











Die Datenbankarchitektur entwickelt sich gemeinsam mit der Komplexität der Anwendung. In den frühen Entwicklungsphasen reicht oft eine einzige Datenbank aus, um alle Datenoperationen zu bewältigen. Wenn sich das System jedoch weiterentwickelt, wird das ursprüngliche Schema häufig zur Engstelle. Dieser Zustand wird allgemein als monolithisches Schema bezeichnet. Es zeichnet sich durch eng miteinander verbundene Tabellen, redundante Daten und starre Beschränkungen aus, die die Skalierbarkeit behindern. Um diesem Problem zu begegnen, greifen Ingenieure auf eine strukturelle Neugestaltung zurück. Die Entitäts-Beziehungs-Modellierung (ERM) bietet den theoretischen Rahmen, um diese Änderungen effektiv zu visualisieren und zu organisieren. Dieser Leitfaden untersucht den technischen Prozess des Refactorings monolithischer Schemata unter Verwendung von ERM-Prinzipien, um eine widerstandsfähigere Datenebene zu erreichen.
Das Problem des monolithischen Schemas verstehen 📉
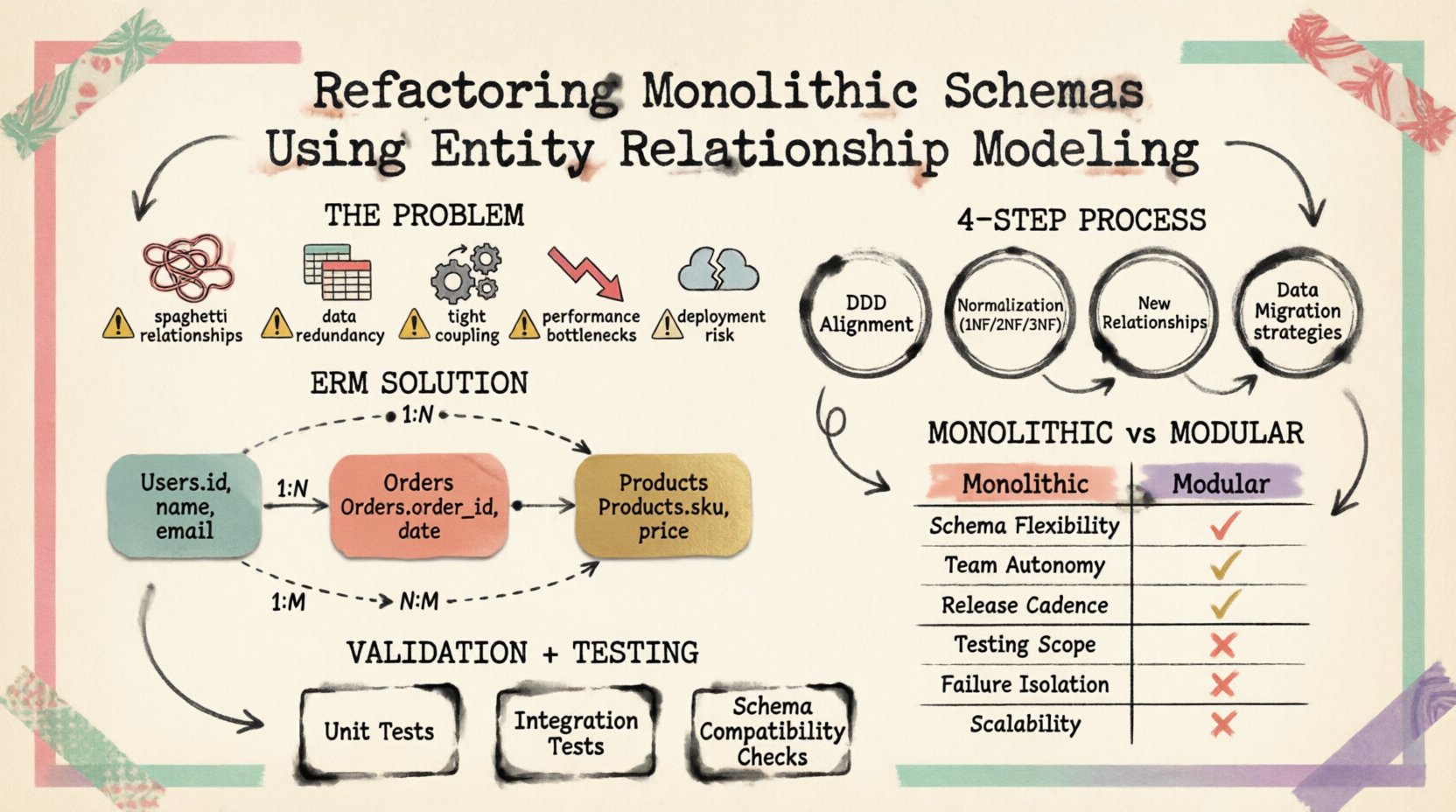
Ein monolithisches Schema entsteht typischerweise aus organischem Wachstum statt bewusster Planung. Funktionen werden hinzugefügt, und Tabellen werden erstellt, um unmittelbare Bedürfnisse zu erfüllen, ohne zukünftige Trennungen zu berücksichtigen. Im Laufe der Zeit entstehen dadurch mehrere Indikatoren für technischen Schulden:
- Spaghetti-Beziehungen: Fremdschlüssel verknüpfen unzusammenhängende Entitäten und erzeugen zirkuläre Abhängigkeiten.
- Datenredundanz: Die gleichen Informationen werden in mehreren Tabellen gespeichert, was bei Aktualisierungen zu Konsistenzproblemen führt.
- Starke Kopplung: Die Anwendungslogik kann nicht entkoppelt werden, da die Datenbankstruktur dies erzwingt.
- Leistungsengpässe: Große Tabellen mit gemischten Datentypen erfordern komplexe Abfragen, die die Leseoperationen verlangsamen.
- Bereitstellungsrisiko: Die Änderung einer einzelnen Tabelle erfordert oft gleichzeitige Änderungen an mehreren Anwendungsdiensten.
Die Erkennung dieser Symptome ist der erste Schritt zur Behebung. Das Ziel besteht nicht darin, lediglich Tabellen neu zu ordnen, sondern die Datenstruktur mit den logischen Bereichen des Geschäfts auszurichten.
Die Rolle der Entitäts-Beziehungs-Modellierung 📐
Die Entitäts-Beziehungs-Modellierung dient als Bauplan für die Datenbankgestaltung. Sie definiert Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel) in einer visuellen und logischen Form. Beim Refactoring fungiert die ERM als Kontrollmechanismus, um sicherzustellen, dass die neue Struktur konsistent bleibt.
Wesentliche Komponenten der ERM
- Entitäten: Stellen unterschiedliche Objekte oder Konzepte dar, wie zum Beispiel Benutzer oder Bestellungen. In einem Schema werden diese zu Tabellen.
- Attribute: Eigenschaften, die die Entität beschreiben, wie zum Beispiel E-Mail oder Preis. Diese werden auf Spalten abgebildet.
- Beziehungen: Definiert, wie Entitäten interagieren, beispielsweise Eins-zu-Eins oder Eins-zu-Viele.
- Kardinalität: Gibt die minimale und maximale Anzahl von Instanzen an, die an einer Beziehung beteiligt sind.
Die Verwendung des ERM während der Umgestaltung ermöglicht es Teams, Änderungen zu simulieren, bevor sie in die Produktionsumgebung übertragen werden. Es hilft, verwaiste Daten, fehlende Einschränkungen und Normalisierungsprobleme bereits früh im Prozess zu erkennen.
Phase der Vor-Refaktorisierung-Beurteilung 🔍
Bevor irgendeine bestehende Tabelle geändert wird, ist eine gründliche Prüfung erforderlich. Diese Phase stellt sicher, dass während des Übergangs kein Geschäftslogik verloren geht.
- Bestand bestehender Tabellen: Dokumentieren Sie jede Tabelle, jedes Feld, jeden Index und jede Einschränkung, die derzeit im System vorhanden ist.
- Analyse von Abfragemustern: Identifizieren Sie, welche Abfragen am häufigsten ausgeführt werden und welche Tabellen am häufigsten gelesen werden.
- Datenumhängigkeiten abbilden: Verfolgen Sie, wie Daten von der Datenbank zur Anwendung und zurück fließen.
- Redundante Spalten identifizieren: Suchen Sie nach Spalten, die dieselbe Information in mehreren Tabellen speichern.
- Fremdschlüssel überprüfen: Bestimmen Sie, ob Beziehungen auf Datenbankebene oder in Code verwaltet werden.
Diese Beurteilung schafft eine Grundlage. Ohne sie kann die Refaktorisierung subtile Fehler einführen, die später schwer nachzuverfolgen sind.
Der Refaktorisierungsprozess: Schritt für Schritt 🔄
Die Umwandlung eines monolithischen Schemas in eine modulare Struktur erfordert einen systematischen Ansatz. Die folgenden Schritte skizzieren den Standardablauf für die Schema-Refaktorisierung mithilfe des Entity-Relationship-Modellierungsansatzes.
1. Ausrichtung an domain-driven Design (DDD)
Beginnen Sie damit, Tabellen basierend auf Geschäftsbereichen zu gruppieren. Dies wird oft als begrenzter Kontext bezeichnet. Organisieren Sie die Tabellen nicht nach Funktion (z. B. alle Tabellen für Berichterstattung), sondern nach Fähigkeiten (z. B. Tabellen für Abrechnung, Tabellen für Authentifizierung). Diese Trennung verringert die Kopplung zwischen unzusammenhängenden Teilen des Systems.
2. Normalisierung
Die Normalisierung reduziert Datenredundanz und verbessert die Integrität. Der Prozess besteht darin, große Tabellen in kleinere, logisch verwandte aufzuteilen.
- Erste Normalform (1NF): Stellen Sie atomare Werte sicher. Jede Spalte sollte nur einen einzigen Wert enthalten.
- Zweite Normalform (2NF): Entfernen Sie partielle Abhängigkeiten. Alle nichtschlüsselbasierten Attribute müssen sich auf den gesamten Primärschlüssel beziehen.
- Dritte Normalform (3NF): Entfernen Sie transitive Abhängigkeiten. Nichtschlüsselbasierte Attribute sollten sich nicht auf andere nichtschlüsselbasierte Attribute beziehen.
Während 3NF das Standardziel ist, können bestimmte Leistungsanforderungen eine kontrollierte Denormalisierung erfordern. Diese Entscheidung muss dokumentiert werden.
3. Definieren neuer Beziehungen
Sobald Tabellen aufgeteilt sind, müssen die Beziehungen wiederhergestellt werden. Dazu gehören die Erstellung neuer Fremdschlüssel und Verbindungstabellen für viele-zu-viele-Beziehungen. Zum Beispiel, wenn ein Produkt zu mehreren Kategorien gehört, ist eine Verbindungstabelle erforderlich, um sie zu verknüpfen.
4. Datenmigration-Strategie
Der Datenverschiebung von der alten zur neuen Struktur ist die riskanteste Phase. Strategien beinhalten:
- Snapshot-Migration:Schreiben stoppen, Daten exportieren, transformieren und in die neue Struktur importieren. Erfordert Ausfallzeit.
- Doppeltes Schreiben:Während einer Übergangsphase gleichzeitig in die alte und die neue Struktur schreiben.
- Log-basierte Replikation:Änderungen aus dem Datenbank-Transaktionsprotokoll erfassen und auf die neue Struktur anwenden.
Häufige Fehler, die vermieden werden sollten 🛑
Refactoring führt zu Komplexität. Bestimmte Fehler können die Integrität des Systems gefährden.
- Ignorieren von Datentypen:Die Änderung einer Spalte von Integerzu Stringohne die nachfolgende Logik zu überprüfen, kann den Anwendungscode beschädigen.
- Über-Normalisierung:Die Erstellung zu vieler Tabellen kann zu übermäßigen Joins führen und die Abfrageleistung verschlechtern.
- Verlust von Einschränkungen:Das Verschieben von Einschränkungen von der Datenbank in die Anwendungsschicht kann zu Datenkorruption führen, wenn mehrere Dienste auf dieselben Daten schreiben.
- Index-Vernachlässigung:Neue Tabellen erfordern neue Indizes. Das Auslassen der Indizierung neuer Fremdschlüssel verlangsamt Joins.
Validierungs- und Teststrategien ✅
Nach der Neugestaltung des Schemas ist die Validierung entscheidend. Automatisierte Tests sollten sicherstellen, dass die Datenintegrität über die neuen Grenzen hinweg gewahrt bleibt.
- Prüfungen der Datenkonsistenz:Führen Sie Abfragen aus, um sicherzustellen, dass die Referenzintegrität über alle neuen Beziehungen hinweg gewahrt bleibt.
- Leistungsbenchmarking:Vergleichen Sie die Ausführungszeiten von Abfragen vor und nach der Umgestaltung.
- Prüfung der Zeilenanzahl:Stellen Sie sicher, dass die Gesamtanzahl der Datensätze konstant bleibt (doppelte Einträge, die während der Migration entstehen, ausgenommen).
- Anwendungs-Regressionstests:Führen Sie die vollständige Suite an Anwendungstests gegen die neue Datenbankstruktur aus.
Vergleich: Monolithisches vs. Modulares Schema
Die Tabelle unten zeigt die Unterschiede zwischen der veralteten monolithischen Struktur und dem neu gestalteten modularen Ansatz.
| Funktion | Monolithisches Schema | Neu gestaltetes Schema |
|---|---|---|
| Tabellenstruktur | Große Tabellen mit gemischten Zwecken | Spezialisierte, domänenspezifische Tabellen |
| Datenduplikation | Hoch | Durch Normalisierung minimiert |
| Skalierbarkeit | Schwierig zu sharden | Einfacher durch Domänenpartitionierung |
| Bereitstellung | Globale Schemaänderungen | Lokalisierte Schemaaktualisierungen |
| Abfragekomplexität | Komplexe Joins auf großen Tabellen | Optimierte Joins auf kleineren Tabellen |
Wechsel zu einer Microservices-Architektur 🚀
Das Refactoring des Schemas ist oft eine Voraussetzung für die Einführung von Microservices. Ein sauberes Entitäts-Beziehungs-Modell erleichtert die Zuweisung der Verantwortung für bestimmte Daten an bestimmte Dienste. Wenn jeder Dienst seine eigene Datenbank verwaltet, wird das Schema zu einem Vertrag zwischen Diensten statt zu einer gemeinsam genutzten Ressource.
Dieser Wandel erfordert eine sorgfältige Behandlung der Datenkonsistenz. Anstatt Transaktionen über mehrere Datenbanken hinweg zu nutzen, können Systeme auf Muster der eventual consistency setzen. Das ERM hilft dabei, diese Grenzen klar zu definieren und sicherzustellen, dass kein Dienst die Verantwortung für Daten übernimmt, die er nicht verwaltet.
Abschließende Überlegungen für die langfristige Gesundheit 🛡️
Die Aufrechterhaltung eines gesunden Schemas erfordert kontinuierliche Disziplin. Die Dokumentation muss aktualisiert werden, sobald eine Tabelle hinzugefügt oder geändert wird. Versionskontrolle sollte auf die Schemadefinitionen angewendet werden, nicht nur auf den Anwendungscode. Regelmäßige Überprüfungen sollten geplant werden, um neue Fälle von Kopplung zu erkennen, wenn Funktionen hinzugefügt werden.
Das Entitäts-Beziehungs-Modellieren ist keine einmalige Aufgabe. Es ist eine kontinuierliche Praxis, die sicherstellt, dass die Datenbank mit den geschäftlichen Anforderungen Schritt hält. Durch die Einhaltung dieser strukturierten Schritte können Organisationen die Risiken, die mit veralteten Datenstrukturen verbunden sind, minimieren und eine Grundlage schaffen, die zukünftiges Wachstum unterstützen kann.
Der Übergang von einem monolithischen Schema zu einem modularen Design ist eine erhebliche Aufgabe. Er erfordert Geduld, gründliche Tests und ein tiefes Verständnis der Datenbeziehungen. Dennoch führt das Ergebnis zu einem System, das einfacher zu pflegen ist, schneller skalierbar ist und widerstandsfähiger gegenüber Veränderungen ist. Die in der Modellierung investierte Anstrengung zahlt sich langfristig in operativer Stabilität und höherer Entwicklergeschwindigkeit aus.