









在健壮的数据系统架构中,实体关系图(ERD)充当基础蓝图。随着系统复杂性的增加和数据量的上升,保持清晰的模式变得至关重要。大规模ERD中的冗余不仅仅是存储浪费的问题;它还是系统性不稳定的根源。当相同的数据点被存储在多个位置而没有同步机制时,数据不一致的风险会急剧上升。
本指南探讨了在保持高吞吐量应用所需灵活性的同时,最小化冗余所需的各项技术策略。我们将研究规范化原则、结构模式和验证方法,以确保您的数据模型能够长期保持稳定。
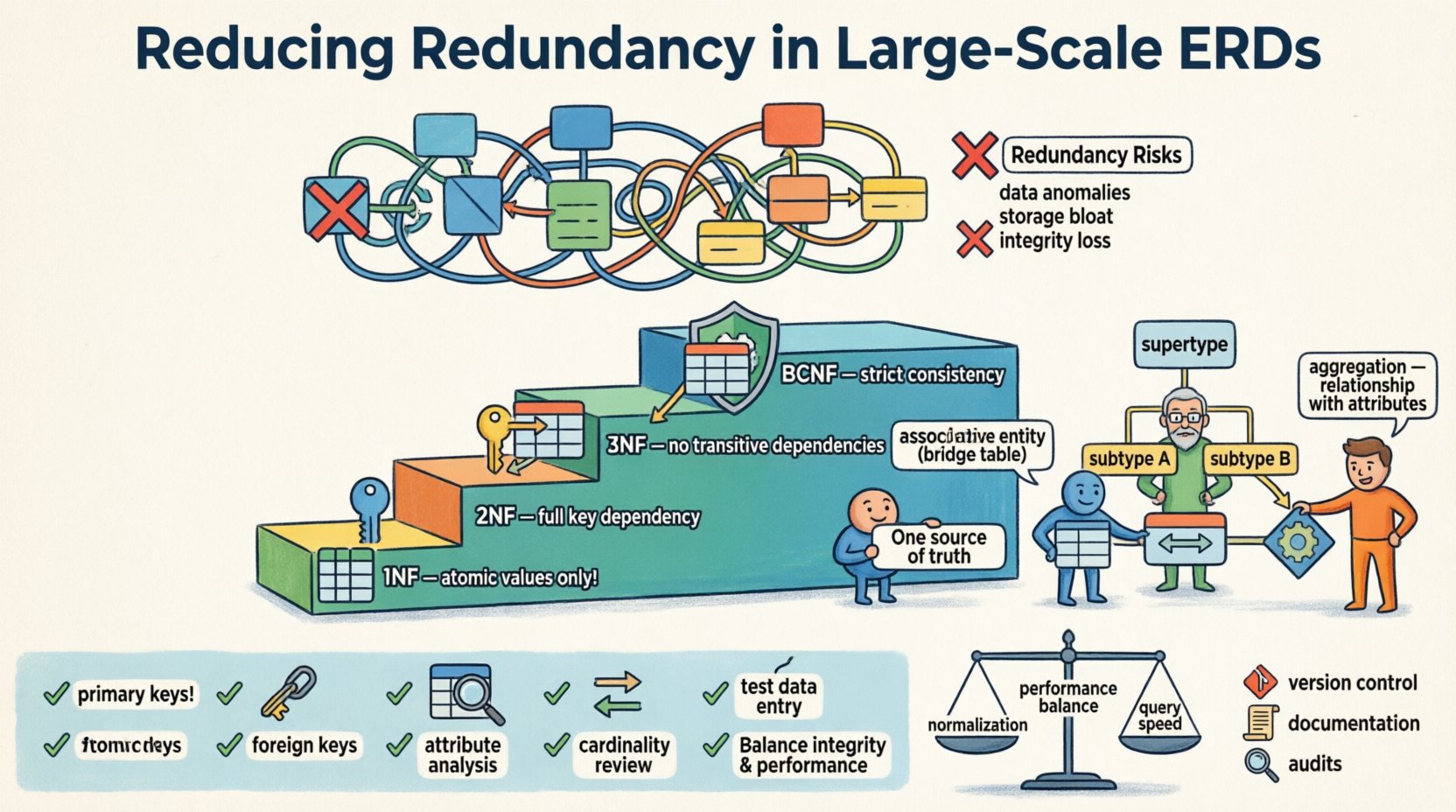
📉 数据模型中重复的代价
当同一段数据在数据库模式中被多次存储时,就会发生冗余。虽然为了性能优化,适度的反规范化是可以接受的,但不受控制的重复会引入多种风险,在大规模环境中这些风险会被显著放大。
-
数据异常:在一处更新信息而未在另一处更新,会导致记录冲突。这被称为更新异常。
-
插入问题:有时,由于其他地方缺少相关信息,你无法添加新数据。这被称为插入异常。
-
删除风险:删除一条记录可能会意外地抹去该行中冗余存储的唯一信息。这被称为删除异常。
-
存储膨胀:重复存储相同值会不必要地消耗磁盘空间和内存。
-
完整性损失:如果没有约束强制在冗余字段上保持唯一性,单一真实来源就会变得支离破碎。
在大规模图示中,这些问题会相互叠加。一个包含重复外键或描述性属性的表,就可能在维护操作期间引发级联故障。目标是在不牺牲查询效率的前提下,保持数据完整性。
🔄 理解规范化原则
规范化是通过组织数据来减少冗余并改善依赖管理的过程。它涉及将表分解为更小、结构更清晰的实体。尽管这一理论可追溯至20世纪70年代,但其原则仍是现代模式设计的基石。
第一范式(1NF)
第一步是确保原子性。每一列必须包含不可再分的值。单个单元格内包含列表违反了这一原则。例如,将多个电话号码存储在一个字段中,需要将其拆分为独立的行或相关表。
第二范式(2NF)
在满足1NF后,我们处理部分依赖问题。当一个表满足1NF且所有非键属性都完全依赖于主键时,该表即处于2NF。在复合键中,属性不应仅依赖于键的一部分。
第三范式(3NF)
这是通用事务系统中最常见的标准。当一个表处于2NF且不存在传递依赖时,该表即处于3NF。简而言之,非键属性不应依赖于其他非键属性。如果A决定B且B决定C,那么A决定C,这属于冗余,除非B是一个键。
博伊斯-科德范式(BCNF)
BCNF是3NF的更严格版本。它处理存在多个候选键和重叠依赖关系的情况。虽然并非总是必要,但它能确保最高级别的逻辑一致性。
|
形式 |
重点 |
关键要求 |
对冗余的影响 |
|---|---|---|---|
|
1NF |
原子性 |
无重复组 |
基本结构 |
|
2NF |
部分依赖 |
完全依赖于主键 |
减少拆键冗余 |
|
3NF |
传递依赖 |
非键属性仅依赖于键 |
消除属性重复 |
|
BCNF |
严格依赖 |
每个决定因子都是候选键 |
最小化复杂的重叠 |
🏛️ 适用于扩展的高级结构模式
标准规范化在事务型数据库中表现良好,但大规模系统通常需要特定模式来管理复杂性,而不会产生过多的连接。
关联实体
如果处理不当,多对多关系是冗余的主要来源。与其在两个相关表中都添加外键,不如创建一个关联表。该表仅包含外键以及与关系本身相关的任何属性。
-
优势:对关系属性的更改不需要修改父实体。
-
优势: 防止在多行之间重复关系元数据。
子类型与超类型
当实体共享共同属性但存在特定变体时,使用超类型/子类型模式可以减少属性重复。与其向仅适用于特定实例的主表添加可选列,不如为子类型创建独立的表,并通过共享主键进行关联。
-
优势: 保持主实体表的整洁。
-
优势: 允许对子类型施加特定约束,而不会影响父类型。
聚合
当关系具有属于该关系本身而非参与实体的属性时,使用聚合。在大规模ERD中,这通常表现为两个主要领域之间的汇总或事务性链接。
🧩 大型模型中的复杂性管理
随着实体数量的增加,如果管理不当,图表本身反而会成为负担。大规模ERD需要模块化策略。
逻辑模型与物理模型
将逻辑设计与物理实现分开。逻辑模型关注实体和关系,而不考虑具体的存储机制。物理模型处理索引、分区和数据类型。保持两者分离可防止物理约束迫使逻辑上出现冗余。
模块化设计
将系统划分为功能域。例如,将用户域与计费域分开。每个域保持自身的内部一致性。域之间的交互通过定义好的接口或键进行,而不是通过共享表。
处理历史数据
存储数据的历史版本可能会导致冗余。与其复制整个行,不如使用版本列或独立的审计表。这样可以保留当前状态,而不会使主实体表充斥着过去的迭代。
🛠️ 模式设计中的常见陷阱
避免冗余需要保持警惕。常见错误包括:
-
过度规范化: 将表拆分得过于细致,导致查询需要过多的连接操作,从而降低性能。有时,为了应对读取密集型工作负载,适度的冗余是合理的。
-
忽略函数依赖: 未能识别哪些属性依赖于哪些键,会导致隐藏的重复。
-
混淆关注点: 将业务逻辑属性放入数据模型中。属性应描述数据,而非流程。
-
硬编码值: 将特定的状态码或类别以字符串形式存储,而不是引用查找表。
✅ 验证与确认检查清单
在最终确定大规模ERD之前,进行严格的审查。使用此检查清单来验证您的设计。
-
识别主键: 确保每个表都有一个唯一的标识符。
-
检查外键: 验证所有关系是否通过键来强制执行,而不是通过重复数据。
-
分析属性: 询问每个非键属性是否仅依赖于键、整个键,且仅依赖于键。
-
审查基数: 确保一对多关系由一个外键表示,而不是多个。
-
测试数据输入: 模拟插入、更新和删除记录,以检查异常情况。
🔍 约束的作用
约束是设计的技术实现。唯一性约束可防止特定列中出现重复值。外键约束确保引用完整性,防止出现孤立记录。在大型系统中,约束定义应作为模式定义的一部分,而不是事后补充。
此外,应考虑使用检查约束来限制取值范围。这可以防止无效数据进入系统,从而减少后期对错误处理代码的需求。
📈 性能考量
规范化与性能之间存在权衡。高度规范化的模式需要通过连接来重构数据。在读取密集型环境中,这可能会降低响应速度。然而,为了加快读取速度而增加冗余,会导致写入变慢,因为需要更新多个位置。
现代数据库引擎能够高效处理连接操作。因此,除非性能分析表明存在特定瓶颈,否则默认应优先选择规范化。如果性能至关重要,应考虑使用物化视图或只读副本,而不是修改核心模式结构。
🔄 随时间维护模式
数据库模式会不断演变。需求会变化,新实体也会出现。为了长期保持低冗余:
-
版本控制: 将模式定义视为代码。在代码仓库中跟踪变更。
-
文档: 维护最新的文档,描述关系和依赖。
-
定期审计: 安排定期审查ERD,以识别新的冗余模式。
通过遵循这些原则,可以确保数据架构保持可扩展性。一个清晰的ERD不仅仅是美观问题;它关乎构建一个更易于理解、维护和扩展的系统,以适应业务的发展。
🎯 关于数据完整性的最终思考
减少冗余是一个持续的过程。它需要深入理解数据在系统中的流动方式以及关系之间的交互。通过应用规范化规则、利用高级结构模式并保持严格的验证协议,可以建立一个支持长期稳定性的基础。在清晰设计上投入的努力,将在降低维护成本和提高数据质量方面带来回报。
首先关注逻辑关系。让物理实现反映这种逻辑,而不是对其妥协。通过有纪律的ERD设计方法,冗余将变成一个可管理的变量,而非持续的障碍。