











जैसे-जैसे डेटा संचय तेजी से बढ़ता है, आपके डेटाबेस स्कीमा की वास्तुकला सिस्टम स्थिरता के लिए एक महत्वपूर्ण निर्धारक बन जाती है। जब कोई एप्लिकेशन पढ़ने पर अधिक निर्भर ऑपरेशन से लेखन पर अधिक निर्भर कार्यभार में बदलती है, तो मानक एंटिटी रिलेशनशिप डायग्राम (ईआरडी) को अक्सर महत्वपूर्ण समायोजन की आवश्यकता होती है। उच्च थ्रूपुट के लिए डिजाइन करना केवल इंडेक्स जोड़ने से अधिक है; यह डेटा के संरचना, संबंध और संग्रहण के तरीके के आधारभूत पुनर्विचार की आवश्यकता होती है। यह गाइड दबाव के तहत प्रदर्शन को बनाए रखने के लिए आवश्यक वास्तुकला परिवर्तनों का अध्ययन करता है बिना डेटा अखंडता को प्रभावित किए।
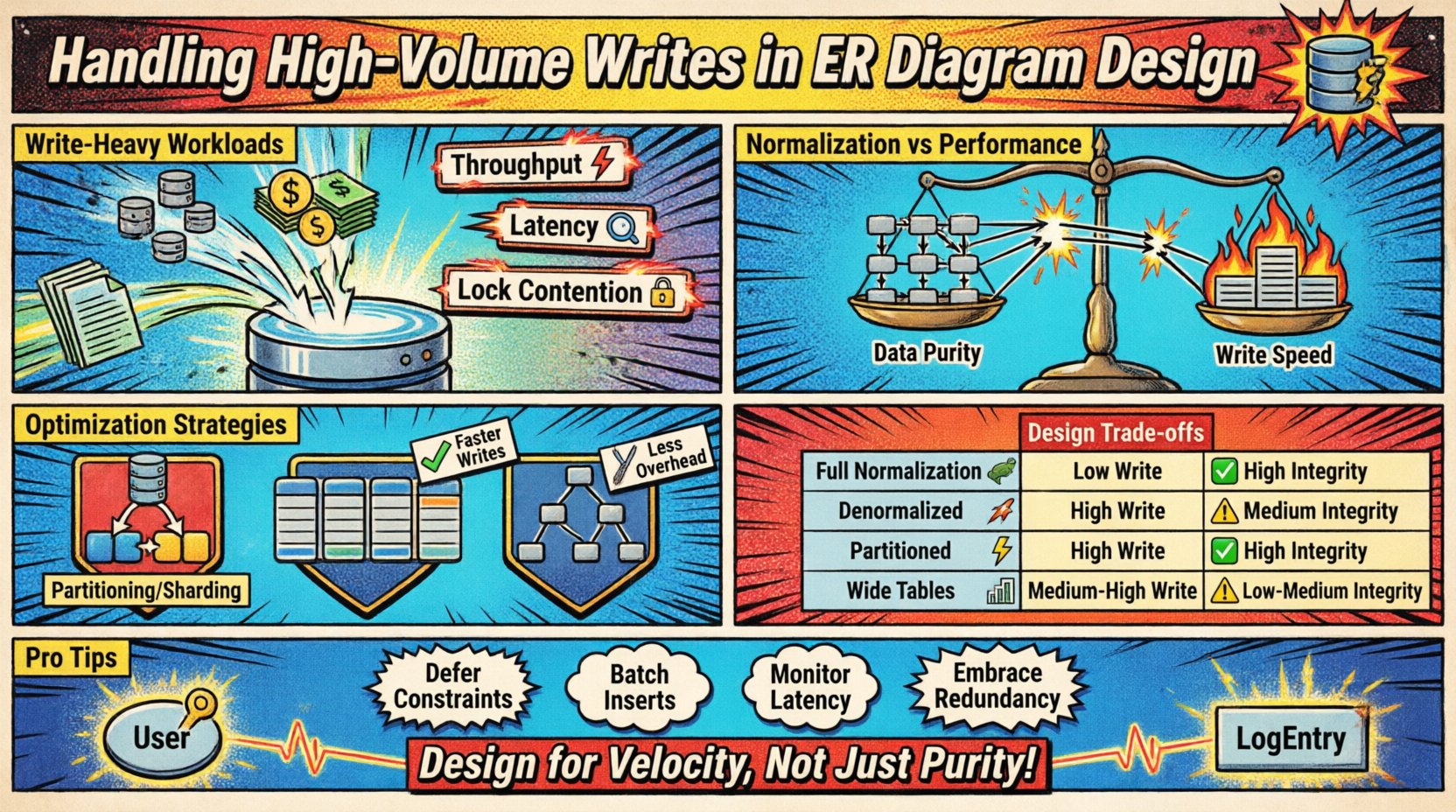
लेखन-भारी कार्यभार को समझना 📈
उच्च आयतन लेखन परिदृश्य तब होते हैं जब आने वाले डेटा की दर मानक नॉर्मलाइजेशन तकनीकों की क्षमता को पार कर जाती है। यह आमतौर पर लॉगिंग प्रणालियों, आईओटी सेंसर फीड्स, वित्तीय लेनदेन लेजर्स या रियल-टाइम विश्लेषण प्लेटफॉर्म में होता है। मुख्य चुनौती मॉडल की सुसंगतता आवश्यकताओं के बीच इन्सर्शन की गति को संतुलित करने में है।
- थ्रूपुट: प्रति सेकंड प्रोसेस किए जाने वाले लेखन ऑपरेशन की संख्या।
- लेटेंसी: एक रिकॉर्ड को सफलतापूर्वक स्थायी करने में लगने वाला समय।
- लॉक प्रतिस्पर्धा: जब कई प्रक्रियाएं एक ही डेटा को संशोधित करने की कोशिश करती हैं, तो संसाधनों के लिए प्रतिस्पर्धा।
जब इन मापदंडों का प्रदर्शन घटता है, तो आमतौर पर स्कीमा ही बॉटलनेक होता है। जटिल प्रश्नों के लिए अनुकूलित एक कठोर डिजाइन निरंतर अपडेट्स के भार के तहत टूट सकता है। इसलिए, प्रारंभिक ईआरडी को डेटा प्रवेश की गति को ध्यान में रखना चाहिए।
नॉर्मलाइजेशन बनाम प्रदर्शन के विकल्प ⚖️
पारंपरिक डेटाबेस डिजाइन नॉर्मलाइजेशन (1NF, 2NF, 3NF) को प्रोत्साहित करता है ताकि अतिरिक्तता कम की जा सके। यह भंडारण स्थान बचाता है और सुसंगतता सुनिश्चित करता है, लेकिन लेखन ऑपरेशन के दौरान ओवरहेड लाता है। प्रत्येक विदेशी कुंजी संबंध के लिए एक लुकअप और जॉइन जांच की आवश्यकता होती है ताकि संदर्भात्मक अखंडता बनाए रखी जा सके।
उच्च आयतन वाले वातावरण में, इन जांचों की लागत बढ़ जाती है। लेखन घटना के दौरान बहु-से-बहु संबंध के प्रभाव पर विचार करें:
- मुख्य तालिका को अपडेट करना होगा।
- जंक्शन तालिका को एक नई पंक्ति डालनी होगी।
- दूसरी तालिका को संबंध की पुष्टि करनी होगी।
- लेनदेन लॉग्स को सभी परिवर्तनों को रिकॉर्ड करना होगा।
प्रत्येक चरण डिस्क आई/ओ और सीपीयू साइकिल्स जोड़ता है। भारी लेखन लोड को संभालने के लिए डिजाइनर अक्सर नॉर्मलाइजेशन नियमों को ढीला कर देते हैं। इस प्रक्रिया में एक इकाई जानकारी को संग्रहीत करने के लिए आवश्यक लेखन ऑपरेशनों की संख्या को कम करने के लिए डेटा अतिरिक्तता स्वीकार करना शामिल होता है।
लेखन गति को अनुकूलित करने के रणनीतियाँ ✍️
लेखन दबाव को कम करने के लिए कई संरचनात्मक पैटर्न मौजूद हैं। इन रणनीतियों का ध्यान प्रत्येक लेनदेन के आकार को न्यूनतम करने और स्टोरेज इंजन के काम की जटिलता को कम करने पर केंद्रित है।
1. पार्टीशनिंग और शार्डिंग
एक बड़ी तालिका को छोटे, अधिक प्रबंधन योग्य टुकड़ों में बांटने से डेटाबेस को लेखन लोड को कई भौतिक या तार्किक खंडों में वितरित करने की अनुमति मिलती है।
- क्षैतिज पार्टीशनिंग: एक कुंजी (उदाहरण के लिए, तारीख की सीमा, उपयोगकर्ता आईडी) के आधार पर पंक्तियों को बांटना।
- उर्ध्वाधर पार्टीशनिंग:कम बार एक्सेस किए जाने वाले कॉलम को अलग तालिकाओं में स्थानांतरित करना।
- शार्डिंग:डेटा को कई डेटाबेस इंस्टेंसेज के बीच वितरित करना।
इस दृष्टिकोण से बनाए रखे जाने वाले सूचकांकों के आकार को कम किया जाता है और लेखन ऑपरेशन के दौरान लॉक के क्षेत्र को सीमित किया जाता है। यदि एक शार्ड संतृप्त हो जाता है, तो अन्य प्रभावित नहीं होते।
2. अनियमितता रणनीतियाँ
आवश्यकता से अधिक डेटा संग्रहण सिस्टम को लेखन के दौरान जॉइन को बचने की अनुमति देता है। उदाहरण के लिए, जब भी एक नया लेनदेन आता है, संबंधित पंक्तियों से कुल योग की गणना करने के बजाय, सिस्टम एक पूर्व-गणना किए गए सारांश कॉलम को सीधे अपडेट कर सकता है।
- गणना किए गए कॉलम: पंक्ति में सीधे व्युत्पन्न मान संग्रहित करें।
- सामग्रीकृत दृश्य: अक्सर होने वाले समावेशन के लिए परिणामों की पूर्व-गणना करें।
- कैश किए गए गणक: सांख्यिकी के लिए एक अलग गणक तालिका बनाए रखें।
हालांकि इससे स्टोरेज की आवश्यकता बढ़ जाती है, लेकिन इससे इन्सर्शन की CPU लागत काफी कम हो जाती है।
3. इंडेक्सिंग रणनीति
इंडेक्स पढ़ने को तेज करते हैं लेकिन लेखन को धीमा करते हैं। हर बार एक पंक्ति को सम्मिलित करने पर, डेटाबेस को प्रत्येक संबंधित इंडेक्स को अपडेट करना होता है। उच्च-लेखन वातावरण में, इंडेक्स का विस्तार एक महत्वपूर्ण समस्या बन जाता है।
- इंडेक्स की संख्या को न्यूनतम रखें: केवल उन कॉलम को इंडेक्स करें जिनका उपयोग फ़िल्टरिंग या जॉइन के लिए किया जाता है।
- आंशिक इंडेक्स: केवल उन पंक्तियों के एक उपसमूह को इंडेक्स करें जिनका अक्सर उपयोग किया जाता है।
- अत्यधिक इंडेक्सिंग से बचें: अक्सर बदलने वाले कॉलम पर इंडेक्स छोड़ दें।
डिज़ाइन दृष्टिकोणों की तुलना 📑
नीचे दी गई तालिका लेखन प्रदर्शन और डेटा अखंडता पर विभिन्न संरचनात्मक चयनों के प्रभाव को चित्रित करती है।
| रणनीति | लेखन प्रदर्शन | डेटा अखंडता | स्टोरेज लागत | सर्वोत्तम उपयोग केस |
|---|---|---|---|---|
| पूर्ण सामान्यीकरण | कम | उच्च | कम | जटिल रिपोर्टिंग, कम लेखन आयतन |
| अनियमित | उच्च | मध्यम | उच्च | रियल-टाइम फीड्स, उच्च लेखन आयतन |
| पार्टीशन्ड स्कीमा | उच्च | उच्च | मध्यम | समय-श्रृंखला डेटा, बड़े डेटासेट |
| वाइड टेबल्स | मध्यम-उच्च | मध्यम | मध्यम | नो-एसक्यूएल पैटर्न, स्पेस डेटा |
विदेशी कीज़ और सीमांकन का प्रबंधन 🔗
संदर्भित अखंडता संबंधात्मक डिज़ाइन की एक आधारशिला है, लेकिन हर इन्सर्ट पर सीमांकन को लागू करना एक उच्च गति वाले पाइपलाइन को रोक सकता है। डेटाबेस इंजन को बच्चे की पंक्ति को स्वीकार करने से पहले यह सत्यापित करना होगा कि संदर्भित मुख्य पंक्ति मौजूद है।
ऐसे परिदृश्यों में जहां डेटा अखंडता महत्वपूर्ण है लेकिन लेखन गति प्रमुख है, निम्नलिखित समायोजनों पर विचार करें:
- स्थगित सीमांकन:एक लेनदेन के अंत में संबंधों की पुष्टि करें, तुरंत नहीं।
- एप्लिकेशन-लेवल चेक: डेटाबेस को डेटा भेजने से पहले एप्लिकेशन कोड में संबंधों की पुष्टि करें।
- सॉफ्ट डिलीट्स: हटाने के बजाय रिकॉर्ड को अक्रिय चिह्नित करें ताकि हटाने के ओवरहेड के बिना संदर्भित लिंक बने रहें।
सीमांकन को पूरी तरह से हटाना जोखिम भरा है, लेकिन वैलिडेशन लॉजिक को स्थानांतरित करने से कभी-कभी थ्रूपुट में सुधार हो सकता है। निर्णय यह निर्भर करता है कि आपके विशिष्ट वर्कफ्लो के लिए तुरंत संगतता कितनी महत्वपूर्ण है।
लेखन एम्पलीफिकेशन और स्टोरेज इंजन 💾
स्टोरेज इंजन डेटा को कैसे संभालता है, इसकी समझ आवश्यक है। बहुत से इंजन दृढ़ता सुनिश्चित करने के लिए लिखने से पहले लॉग (WAL) का उपयोग करते हैं। इसका मतलब है कि प्रत्येक लेखन को वास्तविक डेटा फाइलों पर लागू करने से पहले लॉग किया जाता है।
लेखन एम्पलीफिकेशन तब होता है जब एक तार्किक लेखन ऑपरेशन के कारण बहुत सारे भौतिक लेखन होते हैं। यह कंपैक्शन-भारी स्टोरेज इंजन में सामान्य है। इसके प्रबंधन के लिए:
- बैच इन्सर्ट्स: एकल लेनदेन में कई पंक्तियों को समूहित करें।
- क्रमिक लेखन:क्रमिक की उत्पत्ति को यादृच्छिक इन्सर्ट्स के बजाय प्राथमिकता देने वाले स्कीमा डिज़ाइन करें।
- बफरिंग:लेखन को फ्लश करने से पहले रद्द करने के लिए एप्लिकेशन लेयर में एक अस्थायी बफर की अनुमति दें।
ERD डिज़ाइन को स्टोरेज इंजन की ताकतों के साथ मिलाकर, आप डेटा को स्थायी बनाने के लिए आवश्यक भौतिक प्रयास को न्यूनतम कर सकते हैं।
निगरानी और अनुकूलन 🔄
उच्च लेखन के लिए डिज़ाइन किया गया स्कीमा स्थिर नहीं है। जैसे ही ट्रैफ़िक पैटर्न बदलते हैं, डिज़ाइन को विकसित करने की आवश्यकता हो सकती है। लेखन लेटेंसी और डिस्क I/O का निरंतर निगरानी करना आवश्यक है।
- लेखन लेटेंसी का अनुसरण करें: बॉटलनेक्स को इंगित करने वाले शिखर की पहचान करें।
- लॉक वेट का निगरानी करें: ऐसे स्थानों का पता लगाएं जहां प्रक्रियाएं अवरुद्ध हैं।
- इंडेक्स उपयोग का विश्लेषण करें: लेखन ओवरहेड को कम करने के लिए उन इंडेक्स को हटाएं जो कभी उपयोग नहीं किए जाते हैं।
ERD के नियमित ऑडिट सुनिश्चित करते हैं कि संरचना वर्तमान संचालन आवश्यकताओं के साथ संरेखित रहे। यदि कोई विशिष्ट तालिका लगातार लेखन थ्रूपुट के साथ समस्या उत्पन्न करती है, तो शायद विभाजन रणनीति या नॉर्मलाइज़ेशन स्तर को दोबारा देखने का समय आ गया है।
मुख्य विचारों का सारांश 🛠️
उच्च आयतन लेखन के लिए ERD डिज़ाइन करने के लिए शुद्ध डेटा शुद्धता से सिस्टम थ्रूपुट की ओर मानसिकता में परिवर्तन की आवश्यकता होती है। निम्नलिखित बिंदु आवश्यक कार्रवाइयों का सारांश प्रस्तुत करते हैं:
- नॉर्मलाइज़ेशन का ऑडिट करें: सुनिश्चित करें कि प्रत्येक संबंध मात्रा के बजाय जटिलता को नहीं जोड़ता है।
- विभाजन के लिए योजना बनाएं: कीज़ को संरचित करें ताकि आसान क्षैतिज विभाजन संभव हो।
- इंडेक्स की सीमा निर्धारित करें: लेखन पथ को जितना संभव हो उतना स्वच्छ रखें।
- पुनरावृत्ति को अपनाएं: इन्सर्ट करते समय जॉइन निर्भरता को कम करने के लिए डेनॉर्मलाइज़ेशन का उपयोग करें।
- क्रमिक रूप से मान्यता दें: सुरक्षित जगह पर आलाप चेकिंग को क्रिटिकल लेखन पथ से बाहर ले जाएं।
इन सिद्धांतों के अनुप्रयोग से आप एक डेटा मॉडल बनाते हैं जो विकास को बनाए रख सकता है बिना प्रदर्शन के त्याग के। लक्ष्य जटिलता को खत्म करना नहीं है, बल्कि इसे इस तरीके से प्रबंधित करना है जो आपके एप्लिकेशन की गति का समर्थन करे।