











आधुनिक डेटा आर्किटेक्चर में, जानकारी के प्राप्त करने की गति अक्सर एक एप्लिकेशन के उपयोगी होने के निर्धारण करती है। जबकि हार्डवेयर अपग्रेड और कैशिंग रणनीतियां महत्वपूर्ण भूमिका निभाती हैं, प्रदर्शन का आधार डेटा संरचना में ही है। विशेष रूप से, एंटिटी रिलेशनशिप मॉडल्स (ERMs) के डिजाइन निर्धारित करते हैं कि डेटाबेस इंजन कितनी कुशलता से डेटा को अनुसरण, जोड़ और समग्र कर सकता है। एक अनुकूलित स्कीमा केवल जानकारी को व्यवस्थित नहीं करता है; यह प्रश्न ऑप्टिमाइज़र को तेज निष्पादन मार्गों की ओर निर्देशित करता है। 📉
यह गाइड स्कीमा डिजाइन के पीछे तकनीकी यांत्रिकी और प्रश्न प्रदर्शन से सीधे संबंध का अध्ययन करता है। हम देखेंगे कि नॉर्मलाइज़ेशन स्तर, संबंध कार्डिनैलिटी और इंडेक्सिंग रणनीतियां प्रश्न निष्पादन योजना के भीतर कैसे बातचीत करती हैं। इन गतिशीलताओं को समझकर, डेवलपर्स और डेटाबेस आर्किटेक्ट्स ऐसे प्रणालियां बना सकते हैं जो अखंडता या गति के बिना स्केल हो सकें।
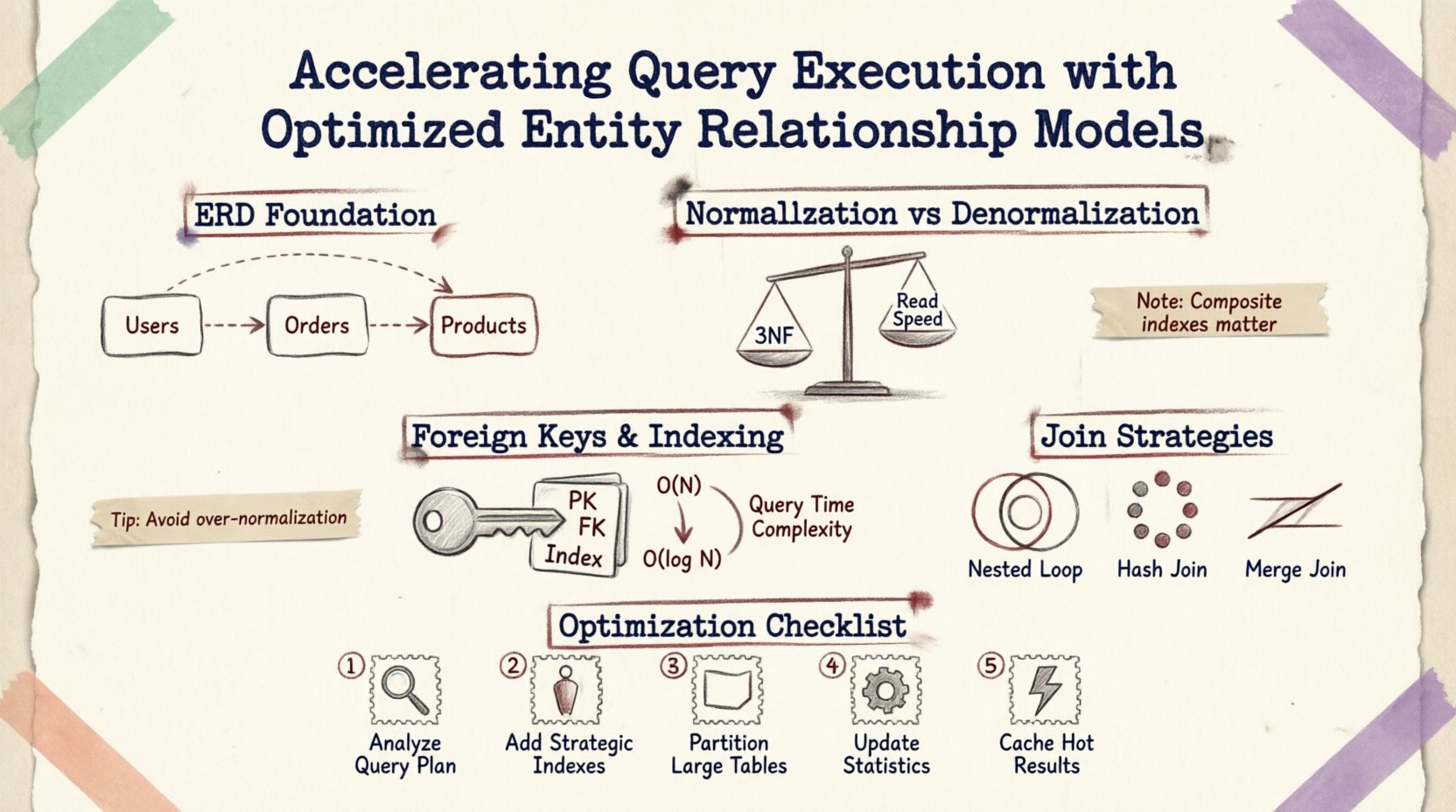
आधार को समझना: ERDs और प्रदर्शन 🗃️
एक एंटिटी रिलेशनशिप डायग्राम दस्तावेज़ीकरण के लिए एक दृश्य सहायता से अधिक है; यह भौतिक भंडारण और प्राप्ति तर्क का नक्शा है। तालिकाओं के बीच खींची गई हर रेखा एक विदेशी कुंजी सीमा, एक जॉइन ऑपरेशन या डेटा अखंडता नियम का प्रतिनिधित्व करती है। जब कोई प्रश्न प्रस्तुत किया जाता है, तो डेटाबेस इंजन इन संबंधों को समझकर एक निष्पादन योजना बनाता है।
एक सरल प्रश्न के बारे में सोचें जो उपयोगकर्ता के आदेश और उत्पाद विवरण के लिए मांग करता है। इंजन को आवश्यकता है:
- स्थान खोजें
उपयोगकर्तातालिका। - विदेशी कुंजी का अनुसरण करें
आदेशतालिका। - जॉइन करें
आदेश आइटमतालिका। - पहुंचें
उत्पाददूसरे संबंध के माध्यम से तालिका।
प्रत्येक चरण में I/O संचालन और CPU साइकिल शामिल होते हैं। यदि संबंध खराब रूप से परिभाषित हैं, तो इंजन पूर्ण तालिका स्कैन या नेस्टेड लूप जॉइन की ओर जा सकता है जो प्रदर्शन को घातीय रूप से बिगड़ देता है। ERD को अनुकूलित करने से डेटा के डिस्क से मेमोरी तक यात्रा करने वाली दूरी कम हो जाती है।
नॉर्मलाइज़ेशन बनाम डीनॉर्मलाइज़ेशन: संतुलन ढूंढना ⚖️
नॉर्मलाइज़ेशन डेटा को अतिरिक्त बारंबारता को कम करने और अखंडता को बेहतर बनाने के लिए व्यवस्थित करने की प्रक्रिया है। लगातारता के लिए आवश्यक होने के बावजूद, अत्यधिक नॉर्मलाइज़ेशन डेटा को कई छोटी तालिकाओं में टुकड़ों में बांट सकता है, जिसके लिए जटिल जॉइन की आवश्यकता होती है जो पढ़ने पर अधिक भारी ऑपरेशन को धीमा कर देता है।
गहन नॉर्मलाइज़ेशन की कीमत
जब किसी स्कीमा को तृतीय नॉर्मल रूप (3NF) तक नॉर्मलाइज़ किया जाता है, तो डेटा अपने सबसे परमाणु स्थिति में संग्रहीत होता है। इससे भंडारण स्थान और अपडेट विचलन को न्यूनतम किया जाता है। हालांकि, संबंधित डेटा को प्राप्त करने के लिए अक्सर कई विदेशी कुंजियों के माध्यम से अनुसरण करने की आवश्यकता होती है।
- जॉइन ओवरहेड: जॉइन श्रृंखला में प्रत्येक अतिरिक्त तालिका प्रश्न योजना की जटिलता को बढ़ाती है।
- लॉक प्रतिस्पर्धा:बहुत सारी तालिकाओं को प्राप्त करने से पंक्ति-स्तरीय लॉक संघर्ष की संभावना बढ़ जाती है।
- CPU उपयोग: डेटाबेस इंजन को अलग-अलग तालिकाओं से परिणाम सेट को मिलाना होता है।
जब डीनॉर्मलाइज़ करें
अनियमितता पढ़ने के प्रदर्शन को अनुकूलित करने के लिए अतिरिक्त डेटा लाती है। यह अक्सर विश्लेषणात्मक प्रसंस्करण या उच्च ट्रैफिक रिपोर्टिंग वातावरणों में आवश्यक होती है।
- पढ़ने पर अधिक निर्भर कार्यभार: यदि लेखन पढ़ने की तुलना में दुर्लभ हैं, तो अनियमित कॉलम जोड़ने से जॉइन संचालन बचते हैं।
- पूर्व-गणना किए गए योग: कुल राशि संग्रहित करना (उदाहरण के लिए,
कुल_आदेश_मूल्य) उपयोगकर्ता तालिका में संग्रहित करने से प्रत्येक अनुरोध पर योग की गणना करने से बचा जा सकता है। - क्षैतिज विभाजन: अक्सर पहुँचे जाने वाले डेटा को एक साथ रखने से कैश स्थिति में सुधार होता है।
हालांकि, अनियमितता के डेटा असंगति से बचने के लिए सावधानीपूर्वक प्रबंधन की आवश्यकता होती है। एप्लिकेशन तर्क को सुनिश्चित करना चाहिए कि जब भी मूल डेटा बदलता है, तो अतिरिक्त डेटा को अपडेट किया जाए।
विदेशी कुंजियाँ और इंडेक्सिंग रणनीति 🔑
विदेशी कुंजी सीमाएँ संदर्भात्मक अखंडता को बनाए रखती हैं, लेकिन इसके प्रदर्शन लागत भी होती है। डेटाबेस को एक तालिका में मान के दूसरी तालिका में मौजूद होने की जाँच करनी होती है जब तक इंसर्ट या अपडेट की अनुमति नहीं दी जाती। इन कुंजियों को कैसे इंडेक्स किया जाए, इसके अनुकूलन क्रांतिक है।
विदेशी कुंजियों का इंडेक्सिंग
डिफ़ॉल्ट रूप से, प्राथमिक कुंजियों को स्वतः ही इंडेक्स किया जाता है। हालांकि, विदेशी कुंजियों को जॉइन संचालन को तेज करने के लिए अक्सर स्पष्ट इंडेक्स की आवश्यकता होती है। विदेशी कुंजी कॉलम पर इंडेक्स के बिना:
- डेटाबेस को बच्चे तालिका के पूरे टेबल स्कैन करने की आवश्यकता होती है ताकि मेल खाने वाली पंक्तियाँ मिल सकें।
- जॉइन संचालन बहुत धीमे हो जाते हैं, विशेष रूप से जब तालिका के आकार में लाखों पंक्तियों तक बढ़ते हैं।
- हटाने के दौरान संदर्भात्मक अखंडता जांच लागत वाली हो जाती है।
एक सही तरीके से इंडेक्स की गई विदेशी कुंजी डेटाबेस को स्कैन के बजाय इंडेक्स सीक का उपयोग करने की अनुमति देती है, जिससे जटिलता O(N) से घटकर O(log N) हो जाती है।
संबंधों के लिए संयुक्त इंडेक्स
जब कई कॉलम एक संबंध को परिभाषित करते हैं, तो संयुक्त इंडेक्स अलग-अलग इंडेक्स की तुलना में अधिक प्रभावी हो सकता है। उदाहरण के लिए, यदि कोई प्रश्न उपयोगकर्ता_आईडी और निर्मित_समय आदेश तालिका के भीतर है, तो दोनों कॉलम पर संयुक्त इंडेक्स यह सुनिश्चित करता है कि इंजन असंबंधित रिकॉर्ड्स को स्कैन किए बिना डेटा को स्थान ढूंढ सके।
जॉइन रणनीतियाँ और निष्पादन योजनाएँ 🔍
ईआरडी की संरचना उन जॉइन एल्गोरिदम को प्रभावित करती है जो प्रश्न ऑप्टिमाइज़र चुनता है। इन यांत्रिकी को समझना उन स्कीमा के डिज़ाइन में मदद करता है जो कुशल जॉइन प्रकारों के पक्ष में हों।
| जॉइन प्रकार | सबसे अच्छा उपयोग कब किया जाए | प्रदर्शन प्रभाव |
|---|---|---|
| नेस्टेड लूप जॉइन | छोटे परिणाम सेट या अत्यधिक चयनात्मक प्रतिबंध | छोटे डेटा के लिए तेज़; बड़े स्कैन के लिए धीमा |
| हैश जॉइन | इंडेक्स के बिना बड़ी टेबलें | मेमोरी अधिक उपयोग करने वाला; अक्रमित डेटा के लिए अच्छा |
| मर्ज जॉइन | जॉइन की चाबियों पर क्रमबद्ध इनपुट | अगर डेटा पहले से ही क्रमबद्ध है तो बहुत तेज़ |
क्रमबद्ध इनपुट या इंडेक्स लुकअप का समर्थन करने के लिए ईआरडी को डिज़ाइन करने से ऑप्टिमाइज़र को तेज़ जॉइन विधियों का चयन करने के लिए प्रोत्साहित किया जा सकता है। उदाहरण के लिए, जॉइन की चाबियों को क्लस्टर्ड इंडेक्स के हिस्से के रूप में परिभाषित करने से मर्ज जॉइन को सुविधा मिल सकती है।
स्कीमा डिज़ाइन में सामान्य गलतियाँ 🚫
यहां तक कि अनुभवी वास्तुकार भी ऐसी गलतियां करते हैं जो प्रश्न गति को प्रभावित करती हैं। इन पैटर्न को जल्दी पहचानने से बाद में महंगे रीफैक्टरिंग से बचा जा सकता है।
- श्रृंखलित विदेशी कुंजियाँ:तालिका A को B से जोड़ने वाली संबंधों की श्रृंखला बनाना, जहां B को C से जोड़ा जाता है और C को D से जोड़ा जाता है। सभी चार टेबलों को जोड़ने वाले प्रश्न गहन रूप से नेस्टेड हो जाते हैं और धीमे हो जाते हैं।
- चर लंबाई के स्ट्रिंग्स: उपयोग करना
VARCHARजिन कुंजियों की लंबाई हमेशा निश्चित होती है, उनके लिए उपयोग करने से स्थान का बर्बादी होती है और पंक्ति तुलना धीमी हो जाती है। - जंक्शन टेबल के बिना बहुत-से-के-बहुत-से: एक ही कॉलम में कई आईडी को स्टोर करने की कोशिश (उदाहरण के लिए, कॉमा से अलग मान) सही इंडेक्सिंग और नॉर्मलाइजेशन को रोकती है।
- अप्रत्यक्ष रूपांतरण:माता-पिता और बच्चे की टेबलों के बीच डेटा प्रकार के मेल नहीं खाने वाले परिभाषित करने से इंजन को रनटाइम पर मानों के रूपांतरण करने के लिए मजबूर किया जाता है, जिससे इंडेक्स के उपयोग को रोका जाता है।
अनुकूलन के लिए व्यावहारिक चरण 🛠️
पूरे सिस्टम को फिर से लिखे बिना प्रश्न के निष्पादन में सुधार करने के लिए, इन संरचित चरणों का पालन करें:
- प्रश्न पैटर्न का विश्लेषण करें: सबसे अधिक आम पढ़ने वाले संचालन का रीव्यू करें। यह पहचानें कि कौन सी टेबलें सबसे अधिक बार जोड़ी जाती हैं।
- इंडेक्स उपयोग का रीव्यू करें: विदेशी कुंजियों या अक्सर फ़िल्टर किए जाने वाले कॉलम पर गायब इंडेक्स के लिए जांच करें।
- कार्डिनैलिटी को बेहतर बनाएं: सुनिश्चित करें कि संबंध सही ढंग से मॉडल किए गए हैं (एक-एक बनाम एक-बहुत से)। गलत कार्डिनैलिटी के कारण अनावश्यक जॉइन हो सकते हैं।
- बड़ी टेबलों को पार्टीशन करें: यदि किसी तालिका में मिलियनों पंक्तियों से अधिक हैं, तो प्रत्येक प्रश्न में स्कैन किए जाने वाले डेटा को सीमित करने के लिए तारीख या क्षेत्र के आधार पर विभाजन करने का विचार करें।
- लॉकिंग का निरीक्षण: लंबे समय तक चलने वाले प्रश्नों को पहचानने के लिए निरीक्षण उपकरणों का उपयोग करें जो लॉक को धारण करते हैं, जो अक्सर अकुशल स्कीमा अनुसरण के कारण होते हैं।
स्टोरेज और मेमोरी पर विचार 💾
डेटा की भौतिक व्यवस्था भी भूमिका निभाती है। डेटाबेस इंजन डेटा को पेज में संग्रहीत करते हैं। यदि संबंधित पंक्तियाँ भौतिक रूप से एक दूसरे के करीब संग्रहीत हैं, तो डेटासेट को लोड करने के लिए कम डिस्क रीड्स की आवश्यकता होती है।
- क्लस्टरिंग:एक सामान्य कुंजी द्वारा डेटा को व्यवस्थित करने से रेंज स्कैन में सुधार होता है।
- कॉलम स्टोर बनाम रो स्टोर: विश्लेषणात्मक प्रश्नों के लिए, कॉलम-आधारित स्टोरेज पारंपरिक रो-आधारित मॉडलों की तुलना में बेहतर संपीड़न और तेजी से एग्रीगेशन प्रदान कर सकता है।
- कैशिंग: पूरे परिणाम सेट को बजाय व्यक्तिगत पंक्तियों के प्रभावी कैशिंग की अनुमति देने वाले स्कीमा डिज़ाइन करें।
स्कीमा विकास पर अंतिम विचार 🔄
स्कीमा डिज़ाइन एक बार का कार्य नहीं है। जैसे-जैसे एप्लिकेशन की आवश्यकताएं बदलती हैं, डेटा मॉडल को विकसित करना होता है। डेटाबेस संरचना का नियमित रूप से निरीक्षण करने से यह सुनिश्चित होता है कि प्रदर्शन स्थिर रहे। एंटिटी रिलेशनशिप मॉडल के दस्तावेज़ीकरण को कोडबेस के साथ बनाए रखना चाहिए ताकि बदलावों के प्रभाव को ट्रैक किया जा सके।
डेटा के भीतर संरचनात्मक अखंडता और तार्किक संबंधों पर ध्यान केंद्रित करके, आप एक आधार बनाते हैं जो उच्च गति से प्रश्न क्रियान्वयन का समर्थन करता है। लक्ष्य एक स्थिर प्रणाली बनाना नहीं है, बल्कि एक लचीली वास्तुकला बनाना है जो लोड के अनुसार अनुकूलित होती है बिना उपयोगकर्ताओं की अपेक्षा की गति के त्याग के। 📊
एंटिटी रिलेशनशिप मॉडल को अनुकूलित करना एक तकनीकी विषय है जो डेटाबेस सिद्धांत और व्यावहारिक इंजीनियरिंग को मिलाता है। इसमें धैर्य, विश्लेषण और यह समझने की आवश्यकता होती है कि नीचे का इंजन प्रश्नों को कैसे प्रसंस्कृत करता है। सही दृष्टिकोण के साथ, प्रदर्शन संबंधी समस्याएं प्रबंधनीय हो जाती हैं, और डेटा प्राप्त करना निरंतर हो जाता है।