base de datos a menudo se convierte en un cuello de botella cuando ciertos servicios requieren más recursos que otros.
-
Riesgos de seguridad:El acceso directo a tablas evita la capa de servicio, lo que podría exponer lógica sensible de datos.
🗺️ Definición de modelos de relación de entidades independientes
Un modelo de relación de entidades independiente (ERD) asigna un esquema de datos específico a un único servicio. Esto significa que el servicio controla su propia base de datos, sus propias tablas y sus propias relaciones. Otros servicios no tienen acceso directo a estas tablas. En su lugar, interactúan a través de interfaces definidas, como APIs o colas de mensajes.
Este estilo arquitectónico a menudo se conoce como Base de datos por servicio. Alinea la propiedad de los datos con las capacidades del negocio. Por ejemplo, un Servicio de Inventario gestiona los niveles de stock, mientras que un Servicio de Envíos gestiona las direcciones de entrega. Ningún servicio debería tener una referencia de clave foránea a las tablas internas del otro.
El proceso implica:
-
Identificación de fronteras:Determine qué datos pertenecen a qué capacidad del negocio.
-
Diseño de esquemas locales:Cree ERDs que solo respalden las necesidades específicas de ese servicio.
-
Definición de interfaces:Establezca cómo se intercambia la data entre servicios sin exponer sus estructuras internas.
📈 Principales beneficios de la aislamiento de esquemas
Adoptar ERDs independientes transforma la forma en que los equipos gestionan la complejidad. Cambia el enfoque desde el control centralizado hacia la autonomía distribuida. Cada equipo puede optimizar su estrategia de almacenamiento de datos sin preocuparse por los impactos globales.
|
Aspecto |
Modelo de base de datos compartida |
Modelo de ERD independiente |
|---|---|---|
|
Despliegue |
Coordinado, arriesgado |
Independiente, frecuente |
|
Escalabilidad |
Solo horizontal (clúster) |
Vertical por servicio |
|
Tecnología |
Un solo tipo de base de datos |
Persistencia políglota |
|
Dominio de fallos |
Punto único de fallo |
Fallos aislados |
🔗 Diseñando para acoplamiento débil
Cuando los servicios no pueden comunicarse directamente con las bases de datos de otros servicios, deben comunicarse a través de APIs. Esto requiere un diseño cuidadoso del contrato entre servicios. La API se convierte en el único contrato compartido. Si el contrato de la API permanece estable, el modelo de datos subyacente puede cambiar sin afectar a los consumidores.
Versionado de API: Dado que los modelos de datos evolucionan, las APIs deben admitir versionado. Esto permite que los clientes antiguos sigan funcionando mientras los nuevos adoptan estructuras actualizadas.
Objetos de transferencia de datos (DTOs): No expongas objetos de entidad directamente. Crea DTOs específicos que transporten solo los datos necesarios para el consumidor. Esto evita que los cambios internos se propaguen hacia afuera.
-
Validación: Valida la entrada en el límite de la API, no solo a nivel de base de datos.
-
Idempotencia: Asegúrate de que las operaciones puedan repetirse de forma segura sin causar registros duplicados.
-
Documentación: Mantén una documentación clara para todos los formatos de intercambio de datos.
⚖️ Manejo de transacciones y consistencia
Uno de los desafíos más importantes en el desacoplamiento es mantener la integridad de los datos. En una base de datos compartida, una transacción puede abarcar múltiples tablas fácilmente. En un sistema distribuido, una transacción lógica única puede abarcar múltiples servicios. Esto se conoce como el Problema de transacción distribuida.
Para resolver esto, los equipos a menudo adoptan el Consistencia eventual patrón. En lugar de garantizar que los datos sean idénticos en todas partes de inmediato, el sistema garantiza que se vuelvan consistentes con el tiempo. Esto se logra mediante mensajes asíncronos.
Patrón Saga: Una saga es una secuencia de transacciones locales. Cada transacción actualiza la base de datos y publica un evento para desencadenar la siguiente transacción. Si un paso falla, se ejecutan transacciones compensatorias para deshacer los cambios anteriores.
-
Patrón Outbox: Escriba eventos en una tabla local junto con el cambio principal de datos. Un proceso en segundo plano publica estos eventos, asegurando que no se pierda ningún dato.
-
Consumidores idempotentes:Los manejadores de mensajes deben manejar los mensajes duplicados de forma adecuada.
-
Acciones compensatorias:Defina una lógica de reversión clara para cada acción hacia adelante.
🚚 Estrategias de migración
Migrar desde una base de datos compartida a ERDs independientes es una tarea importante. Requiere un enfoque por fases para minimizar el riesgo. Apresurarse en la migración puede provocar pérdida de datos o interrupciones del servicio.
Patrón Figura de estrangulación:Mueva gradualmente la funcionalidad a nuevos servicios. Comience con una característica específica, como las notificaciones de usuarios. Cree un nuevo servicio con su propio ERD para esa característica. Redirija el tráfico al nuevo servicio mientras mantiene el sistema heredado en funcionamiento.
Replicación de datos:Durante la transición, es posible que deba mantener los datos sincronizados entre la base de datos antigua y la nueva. Esto permite que el nuevo servicio lea datos del sistema antiguo temporalmente mientras se llena con sus propios datos.
Escritura dual:Escriba en ambas bases de datos, la antigua y la nueva, simultáneamente durante la ventana de migración. Verifique que el nuevo servicio funcione correctamente antes de deshabilitar las escrituras antiguas.
🔍 Monitoreo y mantenimiento
Con almacenes de datos independientes, el monitoreo se vuelve más complejo. Ya no está mirando un único panel de salud de base de datos. Debe agrupar registros y métricas de múltiples fuentes.
Rastreo distribuido:Implemente el rastreo para seguir una solicitud mientras pasa por diferentes servicios. Esto ayuda a identificar qué servicio está causando latencia o errores.
Registro de esquemas:Mantenga un registro de contratos de API. Esto garantiza que cualquier cambio en un modelo de datos sea revisado y aprobado antes de la implementación.
-
Alertas:Configure alertas para la latencia de replicación y los cuellos de botella en la cola de mensajes.
-
Planificación de capacidad:Monitoree el crecimiento del almacenamiento por servicio para evitar costos imprevistos.
-
Estrategias de copia de seguridad:Asegúrese de que cada servicio tenga su propio plan de copia de seguridad y recuperación.
🛠️ Errores comunes que deben evitarse
Aunque se cuente con un plan sólido, los equipos a menudo tropiezan durante la implementación. Comprender estos errores comunes puede ahorrar tiempo y esfuerzo significativos.
-
Acoplamiento oculto:Evite usar vistas de base de datos o tablas compartidas, incluso si están en esquemas separados. El acceso directo a la base de datos debe prohibirse.
-
Sobrefragmentación:No cree una nueva base de datos para cada función pequeña. Agrupe entidades relacionadas en servicios lógicos.
-
Ignorar la latencia:Las llamadas de red son más lentas que las consultas locales. Diseñe las API para minimizar los viajes de ida y vuelta.
-
Consultas complejas:Evite las uniones entre servicios. Si necesita datos de múltiples servicios, consulte cada uno por separado y combine los resultados en la capa de aplicación.
🧱 Reflexiones finales
Desacoplar servicios utilizando modelos independientes de relaciones de entidades es una decisión estratégica que da sus frutos a largo plazo. Requiere disciplina en el diseño y una disposición para gestionar la complejidad distribuida. Sin embargo, el resultado es un sistema más fácil de escalar, más resistente a los fallos y más rápido de evolucionar. Al poseer sus propios datos, los servicios adquieren la autonomía necesaria para innovar sin una coordinación constante.
Comience identificando los límites más críticos en su sistema. Aísle primero los datos para esos servicios. Refine sus contratos de API y sus patrones de mensajería a medida que avanza. Este enfoque incremental garantiza estabilidad mientras avanza hacia una arquitectura completamente desacoplada.