










Wenn sich die Datenansammlung beschleunigt, wird die Architektur Ihrer Datenbank-Schema zu einem entscheidenden Faktor für die Systemstabilität. Wenn eine Anwendung von Lese-lastigen Operationen zu Schreib-lastigen Workloads wechselt, erfordert das Standard-Entitäts-Beziehungs-Diagramm (ERD) oft erhebliche Anpassungen. Die Gestaltung für hohe Durchsatzraten geht über das bloße Hinzufügen von Indizes hinaus; sie erfordert eine grundlegende Neubewertung der Struktur, Verknüpfung und Speicherung von Daten. Dieser Leitfaden untersucht die notwendigen architektonischen Verschiebungen, die erforderlich sind, um die Leistung unter Druck aufrechtzuerhalten, ohne die Datenintegrität zu gefährden.
Verständnis für Schreib-lastige Workloads 📈
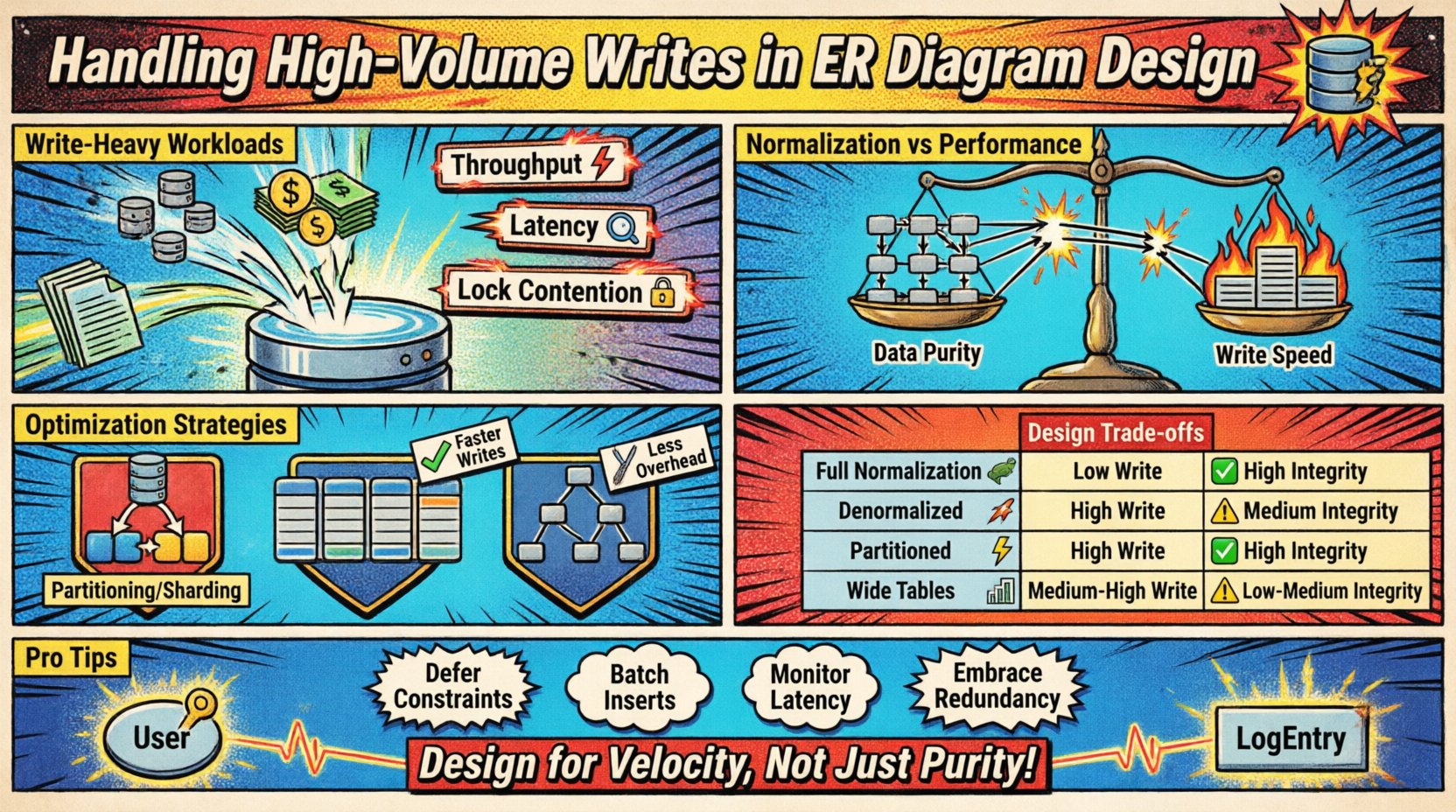
Hochvolumige Schreibszenarien treten auf, wenn die Rate eingehender Daten die Kapazität standardmäßiger Normalisierungstechniken übersteigt. Dies geschieht häufig in Protokollierungssystemen, IoT-Sensorfeeds, Finanztransaktionsprotokollen oder Echtzeit-Analyseplattformen. Die primäre Herausforderung besteht darin, die Geschwindigkeit der Einfügung mit den Konsistenzanforderungen des Modells in Einklang zu bringen.
- Durchsatz: Die Anzahl der pro Sekunde verarbeiteten Schreibvorgänge.
- Latenz: Die Zeit, die benötigt wird, um eine Aufzeichnung erfolgreich zu persistieren.
- Sperrkonkurrenz: Wettbewerb um Ressourcen, wenn mehrere Prozesse versuchen, dieselben Daten zu ändern.
Wenn diese Metriken abnehmen, ist oft das Schema selbst der Engpass. Eine starre Architektur, die für komplexe Abfragen optimiert ist, kann unter dem Gewicht ständiger Aktualisierungen zusammenbrechen. Daher muss das ursprüngliche ERD die Geschwindigkeit der Dateneingabe berücksichtigen.
Normalisierung im Vergleich zu Leistungs-Trade-offs ⚖️
Traditionelle Datenbankgestaltung fördert die Normalisierung (1NF, 2NF, 3NF), um Redundanz zu reduzieren. Obwohl dies Speicherplatz spart und Konsistenz gewährleistet, führt dies bei Schreibvorgängen zu Overhead. Jede Fremdschlüsselbeziehung erfordert eine Suche und eine Join-Prüfung, um die Referenzintegrität aufrechtzuerhalten.
In einer Umgebung mit hohem Volumen werden diese Prüfungen kostspielig. Berücksichtigen Sie die Auswirkungen einer Many-to-Many-Beziehung während eines Schreibereignisses:
- Die primäre Tabelle muss aktualisiert werden.
- Die Verbindungstabelle muss eine neue Zeile einfügen.
- Die zweite Tabelle muss die Beziehung überprüfen.
- Transaktionsprotokolle müssen alle Änderungen aufzeichnen.
Jeder Schritt fügt Festplatten-I/O und CPU-Zyklen hinzu. Um hohe Schreiblasten zu bewältigen, lockern Designer oft die Normalisierungsregeln. Dieser Prozess beinhaltet die Akzeptanz von Datenredundanz, um die Anzahl der Schreibvorgänge zu reduzieren, die erforderlich sind, um eine einzelne Informationseinheit zu speichern.
Strategien zur Optimierung der Schreibgeschwindigkeit ✍️
Mehrere strukturelle Muster existieren, um Schreibdruck zu verringern. Diese Strategien konzentrieren sich darauf, den Umfang jeder Transaktion zu minimieren und die Komplexität der Arbeit der Speicher-Engine zu reduzieren.
1. Partitionierung und Sharding
Das Aufteilen einer großen Tabelle in kleinere, besser handhabbare Teile ermöglicht es der Datenbank, die Schreiblast über mehrere physische oder logische Segmente zu verteilen.
- Horizontale Partitionierung: Aufteilung der Zeilen basierend auf einem Schlüssel (z. B. Datumsbereiche, Benutzer-IDs).
- Vertikale Partitionierung: Verschieben von selten abgerufenen Spalten in separate Tabellen.
- Sharding: Verteilen der Daten über mehrere Datenbank-Instanzen.
Dieser Ansatz reduziert die Größe der Indizes, die verwaltet werden müssen, und begrenzt den Umfang von Sperrungen während eines Schreibvorgangs. Wenn ein Shard überlastet wird, bleiben andere unbeeinflusst.
2. Denormalisierungsstrategien
Das Speichern von redundanten Daten ermöglicht es dem System, Joins während Schreibvorgängen zu vermeiden. Zum Beispiel kann das System anstelle der Berechnung einer Gesamtsumme aus zugehörigen Zeilen bei jedem neuen Transaktionsereignis direkt eine vorberechnete Zusammenfassungsspalte aktualisieren.
- Berechnete Spalten:Speichern Sie abgeleitete Werte direkt in der Zeile.
- Materialisierte Ansichten:Ergebnisse für häufige Aggregationen vorab berechnen.
- Gecachte Zähler:Einen separaten Zähler-Tabellen für Statistiken pflegen.
Während dies die Speicheranforderungen erhöht, senkt es die CPU-Kosten für Einfügungen erheblich.
3. Indexstrategie
Indizes beschleunigen Lesevorgänge, verlangsamen aber Schreibvorgänge. Bei jeder Zeileneinfügung muss die Datenbank jeden zugehörigen Index aktualisieren. In Umgebungen mit hohem Schreibvolumen wird Index-Bloat zu einem großen Problem.
- Anzahl der Indizes minimieren:Indizieren Sie nur Spalten, die für Filterung oder Verknüpfung verwendet werden.
- Partielle Indizes:Indizieren Sie nur eine Teilmenge der Zeilen, die häufig zugegriffen werden.
- Übermäßiges Indizieren vermeiden:Indizes bei Spalten überspringen, die häufig geändert werden.
Vergleich von Gestaltungsansätzen 📑
Die Tabelle unten zeigt die Auswirkungen unterschiedlicher struktureller Entscheidungen auf die Schreibleistung und die Datenintegrität.
| Strategie | Schreibleistung | Datenintegrität | Speicherkosten | Beste Einsatzmöglichkeit |
|---|---|---|---|---|
| Vollständige Normalisierung | Niedrig | Hoch | Niedrig | Komplexe Berichterstattung, geringes Schreibvolumen |
| Denormalisiert | Hoch | Mittel | Hoch | Echtzeit-Feeds, hoher Schreibvolumen |
| Partitioniertes Schema | Hoch | Hoch | Mittel | Zeitreihendaten, große Datensätze |
| Breite Tabellen | Mittel-Hoch | Mittel | Mittel | NoSQL-Muster, spärliche Daten |
Umgang mit Fremdschlüsseln und Einschränkungen 🔗
Die Referenzintegrität ist ein Eckpfeiler der relationalen Gestaltung, aber die Durchsetzung von Einschränkungen bei jeder Einfügung kann eine Hochgeschwindigkeitspipeline blockieren. Die Datenbankengine muss überprüfen, ob die referenzierte übergeordnete Zeile existiert, bevor sie die untergeordnete Zeile akzeptiert.
In Szenarien, in denen die Datenintegrität entscheidend ist, aber die Schreibgeschwindigkeit vorrangig ist, erwägen Sie die folgenden Anpassungen:
- Verzögerte Einschränkungen:Überprüfen Sie Beziehungen am Ende einer Transaktion statt sofort.
- Überprüfungen auf Anwendungsebene:Überprüfen Sie Beziehungen im Anwendungscode, bevor Sie Daten an die Datenbank senden.
- Weiche Löschungen:Markieren Sie Datensätze als inaktiv, anstatt sie zu entfernen, um Referenzverknüpfungen ohne Löschkosten zu erhalten.
Das vollständige Entfernen von Einschränkungen ist riskant, aber das Verschieben der Validierungslogik kann manchmal die Durchsatzleistung verbessern. Die Entscheidung hängt davon ab, wie kritisch sofortige Konsistenz für Ihren spezifischen Workflow ist.
Schreibverstärkung und Speicher-Engines 💾
Das Verständnis dafür, wie der Speicher-Engine Daten verarbeitet, ist entscheidend. Viele Engines verwenden ein Write-Ahead Log (WAL), um Dauerhaftigkeit zu gewährleisten. Das bedeutet, dass jeder Schreibvorgang protokolliert wird, bevor er auf die eigentlichen Datendateien angewendet wird.
Schreibverstärkungtritt auf, wenn eine einzelne logische Schreiboperation zu mehreren physischen Schreibvorgängen führt. Dies ist bei Speicher-Engines mit hohem Kompaktionsaufwand üblich. Um dies zu verwalten:
- Stapel-Inserts:Gruppieren Sie mehrere Zeilen in einer einzigen Transaktion.
- Sequenzielle Schreibvorgänge: Gestalten Sie Schemata so, dass eine sequenzielle Schlüsselgenerierung gegenüber zufälligen Einfügungen bevorzugt wird.
- Puffern: Erlauben Sie einen temporären Puffer in der Anwendungsschicht, um Schreibvorgänge vor dem Flushing zu puffer.
Durch die Ausrichtung des ERD-Entwurfs an den Stärken der Speicherengine können Sie die physische Anstrengung minimieren, die zur Persistenz von Daten erforderlich ist.
Überwachung und Iteration 🔄
Ein Schema, das für hohe Schreibvorgänge ausgelegt ist, ist nicht statisch. Wenn sich Verkehrsstrukturen ändern, könnte der Entwurf anpassungsbedürftig werden. Eine kontinuierliche Überwachung der Schreiblatenz und der Festplatten-I/O ist unerlässlich.
- Schreiblatenz verfolgen: Erkennen Sie Spitzenwerte, die Engpässe anzeigen.
- Sperrwartzeiten überwachen: Erkennen Sie Konfliktpunkte, an denen Prozesse blockiert sind.
- Indexnutzung analysieren: Entfernen Sie Indizes, die nie verwendet werden, um die Schreibbelastung zu reduzieren.
Regelmäßige Audits des ERD stellen sicher, dass die Struktur mit den aktuellen betrieblichen Anforderungen übereinstimmt. Wenn eine bestimmte Tabelle kontinuierlich mit der Schreibdurchsatzleistung kämpft, könnte es an der Zeit sein, die Partitionierungsstrategie oder das Normalisierungslevel zu überprüfen.
Zusammenfassung der wichtigsten Überlegungen 🛠️
Die Gestaltung eines ERD für hohe Schreibvolumina erfordert eine Veränderung der Denkweise von reiner Datenreinheit hin zu Systemdurchsatz. Die folgenden Punkte fassen die wesentlichen Maßnahmen zusammen:
- Normalisierung prüfen: Stellen Sie sicher, dass jede Beziehung einen Mehrwert bietet und nicht nur Komplexität hinzufügt.
- Für Partitionierung planen: Strukturieren Sie Schlüssel so, dass eine einfache horizontale Aufteilung möglich ist.
- Indizes begrenzen: Halten Sie den Schreibpfad so schlank wie möglich.
- Redundanz akzeptieren: Verwenden Sie die De-Normalisierung, um Join-Abhängigkeiten während der Einfügung zu reduzieren.
- Schrittweise validieren: Verschieben Sie die Constraint-Prüfung außerhalb des kritischen Schreibpfads, wo dies sicher ist.
Durch die Anwendung dieser Prinzipien erstellen Sie ein Datenmodell, das Wachstum ohne Leistungseinbußen bewältigen kann. Das Ziel besteht nicht darin, Komplexität zu eliminieren, sondern sie so zu managen, dass sie die Geschwindigkeit Ihrer Anwendung unterstützt.