











随着数据积累的加速,数据库模式的架构成为系统稳定性的关键决定因素。当应用程序从读取密集型操作转向写入密集型工作负载时,标准的实体关系图(ERD)通常需要重大调整。为实现高吞吐量而进行设计,不仅仅是添加索引那么简单;它要求从根本上重新思考数据的结构、关联和存储方式。本指南探讨了在压力下保持性能而不损害数据完整性的必要架构转变。
理解写入密集型工作负载 📈
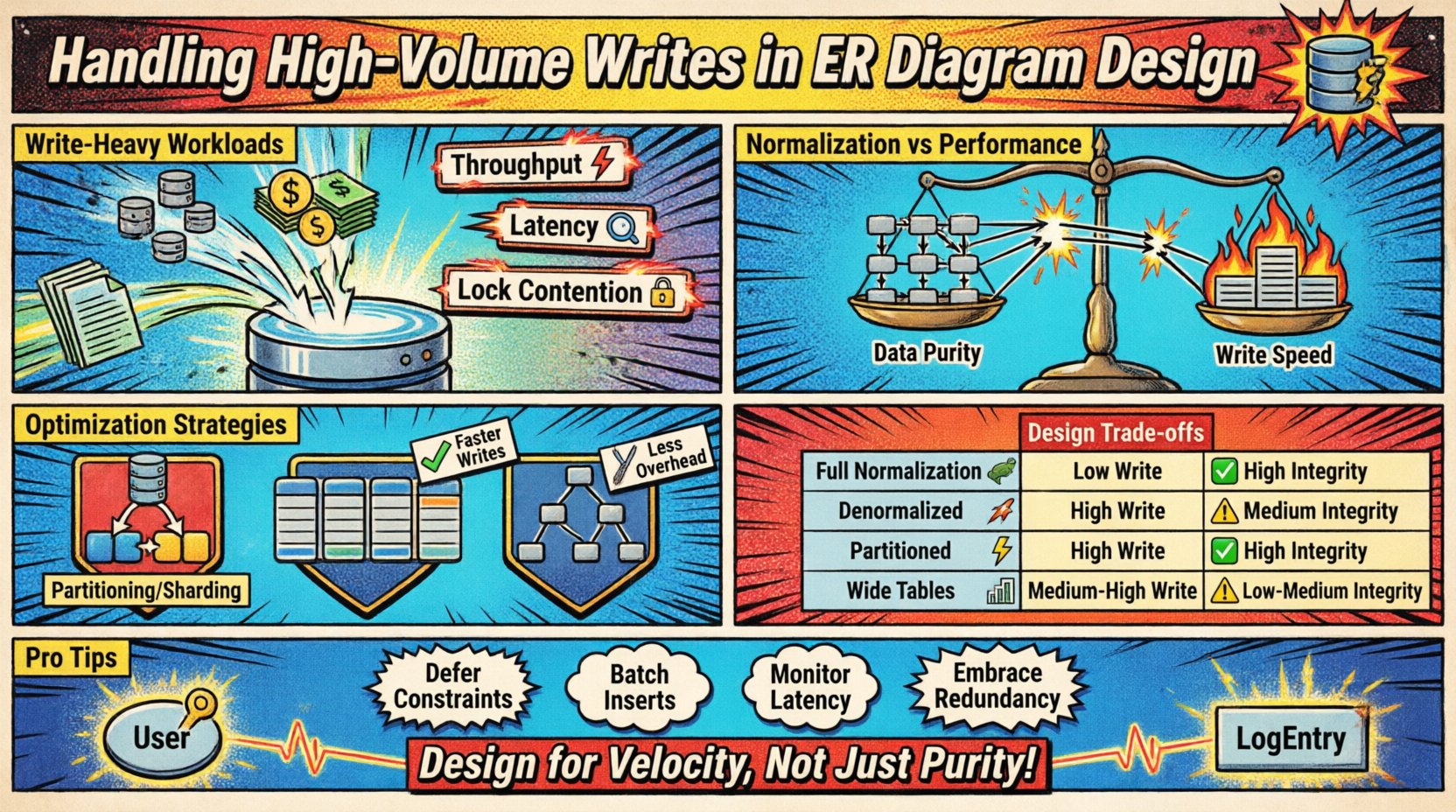
当传入数据的速率超过标准规范化技术的处理能力时,就会出现高吞吐量写入场景。这种情况通常发生在日志系统、物联网传感器数据流、金融交易账本或实时分析平台中。主要挑战在于在插入速度与模型的一致性要求之间取得平衡。
- 吞吐量: 每秒处理的写入操作数量。
- 延迟: 成功持久化一条记录所需的时间。
- 锁竞争: 当多个进程尝试修改同一数据时,对资源的竞争。
当这些指标下降时,模式本身往往是瓶颈。一个为复杂查询优化的僵化设计,在持续更新的压力下可能崩溃。因此,初始的ERD必须考虑数据输入的速度。
规范化与性能权衡 ⚖️
传统的数据库设计鼓励规范化(1NF、2NF、3NF)以减少冗余。虽然这节省了存储空间并确保了一致性,但在写入操作期间会引入开销。每个外键关系都需要一次查找和一次连接检查,以维护引用完整性。
在高吞吐量环境中,这些检查变得代价高昂。考虑在写入事件中多对多关系的影响:
- 主表必须更新。
- 关联表必须插入一条新记录。
- 第二个表必须验证该关系。
- 事务日志必须记录所有更改。
每一步都会增加磁盘I/O和CPU周期。为了应对高写入负载,设计者通常会放宽规范化规则。这一过程涉及接受数据冗余,以减少存储单个信息单元所需的写入操作次数。
优化写入速度的策略 ✍️
存在多种结构模式可用于缓解写入压力。这些策略专注于最小化每次事务的开销,并降低存储引擎的工作复杂度。
1. 分区与分片
将大表拆分为更小、更易管理的块,可以使数据库将写入负载分布在多个物理或逻辑段上。
- 水平分区: 根据某个键(例如,日期范围、用户ID)划分行。
- 垂直分区: 将访问频率较低的列移至独立的表中。
- 分片: 将数据分布在多个数据库实例上。
这种方法减少了必须维护的索引大小,并限制了写入操作期间锁的范围。如果一个分片变得饱和,其他分片仍不受影响。
2. 反规范化策略
存储冗余数据可使系统在写入时避免连接操作。例如,每当新交易到达时,系统无需每次都从相关行计算总和,而是可以直接更新预先计算好的汇总列。
- 计算列: 将派生值直接存储在行中。
- 物化视图: 为频繁的聚合操作预先计算结果。
- 缓存计数器: 为统计信息维护一个独立的计数器表。
虽然这会增加存储需求,但能显著降低插入操作的CPU开销。
3. 索引策略
索引能加快读取速度,但会减慢写入速度。每次插入一行数据时,数据库都必须更新所有相关的索引。在高写入环境中,索引膨胀会成为一个主要问题。
- 最小化索引数量: 仅对用于过滤或连接的列创建索引。
- 部分索引: 仅对经常访问的行子集创建索引。
- 避免过度索引: 对频繁变更的列跳过索引。
比较设计方法 📑
下表概述了不同结构选择对写入性能和数据完整性的影响。
| 策略 | 写入性能 | 数据完整性 | 存储成本 | 最佳使用场景 |
|---|---|---|---|---|
| 完全规范化 | 低 | 高 | 低 | 复杂报表,低写入量 |
| 反规范化 | 高 | 中等 | 高 | 实时数据流,高写入量 |
| 分区模式 | 高 | 高 | 中等 | 时序数据,大型数据集 |
| 宽表 | 中高 | 中等 | 中等 | NoSQL 模式,稀疏数据 |
处理外键和约束 🔗
参照完整性是关系型设计的基石,但在每次插入时强制执行约束可能会堵塞高速数据管道。数据库引擎必须在接受子行之前验证所引用的父行是否存在。
在数据完整性至关重要但写入速度优先的情况下,可考虑以下调整:
- 延迟约束:在事务结束时验证关系,而不是立即验证。
- 应用层检查:在将数据发送到数据库之前,在应用代码中验证关系。
- 软删除:将记录标记为非活跃状态,而不是删除它们,以保留引用链接且避免删除开销。
完全移除约束存在风险,但将验证逻辑转移有时可以提高吞吐量。这一决策取决于您的特定工作流程中即时一致性的重要性。
写入放大与存储引擎 💾
理解存储引擎如何处理数据至关重要。许多引擎使用预写日志(WAL)来确保持久性。这意味着每次写入都会先被记录,然后再应用到实际的数据文件中。
写入放大当一次逻辑写入操作导致多次物理写入时就会发生写入放大。这在压缩密集型存储引擎中很常见。为管理这种情况:
- 批量插入:将多行数据合并为一个事务。
- 顺序写入: 设计模式时应优先考虑顺序键生成,而非随机插入。
- 缓冲: 允许在应用层使用临时缓冲区,在刷新前排队写入操作。
通过将ERD设计与存储引擎的优势对齐,可以最大限度地减少持久化数据所需的物理开销。
监控与迭代 🔄
针对高写入量设计的模式并非一成不变。随着流量模式的变化,设计可能需要演进。持续监控写入延迟和磁盘I/O至关重要。
- 跟踪写入延迟: 识别表明瓶颈的峰值。
- 监控锁等待: 检测进程被阻塞的争用点。
- 分析索引使用情况: 删除从未使用的索引,以减少写入开销。
定期审查ERD可确保结构与当前运营需求保持一致。如果某个特定表持续面临写入吞吐量问题,可能需要重新审视分区策略或规范化程度。
关键考虑因素总结 🛠️
针对高吞吐量写入设计ERD需要从纯粹的数据纯净性思维转向系统吞吐量思维。以下要点总结了必要的行动:
- 审查规范化: 确保每个关系都带来价值,而不仅仅是增加复杂性。
- 规划分区: 设计键以支持轻松的水平拆分。
- 限制索引: 尽可能保持写入路径简洁。
- 接受冗余: 使用反规范化来减少插入时的连接依赖。
- 逐步验证: 在安全的前提下,将约束检查移出关键写入路径。
通过应用这些原则,你可以构建一个能够在不牺牲性能的前提下持续支持增长的数据模型。目标不是消除复杂性,而是以一种支持应用程序速度的方式进行管理。