











डेटाबेस आर्किटेक्चर एप्लीकेशन की जटिलता के साथ विकसित होता है। विकास के प्रारंभिक चरणों में, एक ही डेटाबेस आमतौर पर सभी डेटा संचालन को संभालने के लिए पर्याप्त होता है। हालांकि, जैसे ही सिस्टम बढ़ता है, प्रारंभिक स्कीमा अक्सर एक बाधा बन जाती है। इस स्थिति को आमतौर पर मोनोलिथिक स्कीमा कहा जाता है। इसकी विशेषता तंतु जुड़े टेबल, अतिरिक्त डेटा और कठोर प्रतिबंध होते हैं जो स्केलेबिलिटी को रोकते हैं। इस समस्या को दूर करने के लिए इंजीनियर संरचनात्मक पुनर्डिजाइन की ओर मुड़ते हैं। एंटिटी रिलेशनशिप मॉडलिंग (ईआरएम) इन परिवर्तनों को दृश्य रूप से देखने और व्यवस्थित करने के लिए सैद्धांतिक ढांचा प्रदान करता है। यह गाइड ईआरएम सिद्धांतों का उपयोग करके मोनोलिथिक स्कीमा के पुनर्गठन की तकनीकी प्रक्रिया का अध्ययन करता है ताकि एक अधिक लचीला डेटा परत प्राप्त की जा सके।
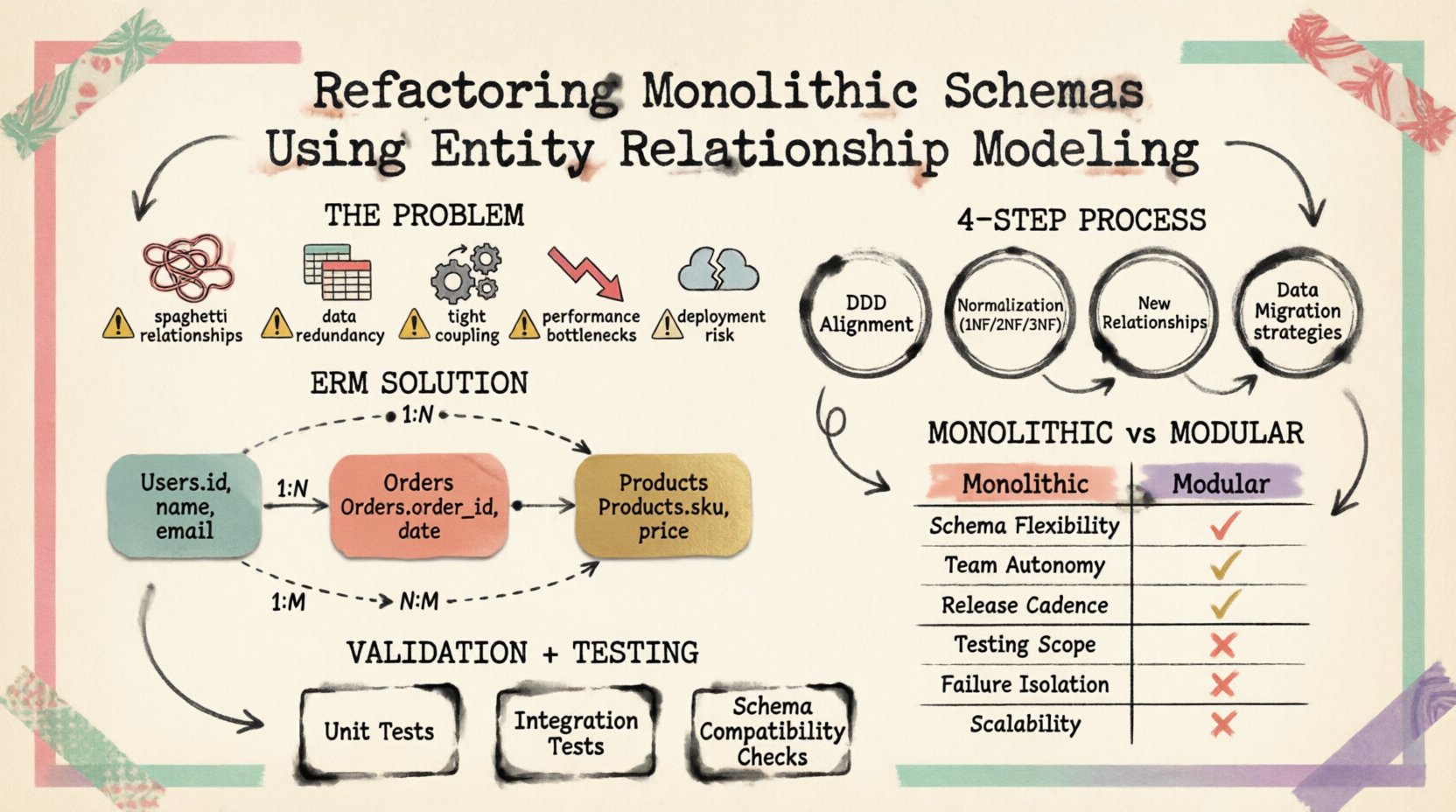
मोनोलिथिक स्कीमा समस्या को समझना 📉
एक मोनोलिथिक स्कीमा आमतौर पर जानबूझकर योजना बनाने के बजाय जैविक विकास से उभरती है। फीचर जोड़े जाते हैं और तात्कालिक आवश्यकताओं को समर्थन देने के लिए टेबल बनाए जाते हैं, जिसमें भविष्य के अलगाव के बारे में विचार नहीं किया जाता है। समय के साथ, इससे कई तकनीकी ऋण के संकेत उत्पन्न होते हैं:
- स्पैगेटी संबंध:विदेशी कुंजियाँ असंबंधित एंटिटी को जोड़ती हैं, जिससे चक्रीय निर्भरता बनती है।
- डेटा अतिरेक:एक ही जानकारी को कई टेबलों में संग्रहीत किया जाता है, जिससे अपडेट के दौरान संगतता की समस्या उत्पन्न होती है।
- तंतु जुड़ाव:एप्लीकेशन लॉजिक को अलग नहीं किया जा सकता क्योंकि डेटाबेस संरचना इसे बाध्य करती है।
- प्रदर्शन की बाधाएँ:मिश्रित डेटा प्रकार वाली बड़ी टेबलों को जटिल क्वेरीज की आवश्यकता होती है जो पढ़ने के संचालन को धीमा कर देती हैं।
- डिप्लॉयमेंट जोखिम:एक टेबल को बदलने के लिए अक्सर एक साथ कई एप्लीकेशन सेवाओं को संशोधित करने की आवश्यकता होती है।
इन लक्षणों को पहचानना उपचार की पहली कदम है। लक्ष्य केवल टेबलों को फिर से व्यवस्थित करना नहीं है, बल्कि डेटा संरचना को व्यावसायिक तार्किक क्षेत्रों के साथ समायोजित करना है।
एंटिटी रिलेशनशिप मॉडलिंग की भूमिका 📐
एंटिटी रिलेशनशिप मॉडलिंग डेटाबेस डिजाइन के लिए ब्लूप्रिंट के रूप में कार्य करता है। यह एंटिटी (टेबल), एट्रिब्यूट (कॉलम) और संबंध (विदेशी कुंजियाँ) को दृश्य और तार्किक रूप से परिभाषित करता है। पुनर्गठन के दौरान, ईआरएम नए संरचना के संगत रहने की गारंटी देने के लिए एक नियंत्रण तंत्र के रूप में कार्य करता है।
ईआरएम के मुख्य घटक
- एंटिटी: अलग-अलग वस्तुओं या अवधारणाओं का प्रतिनिधित्व करते हैं, जैसे किउपयोगकर्ता याआदेश। स्कीमा में, इन्हें टेबल बना दिया जाता है।
- एट्रिब्यूट: एंटिटी का वर्णन करने वाले गुण, जैसे किईमेल यामूल्य। इन्हें कॉलम के साथ मैप किया जाता है।
- संबंध: संबंधों में एकता के तरीके को परिभाषित करता है, जैसे एक-एक या एक-बहुत से।
- गणना: एक संबंध में शामिल उदाहरणों की न्यूनतम और अधिकतम संख्या निर्दिष्ट करता है।
पुनर्गठन के दौरान ERM का उपयोग करने से टीमों को उत्पादन वातावरण में बदलाव लागू करने से पहले उनका प्रतिरूपण करने में सक्षमता मिलती है। इससे प्रक्रिया के शुरुआती चरण में अनाथ डेटा, गायब बाधाएं और सामान्यीकरण की समस्याओं की पहचान करने में मदद मिलती है।
पुनर्गठन से पहले मूल्यांकन चरण 🔍
किसी भी मौजूदा तालिका को संशोधित करने से पहले एक विस्तृत ऑडिट की आवश्यकता होती है। इस चरण से यह सुनिश्चित करने में मदद मिलती है कि संक्रमण के दौरान कोई व्यावसायिक तर्क नहीं खोया जाता है।
- मौजूदा तालिकाओं का निरीक्षण: वर्तमान में प्रणाली में मौजूद प्रत्येक तालिका, कॉलम, सूचकांक और बाधा का दस्तावेजीकरण करें।
- प्रश्न पैटर्न का विश्लेषण करें: यह पहचानें कि कौन से प्रश्न सबसे अधिक बार चलते हैं और कौन सी तालिकाएं सबसे अधिक बार पढ़ी जाती हैं।
- डेटा निर्भरता का नक्शा बनाएं: यह ट्रेस करें कि डेटा डेटाबेस से एप्लिकेशन तक और वापस कैसे बहता है।
- आवर्धित कॉलम की पहचान करें: ऐसे कॉलम खोजें जो एक से अधिक तालिकाओं में एक ही जानकारी संग्रहीत करते हैं।
- विदेशी कुंजियों की समीक्षा करें: यह तय करें कि संबंधों को डेटाबेस स्तर पर लागू किया जाता है या कोड में प्रबंधित किया जाता है।
इस मूल्यांकन से एक आधार रेखा बनती है। इसके बिना, पुनर्गठन ऐसी छोटी त्रुटियों को ला सकता है जिन्हें बाद में ट्रैक करना मुश्किल होता है।
पुनर्गठन प्रक्रिया: चरण दर चरण 🔄
एक एकल रूप वाले स्कीमा को एक ब्लॉक आधारित संरचना में बदलने के लिए एक व्यवस्थित दृष्टिकोण की आवश्यकता होती है। निम्नलिखित चरण एंटिटी रिलेशनशिप मॉडलिंग के उपयोग से स्कीमा पुनर्गठन के मानक कार्य प्रवाह को चित्रित करते हैं।
1. क्षेत्र-आधारित डिज़ाइन (DDD) संरेखण
व्यावसायिक क्षेत्रों के आधार पर तालिकाओं को समूहित करके शुरुआत करें। इसे अक्सर सीमित संदर्भ कहा जाता है। फ़ंक्शन के आधार पर तालिकाओं को व्यवस्थित करने के बजाय (जैसे रिपोर्टिंग के लिए सभी तालिकाएं), क्षमता के आधार पर व्यवस्थित करें (जैसे बिलिंग के लिए तालिकाएं, प्रमाणीकरण के लिए तालिकाएं)। इस विभाजन से प्रणाली के असंबंधित हिस्सों के बीच कपलिंग कम होती है।
2. सामान्यीकरण
सामान्यीकरण डेटा अतिरेक को कम करता है और अखंडता में सुधार करता है। इस प्रक्रिया में बड़ी तालिकाओं को छोटी, तार्किक रूप से संबंधित तालिकाओं में तोड़ा जाता है।
- पहला सामान्य रूप (1NF): परमाणु मान सुनिश्चित करें। प्रत्येक कॉलम में केवल एक मान होना चाहिए।
- दूसरा सामान्य रूप (2NF): आंशिक निर्भरता हटाएं। सभी गैर-कुंजी विशेषताओं को पूर्ण मुख्य कुंजी पर निर्भर होना चाहिए।
- तीसरा सामान्य रूप (3NF): स्थानांतरित निर्भरता हटाएं। गैर-कुंजी विशेषताओं को अन्य गैर-कुंजी विशेषताओं पर निर्भर नहीं होना चाहिए।
जबकि 3NF मानक लक्ष्य है, कुछ प्रदर्शन आवश्यकताएं नियंत्रित अनियमितता की आवश्यकता हो सकती है। इस निर्णय को दस्तावेज़ित करना चाहिए।
3. नए संबंधों को परिभाषित करना
जब तालिकाओं को विभाजित कर लिया जाता है, तो संबंधों को पुनः स्थापित करना आवश्यक होता है। इसमें बहु-से-बहु संबंधों के लिए नए विदेशी कुंजियों और जंक्शन तालिकाओं का निर्माण शामिल होता है। उदाहरण के लिए, यदि एक उत्पाद कई के साथ संबंधित हो सकता है श्रेणियाँतो उन्हें जोड़ने के लिए एक जंक्शन तालिका की आवश्यकता होती है।
4. डेटा स्थानांतरण रणनीति
पुराने स्कीमा से नए में डेटा स्थानांतरित करना सबसे जोखिम भरा चरण है। रणनीतियाँ शामिल हैं:
- स्नैपशॉट स्थानांतरण:लेखन रोकें, डेटा निर्यात करें, परिवर्तित करें, और नए स्कीमा में आयात करें। बंद अवधि की आवश्यकता होती है।
- दोहरा लेखन: संक्रमण अवधि के दौरान पुराने और नए स्कीमा दोनों में एक साथ लेखन करें।
- लॉग-आधारित प्रतिलिपि: डेटाबेस लेनदेन लॉग से परिवर्तनों को कैप्चर करें और उन्हें नए संरचना में लागू करें।
बचने के लिए सामान्य त्रुटियाँ 🛑
रीफैक्टरिंग जटिलता लाती है। कुछ गलतियाँ प्रणाली की अखंडता को खतरे में डाल सकती हैं।
- डेटा प्रकारों के बारे में ध्यान न देना: कॉलम को पूर्णांक से स्ट्रिंग नीचे के तरीके के बिना जांच किए बदलने से एप्लिकेशन कोड टूट सकता है।
- अत्यधिक सामान्यीकरण: बहुत सारी तालिकाओं का निर्माण करने से अत्यधिक जॉइन हो सकते हैं, जिससे प्रश्न प्रदर्शन में गिरावट आती है।
- प्रतिबंधों का नुकसान: डेटाबेस से एप्लिकेशन लेयर में प्रतिबंधों को हटाने से डेटा की खराबी हो सकती है यदि कई सेवाएं एक ही डेटा में लेखन करती हैं।
- सूचकांक की उपेक्षा: नई तालिकाओं के लिए नए सूचकांक की आवश्यकता होती है। नए विदेशी कुंजियों को सूचकांकित करने के लिए विफल रहने से जॉइन ऑपरेशन धीमे हो जाएंगे।
सत्यापन और परीक्षण रणनीतियाँ ✅
स्कीमा के डिज़ाइन के बाद, सत्यापन महत्वपूर्ण है। स्वचालित परीक्षणों को यह सुनिश्चित करना चाहिए कि डेटा अखंडता नए सीमाओं के आसपास बनी रहे।
- डेटा सुसंगतता जांच: सभी नए संबंधों के आसपास संदर्भात्मक अखंडता को बनाए रखने के लिए प्रश्नों को चलाएं।
- प्रदर्शन बेंचमार्किंग: पुनर्गठन से पहले और बाद में प्रश्न निष्पादन समय की तुलना करें।
- पंक्ति संख्या सत्यापन: सुनिश्चित करें कि कुल रिकॉर्ड की संख्या स्थिर रहे (मार्गीकरण के दौरान बनाए गए डुप्लिकेट को छोड़कर)।
- एप्लिकेशन रिग्रेशन परीक्षण: नए डेटाबेस संरचना के खिलाफ एप्लिकेशन परीक्षणों के पूरे सेट को चलाएं।
तुलना: मोनोलिथिक बनावट बनाम मॉड्यूलर स्कीमा
नीचे दी गई तालिका में पुरानी मोनोलिथिक संरचना और पुनर्गठित मॉड्यूलर दृष्टिकोण के बीच अंतरों को चित्रित किया गया है।
| विशेषता | मोनोलिथिक स्कीमा | पुनर्गठित स्कीमा |
|---|---|---|
| तालिका संरचना | बड़ी, मिश्रित उद्देश्य वाली तालिकाएं | विशेषज्ञता वाली, क्षेत्र-विशिष्ट तालिकाएं |
| डेटा अतिरेक | उच्च | नॉर्मलाइजेशन के माध्यम से न्यूनतम किया गया |
| स्केलेबिलिटी | शार्डिंग करना कठिन | क्षेत्र के आधार पर विभाजित करना आसान |
| डेप्लॉयमेंट | सार्वभौमिक स्कीमा परिवर्तन | स्थानीयकृत स्कीमा अपडेट |
| प्रश्न जटिलता | बड़ी तालिकाओं पर जटिल जॉइन | छोटी तालिकाओं पर अनुकूलित जॉइन |
माइक्रोसर्विसेज आर्किटेक्चर की ओर संक्रमण 🚀
स्कीमा को पुनर्गठन आमतौर पर माइक्रोसर्विसेज को अपनाने के पूर्वाभास होता है। एक साफ एंटिटी रिलेशनशिप मॉडल के कारण विशिष्ट डेटा के मालिकाना हक को विशिष्ट सेवाओं को नियुक्त करना आसान हो जाता है। जब प्रत्येक सेवा अपने अपने डेटाबेस का प्रबंधन करती है, तो स्कीमा सेवाओं के बीच एक संविदा बन जाती है, बजाय एक साझा संसाधन के।
इस परिवर्तन के लिए डेटा सुसंगतता के सावधानीपूर्वक प्रबंधन की आवश्यकता होती है। एक से अधिक डेटाबेस के बीच लेनदेन के बजाय, प्रणालियाँ अंततः सुसंगतता पैटर्न पर निर्भर कर सकती हैं। ईआरएम इन सीमाओं को स्पष्ट रूप से परिभाषित करने में मदद करता है, जिससे यह सुनिश्चित होता है कि कोई भी सेवा उस डेटा के मालिकाना हक को नहीं मानती है जिसका वह प्रबंधन नहीं करती है।
लंबे समय तक स्वास्थ्य के लिए अंतिम विचार 🛡️
एक स्वस्थ स्कीमा को बनाए रखने के लिए निरंतर अनुशासन की आवश्यकता होती है। जब भी कोई टेबल जोड़ी या संशोधित की जाती है, तो दस्तावेज़ीकरण को अपडेट करना चाहिए। स्कीमा परिभाषाओं पर संस्करण नियंत्रण लागू करना चाहिए, बस एप्लिकेशन कोड के बजाय। फीचर्स जोड़े जाने पर नए जोड़े के उदाहरणों को पहचानने के लिए नियमित समीक्षा की योजना बनाई जानी चाहिए।
एंटिटी रिलेशनशिप मॉडलिंग एक बार के कार्य की तरह नहीं है। यह एक निरंतर अभ्यास है जो सुनिश्चित करता है कि डेटाबेस व्यापार की आवश्यकताओं के साथ समान रहे। इन संरचित चरणों का पालन करके संगठन लीगेसी डेटा संरचनाओं से जुड़े जोखिमों को कम कर सकते हैं और भविष्य के विकास को समर्थन करने में सक्षम आधार बना सकते हैं।
एक मोनोलिथिक स्कीमा से मॉड्यूलर डिज़ाइन में संक्रमण एक महत्वपूर्ण कार्य है। इसके लिए धैर्य, कठोर परीक्षण और डेटा संबंधों की गहन समझ की आवश्यकता होती है। हालांकि, परिणाम एक ऐसी प्रणाली है जो रखरखाव के लिए आसान है, स्केल करने में तेज है, और परिवर्तन के प्रति अधिक लचीली है। मॉडलिंग में निवेश की गई मेहनत लंबे समय तक ऑपरेशनल स्थिरता और डेवलपर वेलोसिटी में लाभ देती है।