











In modern data architectures, the speed at which information is retrieved often determines the usability of an application. While hardware upgrades and caching strategies play significant roles, the foundation of performance lies in the data structure itself. Specifically, the design of Entity Relationship Models (ERMs) dictates how efficiently a database engine can traverse, join, and aggregate data. An optimized schema does not merely organize information; it guides the query optimizer toward faster execution paths. 📉
This guide explores the technical mechanics behind schema design and its direct correlation to query performance. We will examine how normalization levels, relationship cardinality, and indexing strategies interact within the query execution plan. By understanding these dynamics, developers and database architects can build systems that scale without compromising integrity or speed.
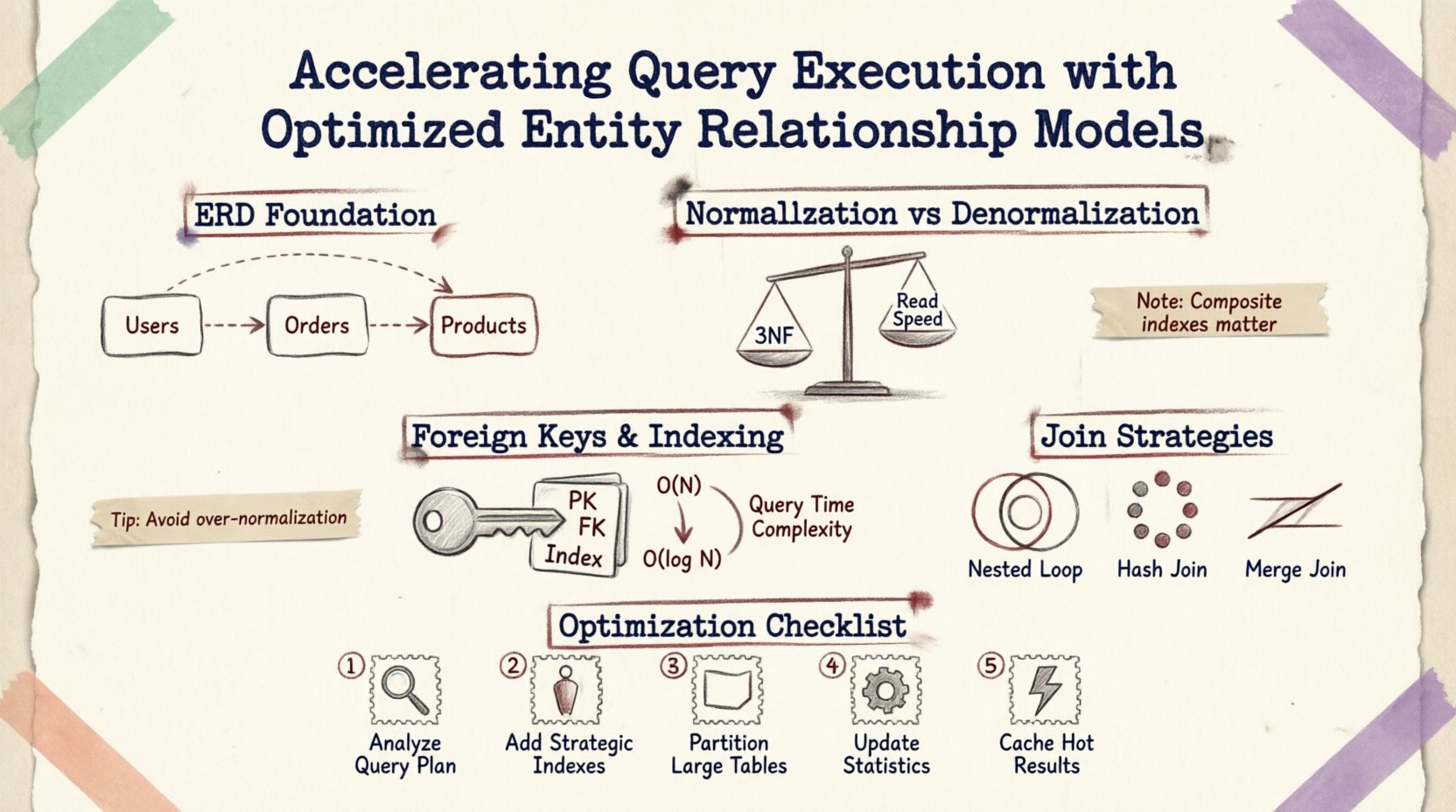
Understanding the Foundation: ERDs and Performance 🗃️
An Entity Relationship Diagram is more than a visual aid for documentation; it is a blueprint for physical storage and retrieval logic. Every line drawn between tables represents a foreign key constraint, a join operation, or a data integrity rule. When a query is submitted, the database engine interprets these relationships to construct an execution plan.
Consider a simple query requesting user orders and product details. The engine must:
- Locate the
Userstable. - Follow the foreign key to the
Orderstable. - Join the
OrderItemstable. - Reach the
Productstable via another relationship.
Each step involves I/O operations and CPU cycles. If the relationships are poorly defined, the engine may resort to full table scans or nested loop joins that degrade performance exponentially. Optimizing the ERD reduces the distance data must travel from disk to memory.
Normalization vs. Denormalization: Finding the Balance ⚖️
Normalization is the process of organizing data to reduce redundancy and improve integrity. While essential for consistency, excessive normalization can fragment data across many small tables, requiring complex joins that slow down read-heavy operations.
The Cost of Deep Normalization
When a schema is normalized to the Third Normal Form (3NF), data is stored in its most atomic state. This minimizes storage space and update anomalies. However, retrieving related data often requires traversing multiple foreign keys.
- Join Overhead: Every additional table in a join chain increases the complexity of the query plan.
- Lock Contention: Accessing multiple tables increases the likelihood of row-level locking conflicts.
- CPU Usage: The database engine must merge result sets from disparate tables.
When to Denormalize
Denormalization introduces redundancy to optimize read performance. This is often necessary in analytical processing or high-traffic reporting environments.
- Read-Heavy Workloads: If writes are infrequent compared to reads, adding a denormalized column saves join operations.
- Pre-computed Aggregates: Storing totals (e.g.,
total_order_value) in the user table avoids calculating sums on every request. - Horizontal Partitioning: Keeping frequently accessed data together improves cache locality.
However, denormalization requires careful management to prevent data inconsistency. Application logic must ensure that redundant data is updated whenever the source data changes.
Foreign Keys and Indexing Strategy 🔑
Foreign key constraints enforce referential integrity, but they come with a performance cost. The database must verify that a value in one table exists in another before allowing an insert or update. Optimizing how these keys are indexed is critical.
Indexing Foreign Keys
By default, primary keys are automatically indexed. Foreign keys, however, often require explicit indexes to speed up join operations. Without an index on a foreign key column:
- The database must perform a full table scan of the child table to find matching rows.
- Join operations become significantly slower, especially as table sizes grow into millions of rows.
- Referential integrity checks during deletion become expensive.
A properly indexed foreign key allows the database to use an index seek instead of a scan, reducing complexity from O(N) to O(log N).
Composite Indexes for Relationships
When multiple columns define a relationship, a composite index can be more effective than individual indexes. For example, if a query filters by user_id and created_at within an order table, a composite index on both columns ensures the engine can locate the data without scanning unrelated records.
Join Strategies and Execution Plans 🔍
The structure of the ERD influences which join algorithms the query optimizer selects. Understanding these mechanics helps in designing schemas that favor efficient join types.
| Join Type | Best Used When | Performance Impact |
|---|---|---|
| Nested Loop Join | Small result sets or highly selective predicates | Fast for small data; slow for large scans |
| Hash Join | Large tables without indexes | Memory intensive; good for unsorted data |
| Merge Join | Sorted inputs on join keys | Very fast if data is already sorted |
Designing the ERD to support sorted inputs or indexed lookups can encourage the optimizer to choose faster join methods. For instance, ensuring that join keys are defined as part of a clustered index can facilitate Merge Joins.
Common Pitfalls in Schema Design 🚫
Even experienced architects make mistakes that impact query speed. Identifying these patterns early prevents costly refactoring later.
- Chained Foreign Keys: Creating a chain of relationships where Table A links to B, B links to C, and C links to D. Queries joining all four tables become deeply nested and slow.
- Variable Length Strings: Using
VARCHARfor keys that are always fixed length can waste space and slow down row comparisons. - Many-to-Many without Junction Tables: Attempting to store multiple IDs in a single column (e.g., comma-separated values) prevents proper indexing and normalization.
- Implicit Conversions: Defining data types that do not match between parent and child tables forces the engine to convert values at runtime, preventing index usage.
Practical Steps for Optimization 🛠️
To improve query execution without rewriting the entire system, follow these structured steps:
- Analyze Query Patterns: Review the most frequent read operations. Identify which tables are joined most often.
- Review Index Usage: Check for missing indexes on foreign keys or frequently filtered columns.
- Refine Cardinality: Ensure relationships are accurately modeled (One-to-One vs. One-to-Many). Incorrect cardinality can lead to unnecessary joins.
- Partition Large Tables: If a table exceeds millions of rows, consider partitioning by date or region to limit the data scanned per query.
- Monitor Locking: Use monitoring tools to identify long-running queries that hold locks, often caused by inefficient schema traversal.
Storage and Memory Considerations 💾
The physical layout of data also plays a role. Database engines store data in pages. If related rows are stored physically close together, fewer disk reads are required to load a dataset.
- Clustering: Organizing data by a common key can improve range scans.
- Column Store vs. Row Store: For analytical queries, columnar storage may offer better compression and faster aggregation than traditional row-based models.
- Caching: Design schemas that allow for effective caching of entire result sets rather than individual rows.
Final Thoughts on Schema Evolution 🔄
Schema design is not a one-time task. As application requirements change, the data model must evolve. Regularly auditing the database structure ensures that performance remains consistent. Documentation of the Entity Relationship Model should be maintained alongside the codebase to track how changes impact the system.
By focusing on the structural integrity and logical relationships within the data, you create a foundation that supports high-speed query execution. The goal is not to build a static system, but a flexible architecture that adapts to load without sacrificing the speed users expect. 📊
Optimizing the Entity Relationship Model is a technical discipline that blends database theory with practical engineering. It requires patience, analysis, and a clear understanding of how the underlying engine processes requests. With the right approach, performance issues become manageable, and data retrieval becomes seamless.