










Seiring akumulasi data semakin cepat, arsitektur skema basis data Anda menjadi penentu krusial stabilitas sistem. Ketika suatu aplikasi beralih dari operasi baca yang berat ke beban kerja tulisan yang berat, Diagram Hubungan Entitas (ERD) standar sering kali memerlukan penyesuaian signifikan. Mendesain untuk throughput tinggi melibatkan lebih dari sekadar menambah indeks; ini menuntut pemikiran ulang mendasar tentang bagaimana data disusun, dihubungkan, dan disimpan. Panduan ini mengeksplorasi perubahan arsitektur yang diperlukan untuk mempertahankan kinerja di bawah tekanan tanpa mengorbankan integritas data.
Memahami Beban Kerja Tulisan yang Berat 📈
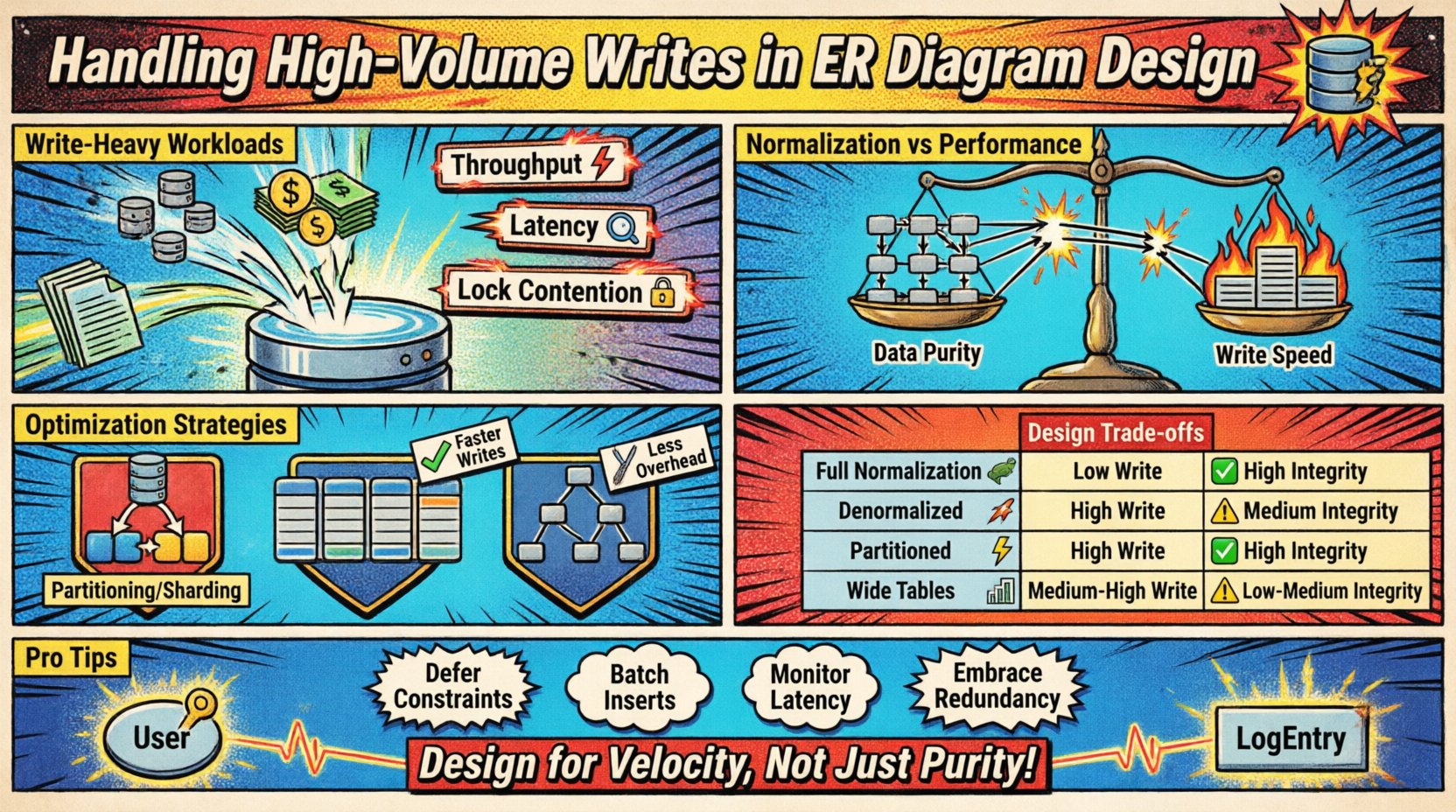
Skenario tulisan volume tinggi terjadi ketika laju data masuk melebihi kapasitas teknik normalisasi standar. Hal ini sering terjadi dalam sistem pencatatan, aliran data sensor IoT, buku jurnal transaksi keuangan, atau platform analitik real-time. Tantangan utama terletak pada menyeimbangkan kecepatan penyisipan terhadap persyaratan konsistensi model.
- Throughput: Jumlah operasi tulisan yang diproses per detik.
- Latensi: Waktu yang dibutuhkan untuk berhasil menyimpan sebuah catatan.
- Persaingan Kunci: Persaingan sumber daya ketika beberapa proses berusaha mengubah data yang sama.
Ketika metrik-metrik ini menurun, skema itu sendiri sering kali menjadi hambatan utama. Desain yang kaku yang dioptimalkan untuk query kompleks dapat runtuh di bawah beban pembaruan terus-menerus. Oleh karena itu, ERD awal harus mempertimbangkan kecepatan masuk data.
Normalisasi vs. Pertukaran Kinerja ⚖️
Desain basis data tradisional mendorong normalisasi (1NF, 2NF, 3NF) untuk mengurangi redundansi. Meskipun ini menghemat ruang penyimpanan dan menjamin konsistensi, hal ini menimbulkan beban tambahan selama operasi tulisan. Setiap hubungan kunci asing memerlukan pencarian dan pemeriksaan join untuk menjaga integritas referensial.
Dalam lingkungan volume tinggi, pemeriksaan-pemeriksaan ini menjadi mahal. Pertimbangkan implikasi dari hubungan banyak-ke-banyak selama kejadian tulisan:
- Tabel utama harus diperbarui.
- Tabel sambungan harus menyisipkan baris baru.
- Tabel kedua harus memverifikasi hubungan tersebut.
- Log transaksi harus mencatat semua perubahan.
Setiap langkah menambah I/O disk dan siklus CPU. Untuk menangani beban tulisan berat, desainer sering kali melonggarkan aturan normalisasi. Proses ini melibatkan penerimaan redundansi data untuk mengurangi jumlah operasi tulisan yang diperlukan untuk menyimpan satu unit informasi.
Strategi untuk Mengoptimalkan Kecepatan Tulisan ✍️
Beberapa pola struktural ada untuk mengurangi tekanan tulisan. Strategi-strategi ini berfokus pada meminimalkan jejak setiap transaksi dan mengurangi kompleksitas pekerjaan mesin penyimpanan.
1. Partisi dan Sharding
Membagi tabel besar menjadi bagian-bagian kecil yang lebih mudah dikelola memungkinkan basis data mendistribusikan beban tulisan ke berbagai segmen fisik atau logis.
- Partisi Horizontal: Membagi baris berdasarkan kunci (misalnya, rentang tanggal, ID pengguna).
- Partisi Vertikal: Memindahkan kolom yang jarang diakses ke tabel terpisah.
- Sharding: Mendistribusikan data di seluruh beberapa instance basis data.
Pendekatan ini mengurangi ukuran indeks yang harus dipertahankan dan membatasi cakupan kunci selama operasi tulisan. Jika satu shard menjadi jenuh, yang lain tetap tidak terpengaruh.
2. Taktik Denormalisasi
Menyimpan data yang berulang memungkinkan sistem menghindari penggabungan saat menulis. Sebagai contoh, alih-alih menghitung jumlah total dari baris yang terkait setiap kali transaksi baru datang, sistem dapat langsung memperbarui kolom ringkasan yang telah dihitung sebelumnya.
- Kolom yang Dihitung: Simpan nilai yang dihasilkan langsung dalam baris.
- Tampilan yang Dibuat Nyata: Hitung hasil terlebih dahulu untuk agregasi yang sering terjadi.
- Penghitung yang Dicache: Pertahankan tabel penghitung terpisah untuk statistik.
Meskipun ini meningkatkan kebutuhan penyimpanan, hal ini secara signifikan menurunkan biaya CPU saat penyisipan.
3. Strategi Indeks
Indeks mempercepat pembacaan tetapi memperlambat penulisan. Setiap kali baris dimasukkan, basis data harus memperbarui setiap indeks yang terkait. Dalam lingkungan penulisan tinggi, pembengkakan indeks menjadi masalah utama.
- Minimalkan Jumlah Indeks: Hanya indeks kolom yang digunakan untuk penyaringan atau penggabungan.
- Indeks Parsial: Indeks hanya sebagian baris yang sering diakses.
- Hindari Indeks Berlebihan: Lewati indeks pada kolom yang sering berubah.
Membandingkan Pendekatan Desain 📑
Tabel di bawah ini menjelaskan dampak pilihan struktural yang berbeda terhadap kinerja penulisan dan integritas data.
| Strategi | Kinerja Penulisan | Integritas Data | Biaya Penyimpanan | Kasus Penggunaan Terbaik |
|---|---|---|---|---|
| Normalisasi Penuh | Rendah | Tinggi | Rendah | Pelaporan kompleks, volume penulisan rendah |
| Denormalisasi | Tinggi | Sedang | Tinggi | Aliran real-time, volume tulis tinggi |
| Skema Terbagi | Tinggi | Tinggi | Sedang | Data deret waktu, dataset besar |
| Tabel Lebar | Sedang-Tinggi | Sedang | Sedang | Pola NoSQL, data jarang |
Menangani Kunci Asing dan Kendala 🔗
Integritas referensial adalah fondasi desain relasional, tetapi menerapkan kendala pada setiap penyisipan dapat menghambat aliran data berkecepatan tinggi. Mesin basis data harus memverifikasi bahwa baris induk yang dirujuk ada sebelum menerima baris anak.
Dalam skenario di mana integritas data sangat penting tetapi kecepatan tulis menjadi prioritas utama, pertimbangkan penyesuaian berikut:
- Kendala Ditunda:Validasi hubungan pada akhir transaksi, bukan segera.
- Pemeriksaan Tingkat Aplikasi:Verifikasi hubungan dalam kode aplikasi sebelum mengirim data ke basis data.
- Hapus Lunak:Tandai catatan sebagai tidak aktif alih-alih menghapusnya untuk mempertahankan tautan referensial tanpa beban penghapusan.
Menghapus kendala sepenuhnya berisiko, tetapi memindahkan logika validasi kadang-kadang dapat meningkatkan throughput. Keputusan ini tergantung pada seberapa penting konsistensi segera bagi alur kerja spesifik Anda.
Amplifikasi Tulis dan Mesin Penyimpanan 💾
Memahami bagaimana mesin penyimpanan menangani data sangat penting. Banyak mesin menggunakan Log Tulis Terlebih Dahulu (WAL) untuk menjamin ketahanan. Ini berarti setiap operasi tulis dicatat terlebih dahulu sebelum diterapkan pada file data sebenarnya.
Amplifikasi Tulisterjadi ketika satu operasi tulis logis menghasilkan beberapa operasi tulis fisik. Ini umum terjadi pada mesin penyimpanan yang berat kompaksi. Untuk mengelolanya:
- Sisipan Batch:Kelompokkan beberapa baris menjadi satu transaksi.
- Tulisan Berurutan:Desain skema untuk mendukung generasi kunci berurutan daripada penyisipan acak.
- Penyimpanan Sementara:Izinkan buffer sementara di lapisan aplikasi untuk menunda penulisan sebelum dibersihkan.
Dengan menyelaraskan desain ERD dengan kekuatan mesin penyimpanan, Anda dapat meminimalkan usaha fisik yang diperlukan untuk mempertahankan data.
Pemantauan dan Iterasi 🔄
Skema yang dirancang untuk tulisan tinggi tidak bersifat statis. Saat pola lalu lintas berubah, desain mungkin perlu berkembang. Pemantauan berkelanjutan terhadap latensi tulisan dan I/O disk sangat penting.
- Lacak Latensi Tulisan:Identifikasi lonjakan yang menunjukkan kemacetan.
- Pantau Waktu Tunggu Kunci:Deteksi titik persaingan di mana proses diblokir.
- Analisis Penggunaan Indeks:Hapus indeks yang tidak pernah digunakan untuk mengurangi beban tulisan.
Audit rutin terhadap ERD memastikan struktur tetap selaras dengan kebutuhan operasional saat ini. Jika suatu tabel tertentu terus-menerus mengalami kesulitan dalam throughput tulisan, mungkin saatnya meninjau kembali strategi partisi atau tingkat normalisasi.
Ringkasan Pertimbangan Utama 🛠️
Mendesain ERD untuk tulisan volume tinggi membutuhkan perubahan pola pikir dari kemurnian data murni menuju throughput sistem. Poin-poin berikut merangkum tindakan penting:
- Audit Normalisasi:Pastikan setiap hubungan menambah nilai, bukan hanya kompleksitas.
- Rencanakan untuk Partisi:Struktur kunci agar memungkinkan pemisahan horizontal yang mudah.
- Batasi Indeks:Jaga jalur tulisan seefisien mungkin.
- Terima Redundansi:Gunakan denormalisasi untuk mengurangi ketergantungan join saat penyisipan.
- Validasi Secara Bertahap:Pindahkan pemeriksaan keterbatasan keluar dari jalur tulisan kritis jika aman.
Dengan menerapkan prinsip-prinsip ini, Anda menciptakan model data yang mampu menopang pertumbuhan tanpa mengorbankan kinerja. Tujuannya bukan menghilangkan kompleksitas, tetapi mengelolanya dengan cara yang mendukung kecepatan aplikasi Anda.