









In der Landschaft skalierbarer Softwarearchitektur ist der Begriff der Mehrfachnutzung grundlegend. Eine einzelne Anwendungsinstanz dient mehreren Kunden, sogenannten Nutzern, während die logische Trennung der Daten gewahrt bleibt. Die Gestaltung der zugrundeliegenden Datenstruktur erfordert Präzision. Entitäts-Beziehungs-Diagramme (ERD) dienen als Bauplan für diese Architektur. Sie visualisieren die Beziehungen zwischen Tabellen, Schlüsseln und Einschränkungen, die die Datenintegrität über alle Nutzer hinweg sichern. 📐
Beim Erstellen eines ERD für eine mehrfach genutzte Umgebung liegt die primäre Herausforderung in der Abwägung zwischen Isolation, Leistung und Kosten. Es gibt keine einzige Lösung, die für jedes Szenario geeignet ist. Stattdessen müssen Architekten ein Muster wählen, das den Sicherheitsanforderungen und dem operativen Budget entspricht. Dieser Artikel untersucht die zentralen Strategien zur Modellierung dieser Schemas und bietet einen detaillierten Einblick in technische Implementierungsdetails, ohne sich auf spezifische Anbieterwerkzeuge zu stützen. 🛠️
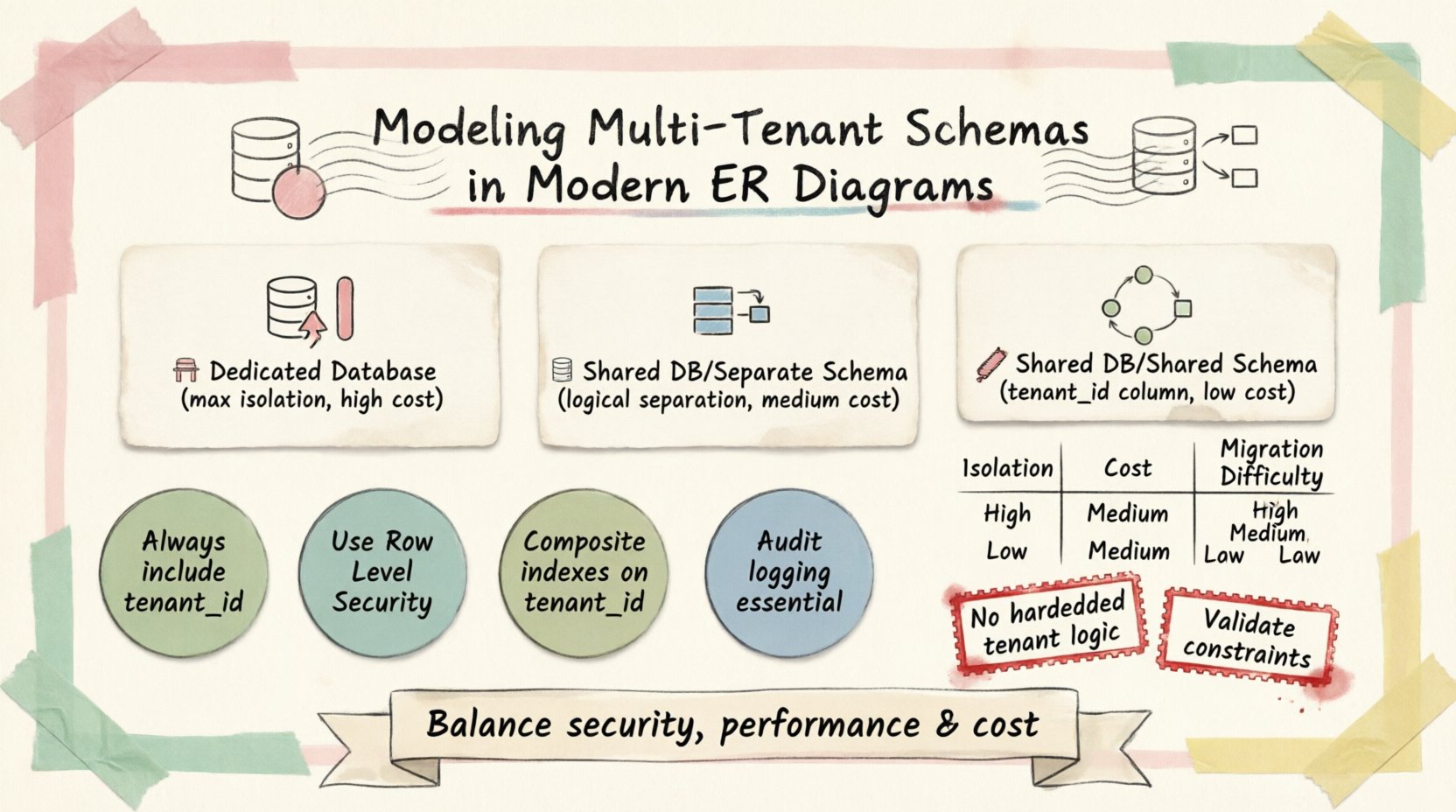
Verständnis der Kernmuster 🔍
Die Grundlage der Modellierung mehrfach genutzter Systeme liegt darin, wie Nutzerdaten physisch gespeichert und logisch getrennt werden. Drei unterschiedliche Muster dominieren die Branche. Jedes bietet einzigartige Abwägungen hinsichtlich der Datenisolation und der Wartungskomplexität.
1. Eigenständige Datenbank pro Nutzer 🏢
Bei diesem Ansatz erhält jeder Kunde eine eigene isolierte Datenbankinstanz. Die ERD-Struktur bleibt bei allen Instanzen identisch, doch die physischen Grenzen sind strikt.
- Isolierungsgrad:Maximal. Ein Ausfall in einer Datenbank beeinträchtigt andere nicht.
- Sicherheit:Hoch. Die physische Trennung verhindert versehentliche Datenlecks.
- Kosten:Höher aufgrund des Ressourcenaufwands pro Instanz.
- Migration:Komplex. Schemaänderungen erfordern das Ausführen von Skripten über jede Instanz hinweg.
Aus Sicht des ERD wirkt dieses Muster wie ein standardmäßiges Diagramm für einzelne Nutzer. Der Bereitstellungspipeline müssen jedoch mehrere Verbindungen verwaltet werden. Dies wird häufig bei Unternehmenskunden mit strengen Compliance-Anforderungen eingesetzt.
2. Gemeinsame Datenbank, getrennte Schemata 📂
Hier befinden sich alle Nutzer innerhalb eines einzigen Datenbanksystems, aber jeder Nutzer verfügt über sein eigenes eigenständiges Schema (Namensraum). Tabellen werden pro Schema dupliziert.
- Isolierungsgrad:Hoch. Logische Trennung innerhalb der Datenbankengine.
- Sicherheit:Stark. Zugriffssteuerungslisten (ACLs) können die Sichtbarkeit von Schemata einschränken.
- Kosten:Mäßig. Teilt die Überhead-Kosten der Datenbankengine.
- Wartung:Einfacher als bei eigenständigen Datenbanken, doch Schema-Updates müssen auf alle Schemata übertragen werden.
Im ERD wird dies durch Gruppierung von Tabellen unter spezifischen Namensraumbezeichnungen dargestellt. Die Beziehungen bleiben konsistent, doch der Umfang des Diagramms erweitert sich, um mehrere Schemakontainer zu zeigen.
3. Gemeinsame Datenbank, gemeinsames Schema 🔗
Dies ist das häufigste Muster für allgemeine SaaS-Anwendungen. Alle Daten befinden sich in derselben Gruppe von Tabellen, die durch eine bestimmte Spalte unterschieden werden.
- Isolierungsgrad: Logisch. Alle Zeilen existieren in derselben Tabelle.
- Sicherheit:Abhängig von der Anwendungslogik und der Zeilenbereichs-Sicherheit (RLS).
- Kosten:Niedrigste. Maximiert die Ressourcennutzung.
- Wartung:Einfach. Schemaänderungen wirken sich sofort auf alle Mieter aus.
Das ERD für dieses Muster führt eine kritische Spalte ein: tenant_id. Diese Fremdschlüssel verknüpft jede Aufzeichnung mit einem bestimmten Kunden. Es ist der Eckpfeiler der Datenabgrenzung in diesem Modell.
Visualisierung von Mieterdaten in ERDs 📊
Die Erstellung eines effektiven ERDs für Mehrfachnutzer erfordert spezifische Notationen, um die Aufteilungsstrategie klar zu kommunizieren. Stakeholder müssen verstehen, wie Daten fließen und wo Grenzen bestehen.
Die Spalte Mieter-ID
Bei einem gemeinsamen Schema muss die tenant_idauf jeder Tabelle erscheinen, die datenspezifische Daten für Benutzer speichert. Dies ist nicht optional. Das Weglassen dieser Spalte aus einer transaktionalen Tabelle kann zu schwerwiegenden Datenlecks führen.
- Primärschlüssel: Häufig bildet die Kombination aus
tenant_idund einer lokalen ID einen zusammengesetzten Primärschlüssel. - Indizierung:Wesentlich für die Leistung. Abfragen, die nach
tenant_idfiltern, müssen schnell sein. - Einschränkungen:Fremdschlüssel verweisen oft auf eine zentrale
tenantsMaster-Tabelle.
Master-Tabelle für Mieter
Üblicherweise existiert eine spezielle Tabelle, um Metadaten zu jedem Mieter zu speichern. Diese Tabelle enthält Konfigurationseinstellungen, den Abonnementstatus und Rechnungsinformationen.
- Schlüsselmerkmale:Mietvertrag-ID, Name, Plan-Stufe, Erstellungsdatum.
- Beziehungen: Eins-zu-Viele mit allen anderen Datentabellen.
Vergleich von Schema-Strategien 📋
Um eine fundierte Entscheidung zu treffen, vergleichen Sie die betrieblichen Auswirkungen jeder Strategie mithilfe der folgenden Tabelle.
| Funktion | Dedizierte DB | Geteiltes Schema | Geteilte Tabelle |
|---|---|---|---|
| Datenisolation | Physisch | Logisch | Logisch |
| Abfragekomplexität | Einfach | Komplex | Komplex |
| Ressourcenkosten | Hoch | Mittel | Niedrig |
| Schema-Migration | Schwer | Mittel | Einfach |
| Sicherungsstrategie | Fein granular | Fein granular | Vollständiger Dump |
Sicherheit und Datenpartitionierung 🔒
Die Modellierung des Schemas ist nur die halbe Miete. Die Datenzugriffsschicht muss die in der Abbildung definierten Grenzen durchsetzen. Die logische Isolation ist das Ziel bei der Verwendung gemeinsamer Tabellen.
Sicherheit auf Zeilenebene (RLS)
Moderne Datenbank-Engines unterstützen RLS, die den Zugriff auf Zeilenebene durchsetzt. Dadurch kann die Datenbank selbst Ergebnisse basierend auf dem aktuellen Benutzerkontext filtern.
- Richtliniendefinition: Eine Regel besagt, dass eine Zeile nur sichtbar ist, wenn
tenant_idmit der Sitzung übereinstimmt. - Implementierung: Das ERD sollte die Fähigkeit zur Speicherung des Sitzungskontexts widerspiegeln.
- Vorteil: Verringert das Risiko, dass Anwendungsfehler zu Datenlecks führen.
Auditing und Protokollierung
Jede Änderung an tenant-spezifischen Daten sollte protokolliert werden. Eine Audit-Tabelle ist im ERD unverzichtbar, um nachzuverfolgen, wer was und wann geändert hat. Dies ist entscheidend für Compliance und Debugging.
- Erforderliche Felder: Tenant-ID, Benutzer-ID, Aktion, Zeitstempel, Alter Wert, Neuer Wert.
- Aufbewahrungsfrist: Richtlinien müssen definieren, wie lange Protokolle aufbewahrt werden.
Leistungsüberlegungen ⚡
Gemeinsame Tabellen führen zu Komplexität in den Abfrageausführungsplänen. Je größer das Datenvolumen wird, muss die Datenbankengine die Tenant-Daten effizient trennen, ohne die gesamte Tabelle zu scannen.
Indizierungsstrategien
Standard-Indizierung reicht nicht aus. Sie benötigen zusammengesetzte Indizes, die den Tenant-Identifikator priorisieren.
- Primärer Index: Soll mit
tenant_idgefolgt vom natürlichen Schlüssel. - Abfrageoptimierung: Stellen Sie sicher, dass alle Abfragen den Tenant-Filter im
WHEREKlausel enthalten. - Partitionierung: Einige Systeme ermöglichen die physische Partitionierung von Tabellen nach
tenant_idBereich oder Hash.
Abfragekomplexität
Beim Verknüpfen von Tabellen über mehrere Schemas oder Mandanten muss die Verknüpfungsbedingung die Mandanten-ID enthalten. Andernfalls kann es zu einem kartesischen Produkt von Daten verschiedener Kunden kommen.
- Verknüpfungslogik: Stets verknüpfen Sie mit
tenant_idUND dem Beziehungsschlüssel. - Anwendungsebene:Die Middleware sollte den Mandantenfilter automatisch einfügen.
Wartung und Migration 🔄
Schemas sind nicht statisch. Sie entwickeln sich weiter, je nachdem, wie sich die Anforderungen ändern. Die Mehrfachnutzung (Multi-Tenancy) fügt diesen Änderungen eine zusätzliche Schwierigkeit hinzu.
Schema-Evolution
Das Hinzufügen einer Spalte ist in einer gemeinsam genutzten Tabelle einfach. Das Löschen einer Spalte betrifft alle Mandanten. Bei einem dedizierten Datenbankmodell müssen Sie die Änderung für jede Instanz separat skripten.
- Versionsverwaltung: Verfolgen Sie Schema-Versionen, um die Abwärtskompatibilität zu verwalten.
- Rückgängigmachungen: Haben Sie einen Plan, um Änderungen rückgängig zu machen, falls eine Migration bei einem Teil der Mandanten fehlschlägt.
Sicherungen und Wiederherstellung
Die Wiederherstellungsstrategien unterscheiden sich je nach Muster. Bei einer dedizierten Datenbank können Sie einen einzelnen Mandanten wiederherstellen, ohne andere zu beeinflussen. Bei einer gemeinsam genutzten Datenbank müssen Sie die gesamte Instanz wiederherstellen.
- Feinheit: Gemeinsam genutzte Tabellen machen die Wiederherstellung zu einem bestimmten Zeitpunkt für einen einzelnen Mandanten schwierig.
- Testen: Testen Sie die Wiederherstellungsverfahren regelmäßig in einer Staging-Umgebung.
Häufige Fehler, die Sie vermeiden sollten ⚠️
Selbst bei einem gut gestalteten ERD können Implementierungsfehler das System gefährden. Seien Sie bei diesen häufigen Problemen wachsam.
- Hartkodierte Mandantenlogik: Härten Sie niemals Mandanten-IDs im Anwendungscode. Verwenden Sie Konfiguration oder Sitzungskontext.
- Globale Variablen: Vermeiden Sie die Speicherung von Mandantenkontext in globalen Variablen, die über Anfragen hinweg bestehen bleiben könnten.
- Fehlende Einschränkungen: Wenn die Datenbank nicht sicherstellt, dass
tenant_ideindeutig ist, muss die Anwendung dies strikt überprüfen. - Ignorieren der Analytik: Die Aggregation von Daten über Mandanten hinweg für Berichterstattung erfordert sorgfältige Handhabung, um das Vermischen sensibler Informationen zu vermeiden.
Best Practices für Namenskonventionen 🏷️
Konsistenz im Namensschema hilft Entwicklern, die Datenstruktur sofort zu verstehen. Verwenden Sie Präfixe oder Suffixe, um mandantenbezogene Tabellen zu kennzeichnen, falls sie in einem gemeinsamen Schema existieren.
- Tabellennamen:
tenant_name_ordersoderorders_tenant_id. - Spaltennamen: Fügen Sie stets
tenant_idexplizit in jeder Datentabelle ein. - Indizes: Benennen Sie Indizes eindeutig, z. B.
idx_orders_tenant_id.
Fazit zu Architekturwahl 🎯
Die Auswahl des richtigen mehrmandantigen Schema-Musters erfordert ein Gleichgewicht zwischen technischer Umsetzbarkeit und geschäftlichen Anforderungen. Das ERD ist das Werkzeug, das diese Entscheidung an das gesamte Team kommuniziert. Ob physische Isolation für Sicherheit oder gemeinsame Tabellen für Effizienz gewählt werden – das Diagramm muss die Grenzen eindeutig darstellen.
Durch Einhaltung strenger Modellierungsstandards, Implementierung robuster Indizierung und Aufrechterhaltung klarer Trennlogik können Sie ein System aufbauen, das sicher skaliert. Die Komplexität der Mandantenverwaltung ist beherrschbar, wenn die Grundlage solide ist. Konzentrieren Sie sich von der ersten Zeile des Diagramms an auf Datenintegrität und Leistung. 🚀