











एंटिटी रिलेशनशिप डायग्राम (ERD) डेटाबेस आर्किटेक्चर के लिए ब्लूप्रिंट के रूप में कार्य करते हैं। वे यह निर्धारित करते हैं कि डेटा किस तरह संरचित, स्टोर और प्राप्त किया जाता है। जब इन डायग्रामों में कमियाँ होती हैं, तो इनके परिणाम विकास चरण से बहुत आगे तक फैल जाते हैं। उत्पादन वातावरण में त्रुटियाँ डेटा को नष्ट कर सकती हैं, प्रदर्शन की समस्याएँ उत्पन्न कर सकती हैं और महत्वपूर्ण वित्तीय हानि का कारण बन सकती हैं। सिस्टम की अखंडता बनाए रखने के लिए सामान्य त्रुटियों को समझना आवश्यक है।
बहुत से टीमें मॉडलिंग चरण को जल्दी से पार करती हैं, त्वरितता को निपुणता से अधिक प्राथमिकता देते हैं। इस जल्दबाजी के कारण अक्सर ऐसी स्कीमा समस्याएँ उत्पन्न होती हैं जिन्हें डेटा के प्रवाह शुरू होने के बाद ठीक करना मुश्किल हो जाता है। एक मजबूत डिज़ाइन में संबंधों, डेटा प्रकारों और सीमाओं के सावधानीपूर्वक विचार करना आवश्यक होता है। नीचे हम सबसे आम डिज़ाइन की कमियों और उनके तकनीकी प्रभावों का अध्ययन करते हैं।
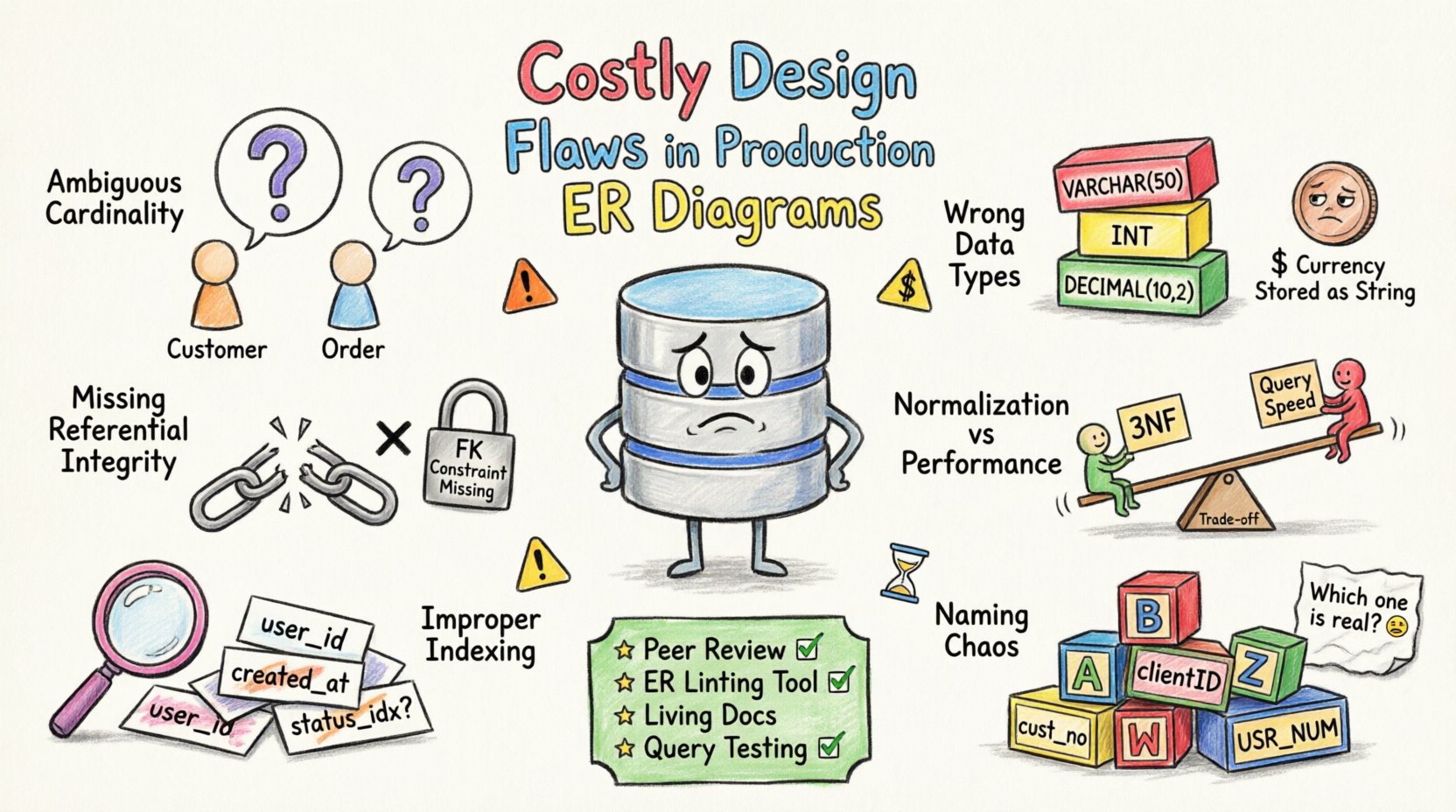
1. अस्पष्ट कार्डिनैलिटी और संबंध 🔗
कार्डिनैलिटी एंटिटी के बीच संख्यात्मक संबंध को परिभाषित करती है। गलत कार्डिनैलिटी डेटा प्राप्त करने और स्टोर करने में तार्किक त्रुटियों का कारण बनती है। एक सामान्य गलती यह है कि जब एक से बहुत के संदर्भ में एक से एक संबंध मान लिया जाता है।
- बहु-से-बहु लापता करना:बहु-से-बहु संबंधों के लिए जंक्शन टेबल बनाने के असफल होने से डेटा की दोहराव या जटिल जॉइन क्वेरीज़ के लिए मजबूर किया जाता है।
- अपरिभाषित विदेशी कीज़:स्पष्ट विदेशी कीज़ के बिना, डेटाबेस रेफरेंशियल इंटीग्रिटी को लागू नहीं कर सकता है, जिससे अनाथ रिकॉर्ड बने रहते हैं।
- वैकल्पिक बनाम अनिवार्य:आवश्यक संबंध को वैकल्पिक मानने से उन स्थानों पर नल मान आते हैं जहाँ डेटा की अपेक्षा की जाती है।
उदाहरण के लिए, एक ग्राहक और एक आदेश को लें। यदि डायग्राम से यह निर्देशित होता है कि एक ग्राहक बिना आदेश के भी मौजूद हो सकता है, लेकिन एप्लीकेशन लॉजिक इसकी आवश्यकता करता है, तो डेटाबेस अपूर्ण प्रोफाइल स्टोर करेगा। इस अंतर के कारण एप्लीकेशन क्रैश हो सकता है या असंगत रिपोर्टिंग हो सकती है।
2. असंगत डेटा प्रकार चयन 📊
डेटा प्रकार निर्धारित करते हैं कि जानकारी कैसे स्टोर और प्रोसेस की जाती है। गलत प्रकार का चयन अनावश्यक स्टोरेज का उपयोग करता है या मानों की सीमा को सीमित करता है। जब मुद्रा के लिए फ्लोटिंग पॉइंट संख्याओं का उपयोग किया जाता है, तो सटीकता की समस्याएँ अक्सर उत्पन्न होती हैं।
- इंटीजर ओवरफ्लो:आईडेंटिफायर के लिए छोटे पूर्णांकों का उपयोग करने से डेटासेट बढ़ने पर ओवरफ्लो त्रुटियाँ उत्पन्न हो सकती हैं।
- पाठ की लंबाई:निश्चित लंबाई वाले वर्ण क्षेत्रों का उपयोग चर लंबाई वाले डेटा के लिए स्थान के बर्बाद करता है।
- तारीख की सटीकता:समय क्षेत्र के बिना तारीखों को स्टोर करने से वितरित प्रणालियों में सिंक्रोनाइज़ेशन की समस्याएँ उत्पन्न होती हैं।
फोन नंबर के लिए एक सामान्य पाठ क्षेत्र चुनना एक अन्य आम त्रुटि है। इससे अवैध अक्षर प्रणाली में प्रवेश करने की अनुमति मिलती है, जिससे बाद में सत्यापन तर्क को जटिल बना दिया जाता है। गणना के लिए संख्यात्मक क्षेत्रों का उपयोग करना चाहिए, और पाठ क्षेत्र केवल अल्फान्यूमेरिक डेटा के लिए ही उपयोग करना चाहिए।
3. रेफरेंशियल इंटीग्रिटी सीमाओं का अभाव 🔒
रेफरेंशियल इंटीग्रिटी सुनिश्चित करती है कि टेबलों के बीच संबंध संगत बने रहें। इन सीमाओं के बिना, डेटाबेस एप्लीकेशन कोड पर निर्भर रहता है जो डेटा की सटीकता बनाए रखता है, जो मानव त्रुटि के लिए अधिक संवेदनशील होता है।
- कोई कैस्केड नियम नहीं:कैस्केड नियमों के बिना एक माता-पिता रिकॉर्ड को हटाने से बच्चे के रिकॉर्ड डेटाबेस में लटके रह जाते हैं।
- अनुपस्थित सीमाएँ:डेटाबेस सीमाओं के बजाय एप्लीकेशन स्तरीय सत्यापन पर भरोसा करना पर्याप्त नहीं है।
- सॉफ्ट डिलीट:हटाए गए रिकॉर्ड के गलत निपटान से अव्यवस्था उत्पन्न होती है और क्वेरी प्रदर्शन को धीमा कर देती है।
जब सीमाएँ अनुपस्थित होती हैं, तो डेटा अखंडता पूरी तरह से एप्लीकेशन डेवलपर्स पर निर्भर रहती है। यदि एक बग डेटाबेस में सीधे लेखन की अनुमति देता है, तो असंगतताएँ स्थायी हो जाती हैं। यह लंबे समय तक चलने वाले उत्पादन प्रणालियों में डेटा के नष्ट होने का प्रमुख कारण है।
4. सामान्यीकरण बनाम प्रदर्शन के विकल्प ⚖️
सामान्यीकरण अतिरेक को कम करता है लेकिन प्रश्न की जटिलता बढ़ा सकता है। अत्यधिक सामान्यीकरण के कारण अत्यधिक जॉइन होते हैं, जबकि अपर्याप्त सामान्यीकरण अपडेट विचलन उत्पन्न करता है। प्रदर्शन के लिए संतुलन बनाए रखना महत्वपूर्ण है।
- तृतीय सामान्य रूप (3NF): लेन-देन प्रणालियों के लिए अक्सर आदर्श होता है, लेकिन पढ़ने पर अधिक भार डालने वाले कार्यभार के लिए सामान्यीकरण को वापस लेने की आवश्यकता हो सकती है।
- असामान्यीकरण: प्रदर्शन के लिए अतिरेक लाना लेखांकन के लिए आवश्यक है ताकि अपडेट संघर्षों से बचा जा सके।
- प्रश्न जटिलता: गहन रूप से सामान्यीकृत स्कीमा के लिए जटिल जॉइन की आवश्यकता होती है, जो डेटाबेस इंजन पर दबाव डालती है।
टीमें अक्सर डेटा शुद्धता सुनिश्चित करने के लिए अत्यधिक सामान्यीकरण करती हैं, जिसमें कई तालिकाओं के जॉइन के लागत को नजरअंदाज कर दिया जाता है। उच्च ट्रैफिक वाले वातावरणों में, इससे धीमी प्रतिक्रिया समय आती है। रणनीतिक असामान्यीकरण पढ़ने के प्रदर्शन में सुधार कर सकता है, बशर्ते लेखन कार्यों का सही तरीके से प्रबंधन किया जाए।
5. अनुचित सूचकांक रणनीति 🏷️
सूचकांक डेटा प्राप्ति को तेज करते हैं, लेकिन लेखन कार्यों को धीमा करते हैं। दोषपूर्ण एरडी अक्सर डेटा के प्रश्न के तरीके को ध्यान में नहीं रखता है। इससे पूरी तालिका के स्कैन और उच्च लेटेंसी होती है।
- गैर-स्थानीय कुंजी सूचकांकों की अनुपस्थिति: अनसूचकांकित कॉलम पर जॉइन करना गणनात्मक रूप से महंगा होता है।
- अत्यधिक सूचकांकन: बहुत सारे सूचकांक लेखन लेटेंसी और स्टोरेज आवश्यकताओं को बढ़ाते हैं।
- संयुक्त सूचकांक क्रम: संयुक्त सूचकांकों में गलत कॉलम क्रम उन्हें अकार्यक्षम बना देता है।
एक बार-बार प्रश्न किए जाने वाले कॉलम पर सूचकांक लगाना मानक अभ्यास है। हालांकि, डिजाइन चरण के दौरान प्रश्न पैटर्न को नजरअंदाज करने से अकुशल पहुंच मार्ग बनते हैं। सूचकांक रणनीति को समायोजित करने के लिए प्रश्न के क्रियान्वयन योजनाओं की नियमित समीक्षा आवश्यक है।
6. नामकरण परंपरा का अव्यवस्था 🏷️
रखरखाव के लिए स्थिर नामकरण परंपराएं महत्वपूर्ण हैं। असंगत तालिका और कॉलम नाम स्कीमा को समझने और संशोधित करने में कठिनाई पैदा करते हैं।
- मिश्रित केस: कुछ स्थानों पर camelCase का उपयोग करना और दूसरे स्थानों पर snake_case का उपयोग करना भ्रम पैदा करता है।
- अस्पष्ट संक्षिप्त रूप: “कस्ट” या “ऑर्ड” जैसे संक्षिप्त नाम नए टीम सदस्यों के लिए स्पष्टता की कमी करते हैं।
- आरक्षित कीवर्ड्स: आरक्षित शब्दों का तालिका नाम के रूप में उपयोग करने से प्रश्नों में सिंटैक्स त्रुटियां होती हैं।
स्पष्ट नामकरण विकासकर्मियों और डेटाबेस प्रबंधकों पर मानसिक भार को कम करता है। इसके अलावा यह स्वचालित दस्तावेजीकरण उत्पादन को सुगम बनाता है और SQL बयानों में टाइपो की संभावना को कम करता है।
सामान्य दोषों के प्रभाव विश्लेषण
| डिजाइन की कमी | तकनीकी प्रभाव | व्यापार लागत |
|---|---|---|
| गैर-मौजूद विदेशी कुंजियाँ | अनाथ रिकॉर्ड, डेटा असंगति | डेटा हानि, सुसंगतता उल्लंघन |
| गलत डेटा प्रकार | स्टोरेज बर्बादी, गणना त्रुटियाँ | वित्तीय अंतर, रिपोर्टिंग त्रुटियाँ |
| अत्यधिक सामान्यीकरण | धीमी क्वेरी प्रदर्शन, उच्च लेटेंसी | धीमा उपयोगकर्ता अनुभव, खोए हुए राजस्व |
| गैर-मौजूद सूचियाँ | पूर्ण टेबल स्कैन, डेटाबेस लॉक प्रतिस्पर्धा | सिस्टम बंद होना, खराब स्केलेबिलिटी |
| खराब नामकरण | उच्च रखरखाव ओवरहेड, त्रुटि दरें | विकास समय में वृद्धि, बग्स |
रोकथाम रणनीतियाँ 🛡️
इन दोषों को रोकने के लिए डेटाबेस डिजाइन के प्रति अनुशासित दृष्टिकोण की आवश्यकता होती है। निम्नलिखित चरण डेप्लॉयमेंट से पहले जोखिमों को कम करने में मदद करते हैं।
- सहकर्मी समीक्षाएँ: किसी भी बदलाव को मर्ज करने से पहले अनिवार्य स्कीमा समीक्षा कार्यान्वित करें।
- स्वचालित लिंटिंग: नामकरण प्रथाओं और संरचनात्मक मानकों की जाँच के लिए उपकरणों का उपयोग करें।
- दस्तावेज़ीकरण: वास्तविक स्कीमा को दर्शाने वाले अद्यतन ERD आरेखों को बनाए रखें।
- परीक्षण: उत्पादन से पहले स्टेजिंग परिवेश में स्कीमा सत्यापन परीक्षण चलाएँ।
डेटाबेस स्कीमा के लिए संस्करण नियंत्रण प्रक्रिया अपनाने से यह सुनिश्चित होता है कि बदलावों को ट्रैक किया जाए और वापस ले लिया जा सके। इससे टीमों को यह पहचानने में मदद मिलती है कि किस समय एक दोष शामिल किया गया था और आवश्यकता पड़ने पर वापस ले लिया जा सकता है। विकासकर्मियों और वास्तुकारों के बीच सहयोग बातचीत के लिए आवश्यक है ताकि समस्याओं को जल्दी पकड़ा जा सके।
लंबे समय तक रखरखाव के विचार 🔄
डेटाबेस स्कीमा समय के साथ विकसित होते रहते हैं। एक डिजाइन जो आज काम करता है, भविष्य की आवश्यकताओं के अनुकूल नहीं हो सकता है। नियमित ऑडिट तकनीकी ऋण और पुराने पैटर्न की पहचान करने में मदद करते हैं।
- स्कीमा विचलन: ERD और लाइव डेटाबेस के बीच अंतरों को मॉनिटर करें।
- अप्रचलन: अनियोजित तालिकाओं और कॉलम के हटाने की योजना बनाएं।
- स्केलेबिलिटी: बड़े डेटासेट के लिए पार्टीशनिंग और शार्डिंग को ध्यान में रखते हुए डिज़ाइन करें।
रखरखाव को नजरअंदाज करने से एक नाजुक प्रणाली बनती है जो बदलाव का विरोध करती है। सक्रिय प्रबंधन सुनिश्चित करता है कि डेटाबेस एप्लिकेशन के लिए एक विश्वसनीय आधार बना रहे। प्रारंभिक डिज़ाइन में समय निवेश करने से सॉफ्टवेयर के जीवनचक्र के दौरान लाभ मिलता है।
स्कीमा अखंडता पर अंतिम विचार 📝
उत्पादन डेटाबेस त्रुटियां अक्सर डिज़ाइन चरण में नजरअंदाज की गई विविध विवरणों के कारण होती हैं। कार्डिनैलिटी, डेटा प्रकार, सीमाएं और इंडेक्सिंग को संबोधित करके टीमें अधिक लचीली प्रणालियां बना सकती हैं। उत्पादन में एक दोष को ठीक करने की लागत मॉडलिंग के दौरान इसे रोकने की तुलना में काफी अधिक होती है।
स्पष्टता, सुसंगतता और मान्यता पर ध्यान केंद्रित करें। एक अच्छी तरह से संरचित ERD डेटा विश्वसनीयता की आधारशिला है। लंबे समय तक स्थिरता सुनिश्चित करने के लिए गति की तुलना में गुणवत्ता को प्राथमिकता दें। इस दृष्टिकोण से जोखिम कम किया जाता है और प्रणाली के भीतर संग्रहीत डेटा का मूल्य अधिकतम किया जाता है।