











In the architecture of relational systems, the tension between data integrity and performance is constant. Entity Relationship Diagrams (ERDs) serve as the blueprint for this structure, defining how tables connect. While foreign keys ensure that relationships remain valid, they introduce overhead that can bottleneck throughput. Understanding how to tune these constraints is essential for systems handling high-volume transactions. This guide explores the mechanics of optimizing foreign keys to maintain consistency without sacrificing speed. ⚡
Understanding the Cost of Integrity Enforcement 🛡️
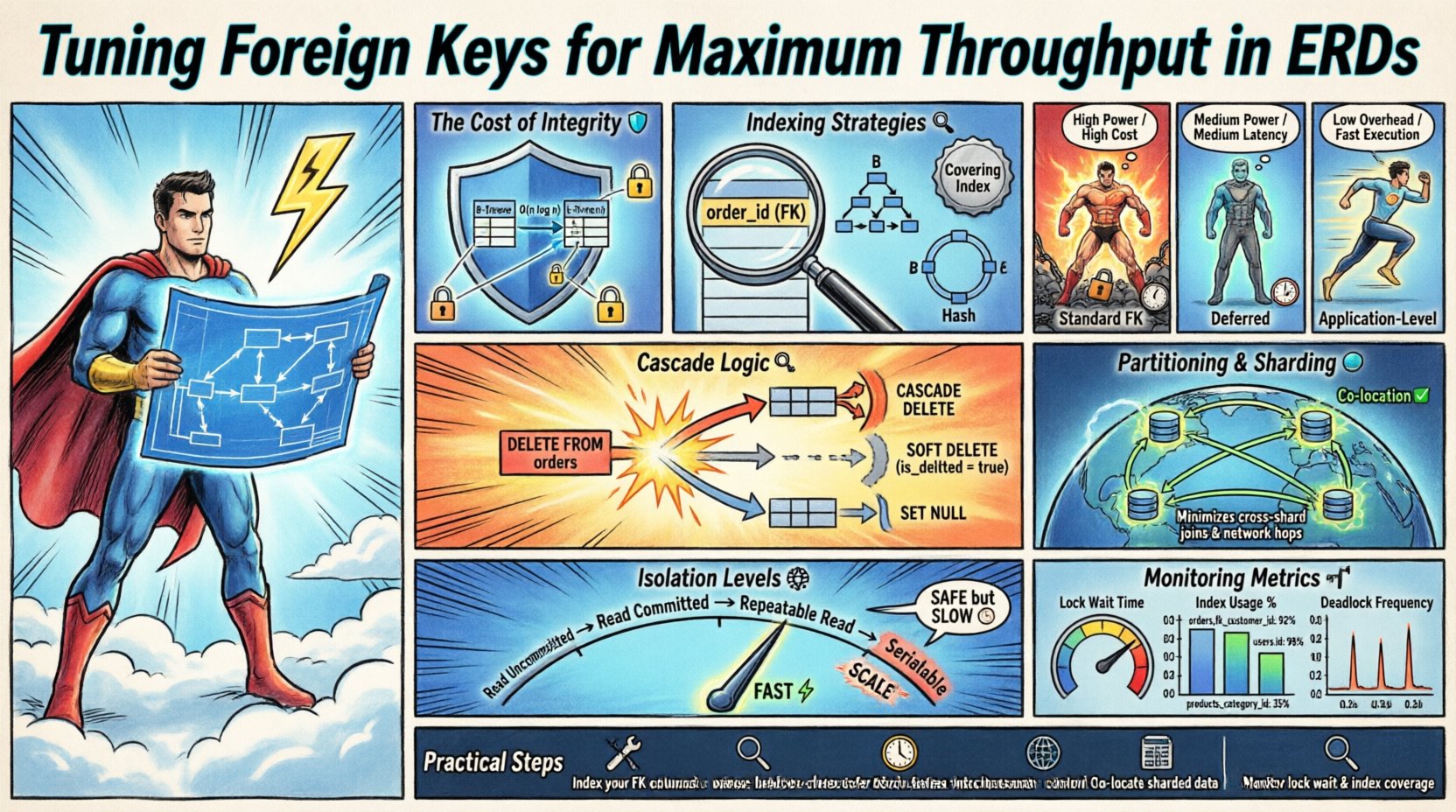
Foreign keys are not merely labels; they are active rules enforced by the database engine. Every insert, update, or delete operation involving a foreign key triggers validation logic. This logic checks the parent table to ensure the referenced value exists. In high-throughput environments, this check becomes a significant cost.
The validation process typically involves:
- Lookup Operations: The system must search the parent table for the referenced ID.
- Locking Mechanisms: The parent row often requires a lock to prevent concurrent modification during the check.
- Index Traversal: Without proper indexing, the engine scans large portions of the parent table.
When millions of transactions occur per second, these micro-delays accumulate. The goal is not to remove integrity, but to streamline the verification process. Consider the following scenarios where this overhead impacts performance:
- Batch Imports: Loading historical data often requires disabling constraints temporarily.
- High-Frequency Writes: Systems logging events or sensor data may prioritize speed over immediate consistency.
- Cascade Operations: Deleting a parent record may trigger updates across multiple child tables.
Indexing Strategies for Foreign Keys 🔍
Indexing is the most direct lever for improving foreign key performance. The child table must have an index on the foreign key column to avoid full table scans during updates. If the index is missing, the database must traverse the entire parent table to validate the relationship.
Key indexing considerations include:
- Column Order: If the foreign key is part of a composite index, its position matters for query planning.
- Storage Engine: Different storage layers handle indexes differently. B-Tree structures are common, but Hash indexes may offer faster lookups for equality checks.
- Covering Indexes: Including the foreign key in the index allows the engine to retrieve data without accessing the heap.
A common mistake is assuming the primary key is sufficient. If the foreign key column is frequently queried or updated, it requires its own dedicated index. This ensures that the validation step does not become a sequential scan.
Constraint Types and Their Impact 📊
Not all foreign keys behave the same way. The definition of the constraint determines the locking behavior and the extent of the check. Selecting the right constraint type is a critical design decision.
Compare the following constraint behaviors:
| Constraint Type | Write Impact | Read Impact | Use Case |
|---|---|---|---|
| Standard FK | High (Locks Parent) | Low | Core Transactional Data |
| Deferred | Medium (Check at Commit) | Low | Bulk Loads / Batch Jobs |
| Without Index | Medium (Scans Parent) | Medium | One-to-Many with Rare Updates |
| Application-Level | Low (No DB Locks) | Low | High Velocity Logging |
Deferred constraint checking allows the database to skip validation during the transaction and perform it only at commit time. This reduces the duration of locks held on the parent table. It is particularly useful when multiple rows in the child table reference the same parent, or when the parent row might be created within the same transaction.
Write Amplification and Cascade Logic 🔄
Cascade operations are powerful tools for maintaining data hygiene, but they introduce write amplification. When a parent record is deleted, the system must locate and delete every associated child record. This multiplies the I/O operations required.
Strategies to mitigate this include:
- Soft Deletes: Instead of physically removing records, mark them as inactive. This avoids the cascade chain entirely.
- Set Null: If the relationship is optional, setting the foreign key to NULL is faster than deleting child rows.
- Restrict: Prevent deletion if children exist. This forces the application to handle cleanup in a controlled manner.
In distributed systems, cascade deletes can cause latency spikes. A single parent deletion might trigger thousands of child updates across different shards. It is often better to handle cleanup asynchronously using background jobs.
Partitioning and Sharding Considerations 🌐
As data scales, single-table performance degrades. Partitioning splits large tables into manageable chunks. Foreign keys complicate this process because the relationship must span partitions.
Challenges in partitioned environments include:
- Cross-Partition Locks: If the parent and child tables are partitioned differently, the engine must coordinate locks across partitions.
- Routing Overhead: Queries must determine which partition holds the referenced data.
- Sharding Keys: The foreign key column should ideally be the sharding key to co-locate related data.
If the foreign key is not the sharding key, the system must route queries to the correct shard for validation. This network latency adds up. Co-locating parent and child records on the same node minimizes this overhead.
Transaction Isolation Levels and Throughput 🧩
The isolation level defines how transactions interact with each other. Higher isolation levels provide stronger consistency but increase contention. Foreign keys interact directly with locking mechanisms defined by isolation levels.
Common isolation impacts:
- Read Committed: Allows dirty reads. Foreign key checks might see uncommitted data from other transactions, potentially leading to race conditions.
- Repeatable Read: Locks the parent row for the duration of the transaction. This prevents phantom reads but reduces concurrency.
- Serializable: Provides the highest safety. Foreign keys are strictly enforced, but throughput drops significantly due to serialization.
Selecting the lowest isolation level that satisfies your business logic is a standard optimization technique. If your application can tolerate eventual consistency, lowering the isolation level can drastically improve write throughput.
Monitoring and Maintenance Metrics 📈
Optimization is an ongoing process. You must monitor specific metrics to identify bottlenecks related to foreign keys.
Key metrics to track:
- Lock Wait Time: High values indicate contention on parent tables.
- Index Usage: Unused indexes waste storage and slow down writes.
- Deadlock Frequency: Foreign keys are a common cause of deadlocks in concurrent systems.
- Query Execution Time: Slow inserts often point to missing indexes on foreign key columns.
Regular audits of the ERD against actual query patterns ensure that the design matches the workload. A schema designed for read-heavy access may differ from one designed for write-heavy access.
Practical Implementation Steps 🛠️
Implementing these optimizations requires a structured approach. Follow these steps to tune your environment:
- Profile Current Workloads: Identify which tables generate the most foreign key violations or locks.
- Analyze Query Plans: Ensure foreign key columns are covered by indexes.
- Review Cascade Rules: Determine if hard deletes are necessary or if soft deletes suffice.
- Test Concurrency: Simulate high-volume writes to measure lock contention.
- Refine Constraints: Switch from ON DELETE CASCADE to application-level cleanup where appropriate.
By systematically addressing these areas, you reduce the friction between data integrity and system speed. The result is a robust architecture capable of handling scale without compromising reliability.