











在现代数据架构中,信息检索的速度往往决定了应用程序的可用性。尽管硬件升级和缓存策略起着重要作用,但性能的基础在于数据结构本身。具体而言,实体关系模型(ERMs)的设计决定了数据库引擎遍历、连接和聚合数据的效率。一个优化的模式不仅组织信息,还引导查询优化器走向更快的执行路径。 📉
本指南探讨了模式设计背后的技术机制及其与查询性能的直接关联。我们将分析规范化程度、关系基数和索引策略如何在查询执行计划中相互作用。通过理解这些动态,开发人员和数据库架构师可以构建可扩展且不牺牲完整性或速度的系统。
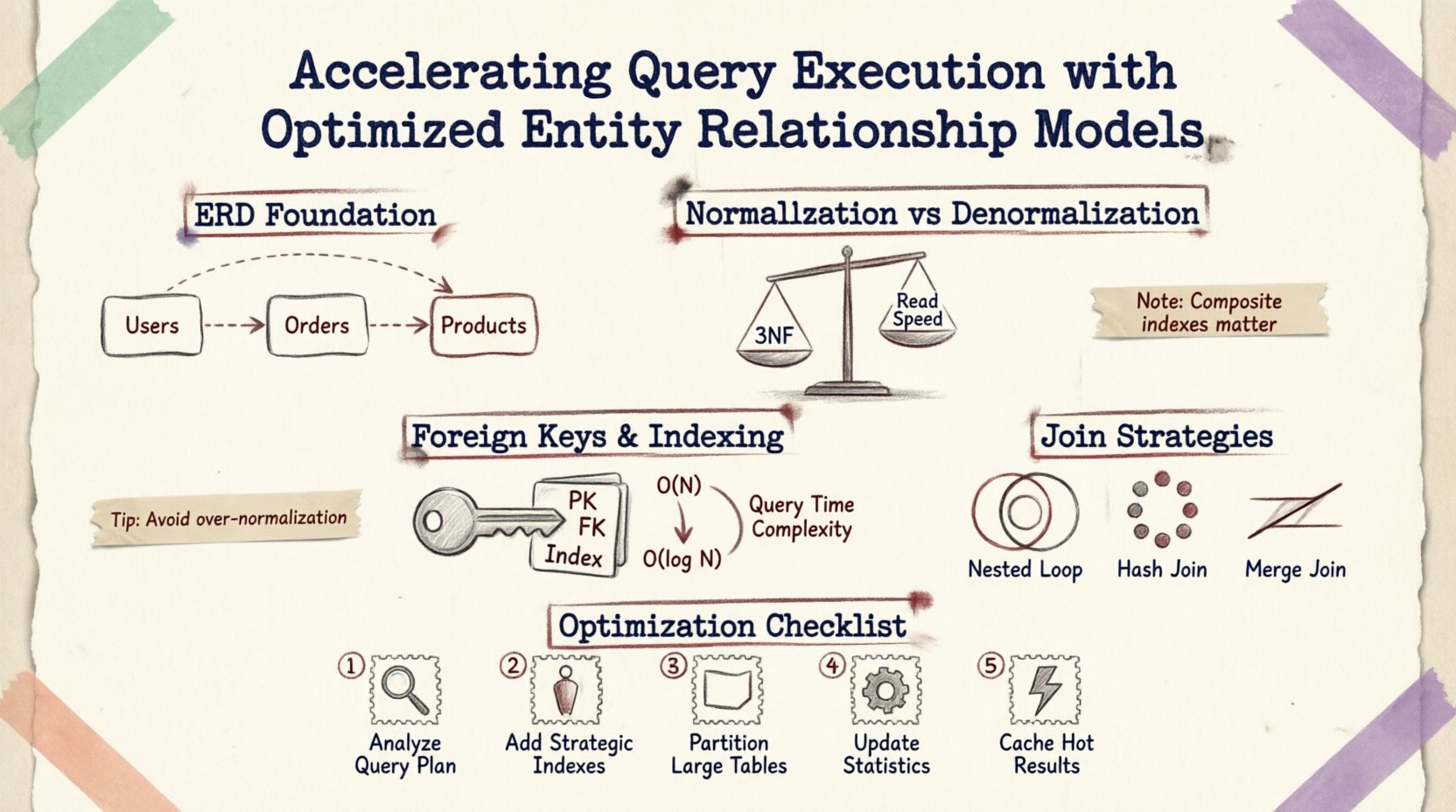
理解基础:ERD与性能 🗃️
实体关系图不仅仅是文档的视觉辅助工具;它还是物理存储和检索逻辑的蓝图。表之间绘制的每一根线条都代表一个外键约束、一次连接操作或一条数据完整性规则。当提交查询时,数据库引擎会解析这些关系以构建执行计划。
考虑一个简单的查询,请求用户订单和产品详情。引擎必须:
- 定位
Users表。 - 通过外键转向
Orders表。 - 连接
OrderItems表。 - 通过另一个关系到达
Products表。
每一步都涉及I/O操作和CPU周期。如果关系定义不佳,引擎可能会退而使用全表扫描或嵌套循环连接,导致性能呈指数级下降。优化ERD可以减少数据从磁盘到内存的传输距离。
规范化与反规范化:寻找平衡点 ⚖️
规范化是通过组织数据来减少冗余并提高完整性的一种过程。虽然这对保持一致性至关重要,但过度规范化会导致数据分散在许多小表中,需要复杂的连接操作,从而减慢读取密集型操作的速度。
深度规范化的代价
当模式被规范化到第三范式(3NF)时,数据以最原子的状态存储。这最大限度地减少了存储空间并避免了更新异常。然而,检索相关数据通常需要遍历多个外键。
- 连接开销: 连接链中的每一张额外表都会增加查询计划的复杂性。
- 锁争用: 访问多个表会增加行级锁冲突的可能性。
- CPU使用: 数据库引擎必须合并来自不同表的结果集。
何时进行反规范化
反规范化通过引入冗余来优化读取性能。这在分析处理或高流量报告环境中通常是必要的。
- 读取密集型工作负载: 如果写入操作相比读取操作较少,添加一个反规范化的列可以节省连接操作。
- 预计算聚合值: 将总计值(例如,
total_order_value)存储在用户表中,可以避免每次请求都重新计算总和。 - 水平分区: 将频繁访问的数据放在一起可以提高缓存局部性。
然而,反规范化需要仔细管理,以防止数据不一致。应用程序逻辑必须确保每当源数据发生变化时,冗余数据也得到更新。
外键与索引策略 🔑
外键约束可以保证引用完整性,但会带来性能开销。数据库必须在允许插入或更新之前验证一个表中的值是否存在于另一个表中。优化这些键的索引方式至关重要。
外键索引
默认情况下,主键会自动被索引。然而,外键通常需要显式索引来加速连接操作。如果没有在外键列上建立索引:
- 数据库必须对子表执行全表扫描以查找匹配的行。
- 连接操作会显著变慢,尤其是当表的大小增长到数百万行时。
- 删除操作期间的引用完整性检查会变得昂贵。
一个正确索引的外键可以让数据库使用索引查找而非扫描,将复杂度从 O(N) 降低到 O(log N)。
关系的复合索引
当多个列共同定义一个关系时,复合索引可能比单独的索引更有效。例如,如果查询按订单表中的 user_id 和 created_at进行筛选,那么在这两个列上建立复合索引可以确保查询引擎在不扫描无关记录的情况下定位数据。
连接策略与执行计划 🔍
ERD 的结构会影响查询优化器选择的连接算法。理解这些机制有助于设计出更倾向于高效连接类型的模式。
| 连接类型 | 最适合使用的情况 | 性能影响 |
|---|---|---|
| 嵌套循环连接 | 较小的结果集或高度选择性的谓词 | 小数据量时快速;大数据扫描时缓慢 |
| 哈希连接 | 没有索引的大表 | 内存消耗大;适用于未排序的数据 |
| 合并连接 | 连接键上的已排序输入 | 如果数据已排序,则非常快速 |
设计ERD以支持已排序的输入或索引查找,可以促使优化器选择更快的连接方法。例如,确保连接键作为聚集索引的一部分,有助于实现合并连接。
模式设计中的常见陷阱 🚫
即使是经验丰富的架构师也会犯影响查询速度的错误。及早识别这些模式可以避免后期昂贵的重构。
- 链式外键:创建一个关系链,其中表A连接到B,B连接到C,C连接到D。连接这四个表的查询会变得深度嵌套且缓慢。
- 可变长度字符串: 使用
VARCHAR用于始终为固定长度的键,会浪费空间并减慢行比较速度。 - 多对多关系缺少关联表:试图在一个列中存储多个ID(例如,用逗号分隔的值)会阻止正确的索引和规范化。
- 隐式转换:在父表和子表之间定义不匹配的数据类型,会迫使引擎在运行时转换值,从而阻止索引的使用。
优化的实用步骤 🛠️
为了在不重写整个系统的情况下提升查询执行效率,请遵循以下结构化步骤:
- 分析查询模式:审查最频繁的读取操作。识别哪些表被最常连接。
- 审查索引使用情况:检查外键或频繁过滤的列上是否缺少索引。
- 优化基数:确保关系被准确建模(一对一与一对多)。错误的基数可能导致不必要的连接。
- 对大表进行分区: 如果表中的数据行数超过百万,建议按日期或区域进行分区,以限制每次查询扫描的数据量。
- 监控锁机制: 使用监控工具识别长时间运行且持有锁的查询,这通常是由模式遍历效率低下引起的。
存储与内存考虑 💾
数据的物理布局也起着重要作用。数据库引擎将数据存储在页中。如果相关行在物理上存储得较近,则加载数据集所需的磁盘读取次数会更少。
- 聚集: 按共同键组织数据可以提升范围扫描的性能。
- 列式存储与行式存储: 对于分析型查询,列式存储可能比传统的基于行的模型提供更好的压缩效果和更快的聚合速度。
- 缓存: 设计能够有效缓存整个结果集而非单个行的模式。
关于模式演化的最后思考 🔄
模式设计不是一次性的任务。随着应用需求的变化,数据模型必须随之演进。定期审查数据库结构可确保性能保持稳定。应与代码库一同维护实体关系模型的文档,以追踪变更对系统的影响。
通过关注数据内部的结构完整性和逻辑关系,您将建立起支持高速查询执行的基础。目标不是构建一个静态系统,而是一个能够适应负载变化且不牺牲用户期望速度的灵活架构。📊
优化实体关系模型是一门融合数据库理论与实际工程的技术学科。它需要耐心、分析能力,以及对底层引擎如何处理请求的清晰理解。采用正确的方法,性能问题将变得可控,数据检索也将变得无缝。