











Dans les architectures de données modernes, la vitesse à laquelle les informations sont récupérées détermine souvent l’utilisabilité d’une application. Bien que les mises à niveau matérielles et les stratégies de mise en cache jouent un rôle important, la base de la performance réside dans la structure des données elle-même. Plus précisément, la conception des modèles d’entités relationnelles (ERMs) détermine avec quelle efficacité un moteur de base de données peut parcourir, joindre et agréger les données. Un schéma optimisé ne se contente pas d’organiser les informations ; il guide l’optimiseur de requêtes vers des chemins d’exécution plus rapides. 📉
Ce guide explore les mécanismes techniques derrière la conception des schémas et leur corrélation directe avec les performances des requêtes. Nous examinerons comment les niveaux de normalisation, la cardinalité des relations et les stratégies d’indexation interagissent dans le plan d’exécution des requêtes. En comprenant ces dynamiques, les développeurs et les architectes de bases de données peuvent concevoir des systèmes évolutifs sans compromettre l’intégrité ni la vitesse.
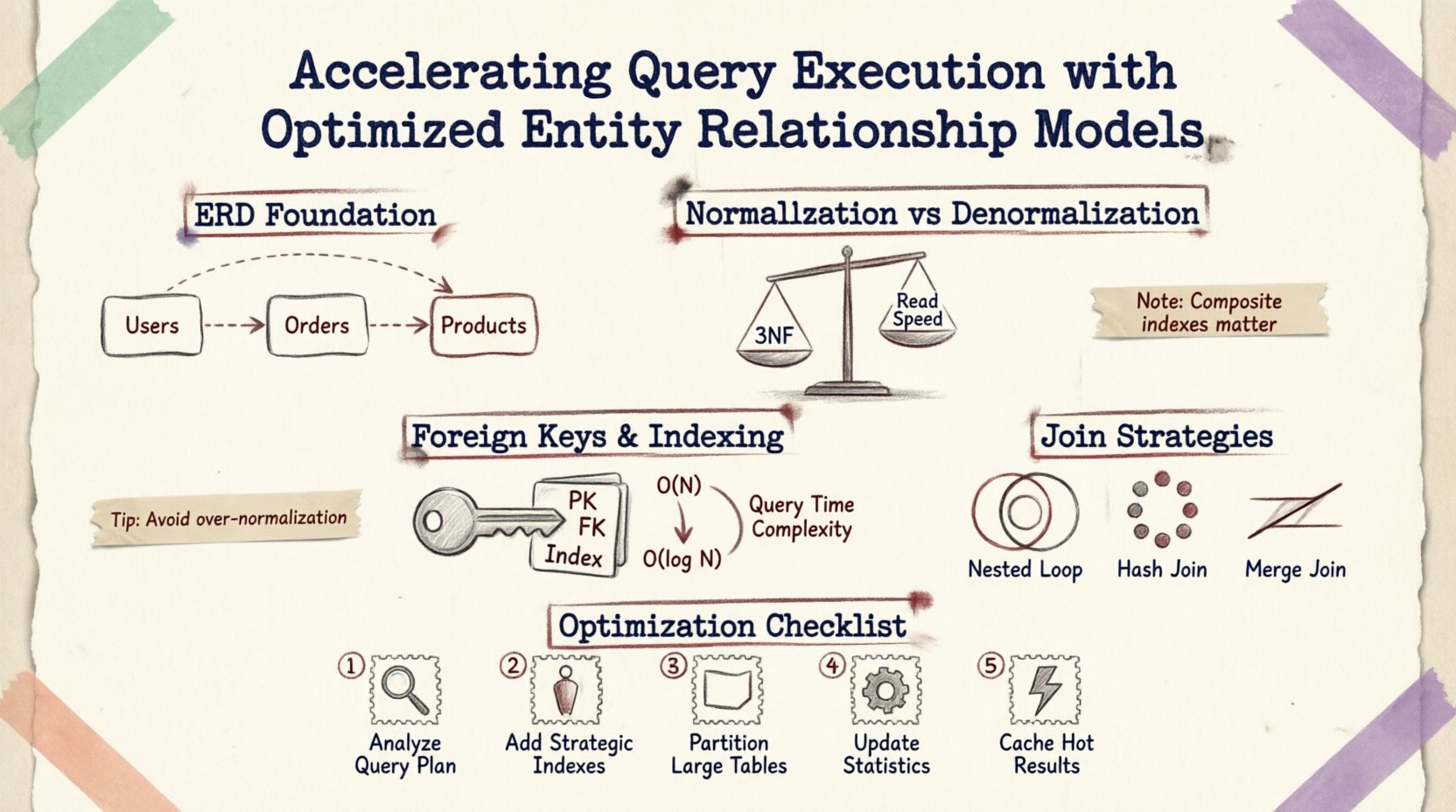
Comprendre la fondation : les diagrammes entité-association et les performances 🗃️
Un diagramme entité-association est bien plus qu’un outil visuel pour la documentation ; il constitue un plan directeur pour la logique de stockage physique et de récupération des données. Chaque ligne tracée entre les tables représente une contrainte de clé étrangère, une opération de jointure ou une règle d’intégrité des données. Lorsqu’une requête est soumise, le moteur de base de données interprète ces relations afin de construire un plan d’exécution.
Prenons une requête simple demandant les commandes des utilisateurs et les détails des produits. Le moteur doit :
- Localiser la table
Userstable. - Suivre la clé étrangère vers la table
Orderstable. - Joindre la table
OrderItemstable. - Accéder à la table
Productstable via une autre relation.
Chaque étape implique des opérations d’E/S et des cycles de processeur. Si les relations sont mal définies, le moteur peut être amené à effectuer des analyses de table entière ou des jointures imbriquées qui dégradent les performances de manière exponentielle. Optimiser l’ERD réduit la distance que les données doivent parcourir du disque à la mémoire.
Normalisation vs. Dénormalisation : Trouver l’équilibre ⚖️
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Bien qu’essentielle pour la cohérence, une normalisation excessive peut fragmenter les données sur de nombreuses petites tables, nécessitant des jointures complexes qui ralentissent les opérations intensives en lecture.
Le coût de la normalisation approfondie
Lorsqu’un schéma est normalisé jusqu’à la Troisième Forme Normale (3FN), les données sont stockées dans leur état le plus atomique. Cela minimise l’espace de stockage et les anomalies de mise à jour. Toutefois, la récupération des données associées nécessite souvent le parcours de plusieurs clés étrangères.
- Surcharge de jointure : Chaque table supplémentaire dans une chaîne de jointure augmente la complexité du plan de requête.
- Contestation de verrouillage : L’accès à plusieurs tables augmente la probabilité de conflits de verrouillage au niveau des lignes.
- Utilisation du CPU : Le moteur de base de données doit fusionner les jeux de résultats provenant de tables différentes.
Quand dénormaliser
La dénormalisation introduit une redondance afin d’optimiser les performances de lecture. Cela est souvent nécessaire dans les environnements de traitement analytique ou de reporting à fort trafic.
- Charge de travail orientée lecture : Si les écritures sont peu fréquentes par rapport aux lectures, l’ajout d’une colonne dénormalisée permet d’économiser des opérations de jointure.
- Agrégats précalculés : Stocker les totaux (par exemple,
total_order_value) dans la table utilisateur évite de calculer les sommes à chaque requête. - Partitionnement horizontal : Garder les données fréquemment consultées ensemble améliore la localité du cache.
Cependant, la dénormalisation nécessite une gestion soigneuse afin d’éviter les incohérences de données. La logique d’application doit garantir que les données redondantes sont mises à jour chaque fois que les données sources changent.
Clés étrangères et stratégie d’indexation 🔑
Les contraintes de clés étrangères garantissent l’intégrité référentielle, mais elles ont un coût en performance. La base de données doit vérifier qu’une valeur dans une table existe dans une autre avant d’autoriser une insertion ou une mise à jour. Optimiser la manière dont ces clés sont indexées est crucial.
Indexation des clés étrangères
Par défaut, les clés primaires sont automatiquement indexées. Les clés étrangères, en revanche, nécessitent souvent des index explicites pour accélérer les opérations de jointure. Sans index sur une colonne de clé étrangère :
- La base de données doit effectuer un balayage complet de la table enfant pour trouver les lignes correspondantes.
- Les opérations de jointure deviennent considérablement plus lentes, surtout lorsque la taille des tables atteint des millions de lignes.
- Les vérifications d’intégrité référentielle lors de la suppression deviennent coûteuses.
Une clé étrangère correctement indexée permet à la base de données d’utiliser une recherche d’index au lieu d’un balayage, réduisant la complexité de O(N) à O(log N).
Index composés pour les relations
Lorsque plusieurs colonnes définissent une relation, un index composé peut être plus efficace qu’un index individuel. Par exemple, si une requête filtre par user_id et created_at dans une table de commande, un index composé sur ces deux colonnes garantit que le moteur peut localiser les données sans balayer des enregistrements non liés.
Stratégies de jointure et plans d’exécution 🔍
La structure du schéma ERD influence les algorithmes de jointure choisis par l’optimiseur de requêtes. Comprendre ces mécanismes aide à concevoir des schémas favorisant des types de jointure efficaces.
| Type de jointure | Utilisé idéalement lorsque | Impact sur les performances |
|---|---|---|
| Jointure en boucle imbriquée | Jeunes jeux de résultats ou prédicats très sélectifs | Rapide pour de petites données ; lent pour les grandes analyses |
| Jointure par hachage | Grandes tables sans index | Intensif en mémoire ; bon pour les données non triées |
| Jointure par fusion | Entrées triées sur les clés de jointure | Très rapide si les données sont déjà triées |
Concevoir le MCD pour soutenir des entrées triées ou des recherches indexées peut inciter l’optimiseur à choisir des méthodes de jointure plus rapides. Par exemple, garantir que les clés de jointure font partie d’un index clusterisé peut faciliter les jointures par fusion.
Péchés courants dans la conception de schémas 🚫
Même les architectes expérimentés commettent des erreurs qui affectent la vitesse des requêtes. Identifier ces modèles tôt évite des refonte coûteuses plus tard.
- Clés étrangères en chaîne : Créer une chaîne de relations où la table A est liée à B, B à C, et C à D. Les requêtes joignant les quatre tables deviennent profondément imbriquées et lentes.
- Chaînes de longueur variable : Utilisation de
VARCHARpour des clés toujours de longueur fixe peut gaspiller de l’espace et ralentir les comparaisons de lignes. - Multiples à multiples sans tables de jonction : Tenter de stocker plusieurs ID dans une seule colonne (par exemple, des valeurs séparées par des virgules) empêche un indexage et une normalisation adéquats.
- Conversions implicites : Définir des types de données incompatibles entre les tables parentes et enfants oblige le moteur à convertir les valeurs en temps réel, empêchant l’utilisation des index.
Étapes pratiques pour l’optimisation 🛠️
Pour améliorer l’exécution des requêtes sans réécrire l’ensemble du système, suivez ces étapes structurées :
- Analyser les modèles de requêtes : Revue des opérations de lecture les plus fréquentes. Identifier les tables jointes le plus souvent.
- Revoir l’utilisation des index : Vérifier la présence d’index manquants sur les clés étrangères ou les colonnes fréquemment filtrées.
- Affiner la cardinalité : Assurer que les relations sont correctement modélisées (un à un vs. un à plusieurs). Une cardinalité incorrecte peut entraîner des jointures inutiles.
- Partitionner les grandes tables : Si une table dépasse plusieurs millions de lignes, envisagez de la partitionner par date ou région afin de limiter les données analysées par requête.
- Surveillance des verrous : Utilisez des outils de surveillance pour identifier les requêtes longues qui détiennent des verrous, souvent causées par une navigation inefficace dans le schéma.
Considérations sur le stockage et la mémoire 💾
La disposition physique des données joue également un rôle. Les moteurs de base de données stockent les données par pages. Si les lignes liées sont stockées physiquement proches les unes des autres, moins de lectures disque sont nécessaires pour charger un jeu de données.
- Regroupement :Organiser les données par une clé commune peut améliorer les recherches par plage.
- Stockage par colonnes vs. stockage par lignes : Pour les requêtes analytiques, le stockage par colonnes peut offrir une meilleure compression et des agrégations plus rapides que les modèles traditionnels par lignes.
- Mise en cache : Concevez des schémas qui permettent un cache efficace de l’ensemble des résultats plutôt que de lignes individuelles.
Dernières réflexions sur l’évolution du schéma 🔄
La conception du schéma n’est pas une tâche ponctuelle. À mesure que les exigences de l’application évoluent, le modèle de données doit évoluer également. Une vérification régulière de la structure de la base de données garantit que les performances restent stables. La documentation du modèle d’entités et de relations doit être maintenue conjointement avec le code source afin de suivre l’impact des modifications sur le système.
En vous concentrant sur l’intégrité structurelle et les relations logiques au sein des données, vous créez une fondation qui soutient l’exécution rapide des requêtes. L’objectif n’est pas de construire un système statique, mais une architecture souple qui s’adapte à la charge sans sacrifier la vitesse que les utilisateurs attendent. 📊
Optimiser le modèle d’entités et de relations est une discipline technique qui allie théorie des bases de données et ingénierie pratique. Elle exige de la patience, une analyse rigoureuse et une compréhension claire de la manière dont le moteur sous-jacent traite les requêtes. Avec la bonne approche, les problèmes de performance deviennent gérables, et la récupération des données devient fluide.