











实体关系图(ERD)是数据库架构的蓝图。它们定义了数据在系统中如何被结构化、存储和检索。当这些图表存在缺陷时,其后果远远超出开发阶段。生产环境中的错误可能导致数据损坏、性能瓶颈以及重大财务损失。了解常见陷阱对于维护系统完整性至关重要。
许多团队在建模阶段急于求成,优先考虑速度而非精确性。这种急躁常常导致一旦数据开始流动便难以解决的模式问题。一个稳健的设计需要仔细考虑关系、数据类型和约束条件。以下我们将探讨最常见的设计缺陷及其技术影响。
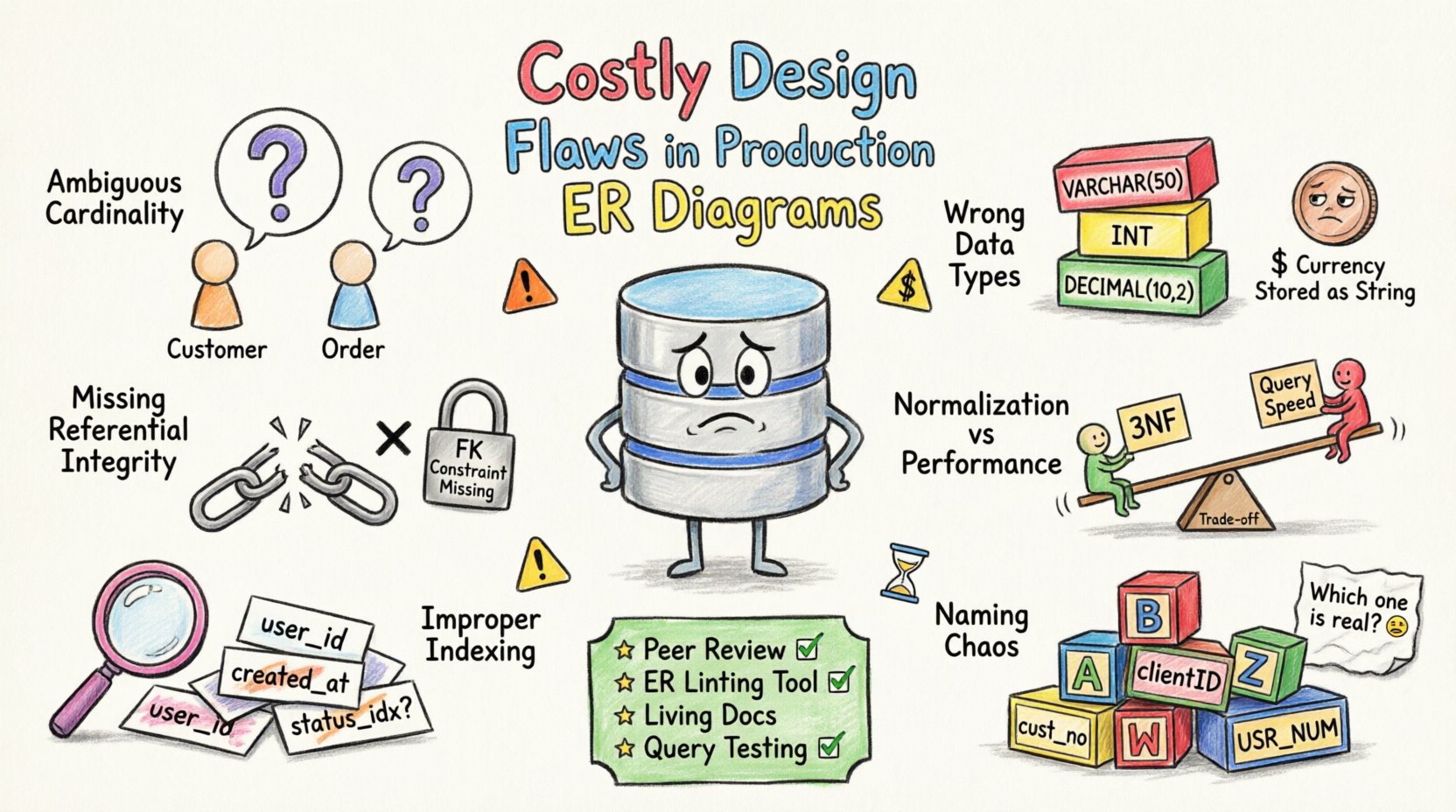
1. 模糊的基数关系与关联 🔗
基数定义了实体之间的数量关系。错误的基数会导致数据检索和存储中的逻辑错误。一个常见错误是,在实际存在一对多关系的情况下,却假设为一对一关系。
- 多对多关系遗漏: 未为多对多关系创建关联表,会导致数据重复或产生复杂的连接查询。
- 未定义外键: 若未显式定义外键,数据库将无法强制实施参照完整性,从而允许出现孤立记录。
- 可选与必选: 将必需的关系错误地分类为可选关系,会在预期有数据的地方引入空值。
例如,考虑客户与订单的关系。如果图表暗示客户可以没有订单,但应用程序逻辑却要求必须有订单,数据库将存储不完整的用户资料。这种不一致会导致应用程序崩溃或报告结果不一致。
2. 数据类型选择不一致 📊
数据类型决定了信息如何被存储和处理。选择错误的数据类型会消耗不必要的存储空间,或限制数值范围。当使用浮点数表示货币时,精度问题尤为常见。
- 整数溢出: 使用小整数作为标识符,随着数据集的增长可能导致溢出错误。
- 文本长度: 使用固定长度的字符字段会浪费可变长度数据的空间。
- 日期精度: 在不包含时区信息的情况下存储日期,会在分布式系统中引发同步问题。
为电话号码选择通用的文本字段是另一个常见错误。这会导致无效字符进入系统,使后续的验证逻辑变得复杂。数值字段应仅用于计算,文本字段仅用于字母数字数据。
3. 缺失参照完整性约束 🔒
参照完整性确保表之间的关系保持一致。若缺少这些约束,数据库将依赖应用程序代码来维护数据准确性,而这容易受到人为错误的影响。
- 无级联规则: 在没有级联规则的情况下删除父记录,会导致子记录在数据库中悬空。
- 缺失约束: 仅依赖应用程序级别的验证而忽视数据库约束是不够的。
- 软删除: 对已删除记录处理不当会造成数据杂乱,并降低查询性能。
当约束缺失时,数据完整性完全依赖于应用程序开发人员。如果存在漏洞允许直接写入数据库,不一致状态将变得永久化。这是长期运行的生产系统中数据损坏的主要原因。
4. 规范化与性能权衡 ⚖️
规范化减少了冗余,但可能增加查询复杂性。过度规范化会导致过多的连接操作,而规范化不足则会产生更新异常。找到平衡点对性能至关重要。
- 第三范式(3NF):通常适用于事务性系统,但对于读取密集型工作负载可能需要去规范化。
- 去规范化:为提升性能而引入冗余必须进行文档记录,以防止更新冲突。
- 查询复杂性:高度规范化的模式需要复杂的连接操作,会给数据库引擎带来压力。
团队常常过度规范化以确保数据纯净,却忽视了连接多个表所带来的开销。在高流量环境中,这会导致响应时间变慢。只要正确管理写操作,有策略地去规范化可以提升读取性能。
5. 不当的索引策略 🏷️
索引能加快数据检索速度,但会减慢写入操作。有缺陷的ERD通常未能考虑数据将如何被查询,这会导致全表扫描和高延迟。
- 缺少外键索引:在未建立索引的列上进行连接操作计算成本很高。
- 过度索引:索引过多会增加写入延迟和存储需求。
- 复合索引顺序:复合索引中列的顺序错误会使索引失效。
在频繁查询的列上建立索引是标准做法。然而,在设计阶段忽视查询模式会导致访问路径低效。必须定期审查查询执行计划,以调整索引策略。
6. 命名规范混乱 🏷️
一致的命名规范对可维护性至关重要。表名和列名不一致会使模式难以理解与修改。
- 大小写混用:在某些地方使用驼峰命名法,而在其他地方使用下划线命名法会造成混淆。
- 模糊的缩写:像“cust”或“ord”这样的简短名称对新成员来说缺乏清晰性。
- 保留关键字:将保留字用作表名会导致查询中的语法错误。
清晰的命名可以减轻开发人员和数据库管理员的认知负担。它还有助于自动生成文档,并减少SQL语句中拼写错误的可能性。
常见缺陷的影响分析
| 设计缺陷 | 技术影响 | 业务成本 |
|---|---|---|
| 缺少外键 | 孤立记录,数据不一致 | 数据丢失,合规性违规 |
| 数据类型错误 | 存储浪费,计算错误 | 财务差异,报告错误 |
| 过度规范化 | 查询性能慢,高延迟 | 用户体验缓慢,收入损失 |
| 缺少索引 | 全表扫描,数据库锁争用 | 系统停机,可扩展性差 |
| 命名不佳 | 维护开销高,错误率高 | 开发时间增加,缺陷增多 |
预防策略 🛡️
防止这些缺陷需要对数据库设计采取严谨的方法。以下步骤有助于在部署前降低风险。
- 同行评审: 在任何更改合并之前,实施强制性的模式审查。
- 自动化代码检查: 使用工具检查命名规范和结构标准。
- 文档: 保持更新的ERD图,以反映实际的模式。
- 测试: 在生产环境之前,在预发布环境中运行模式验证测试。
采用数据库模式的版本控制流程,可确保变更被追踪且可逆。这使团队能够识别缺陷引入的时间点,并在必要时回滚。开发人员与架构师之间的协作对于尽早发现问题是至关重要的。
长期维护考虑 🔄
数据库模式会随时间演变。今天有效的设计可能无法满足未来的需求。定期审计有助于识别技术债务和过时的模式。
- 模式漂移: 监控ERD与实时数据库之间的差异。
- 弃用: 规划删除未使用的表和列。
- 可扩展性: 在设计大型数据集时,需考虑分片和分区分区。
忽视维护会导致系统脆弱且抗拒变更。主动管理可确保数据库始终是应用程序的可靠基础。在初始设计上投入时间,将在软件生命周期的各个阶段带来回报。
关于模式完整性的最后思考 📝
生产数据库错误通常是设计阶段被忽略的细节所致。通过解决基数、数据类型、约束和索引问题,团队可以构建更具弹性的系统。在生产环境中修复缺陷的成本远高于在建模阶段预防。
专注于清晰性、一致性和验证。结构良好的ERD是数据可靠性的核心。应优先考虑质量而非速度,以确保长期稳定。这种方法可最大限度降低风险,并最大化系统内存储数据的价值。