











Les systèmes logiciels évoluent. Ce qui a commencé comme un simple script grandit souvent en un réseau complexe de dépendances, de logique cachée et de chemins d’exécution entremêlés. Cette accumulation de dette technique crée un état souvent décrit comme du chaos. Les développeurs se retrouvent à naviguer à travers des couches d’abstraction, incertains quant au flux des données depuis le point d’entrée jusqu’à la base de données. La solution ne réside pas uniquement dans la réécriture du code, mais dans la visualisation de l’architecture existante. Un diagramme de séquence UML (langage unifié de modélisation) offre une méthode structurée pour cartographier ces interactions. En procédant à une ingénierie inverse du code, les équipes peuvent transformer une logique opaque en plans clairs et communicatifs.
Ce guide décrit la méthodologie pour extraire de l’ordre du désordre. Il se concentre sur le processus technique d’observation de l’exécution du code afin de construire des diagrammes de séquence précis. L’objectif est la clarté, la maintenabilité et une compréhension partagée parmi les parties prenantes. Nous explorerons les mécanismes d’interaction entre objets, l’importance du timing, et les étapes nécessaires pour documenter ces flux sans introduire de nouvelles erreurs.
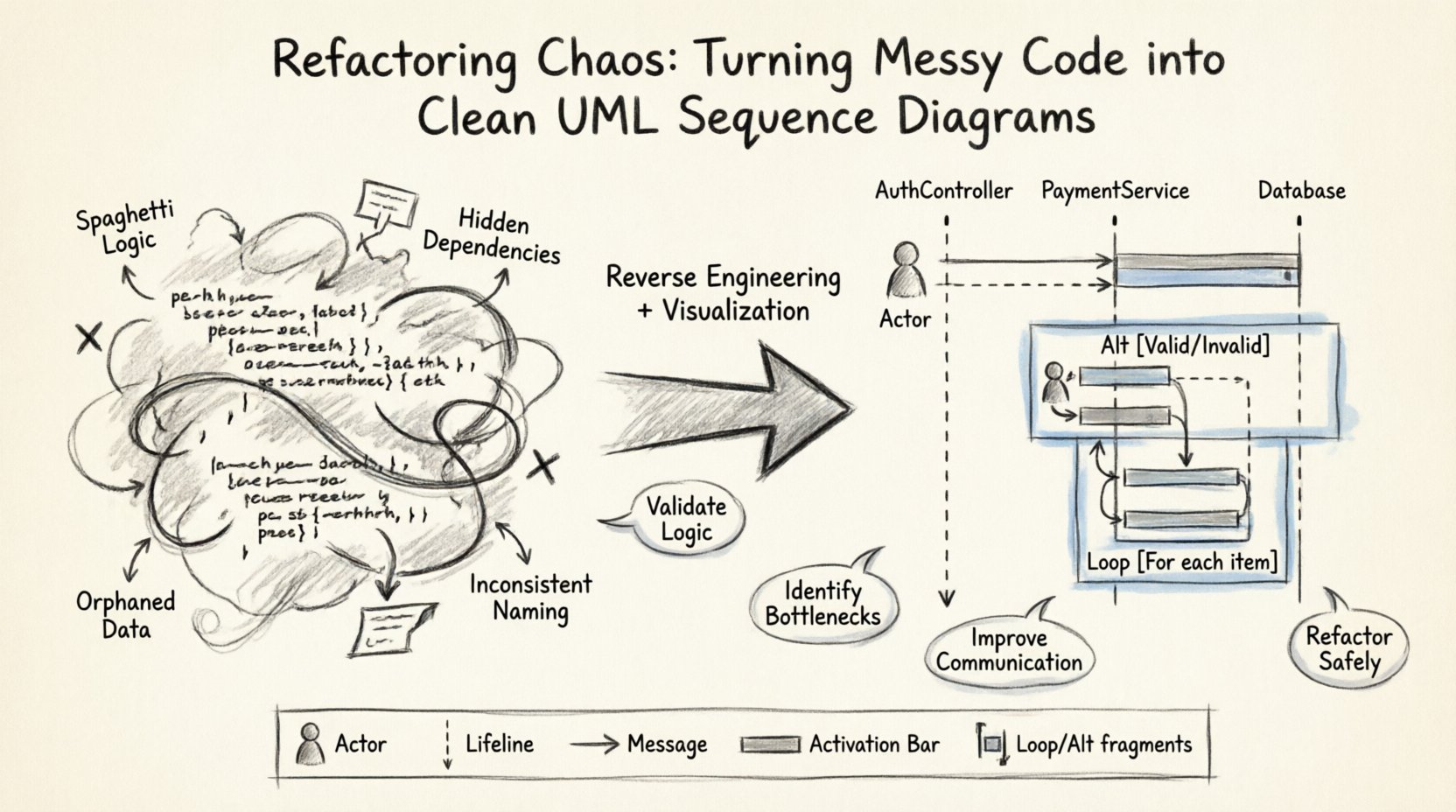
Comprendre l’état du chaos 🌪️
Avant de pouvoir réparer un système, il faut comprendre la nature du désordre. Un code désordonné présente souvent des caractéristiques spécifiques qui masquent le flux de contrôle. Ces traits ne sont pas uniquement esthétiques ; ils représentent des faiblesses structurelles qui entravent le développement futur.
- Logique spaghetti : Des fonctions qui s’appellent les unes les autres de manière non linéaire et profondément imbriquée.
- Dépendances cachées : Des services ou modules instanciés de manière implicite au sein de méthodes, rendant difficile le suivi de leurs cycles de vie.
- Données orphelines : Des informations transmises sans propriétaire clair ni gestion du cycle de vie.
- Nommage incohérent : Des noms de variables et de méthodes qui ne reflètent pas leur véritable fonction ou les données qu’ils contiennent.
Lorsqu’un code possède ces caractéristiques, un développeur qui tente d’ajouter une fonctionnalité se retrouve souvent à deviner. Il insère de la logique ici et là, en espérant qu’elle fonctionne. Cela entraîne des bogues de régression et une dégradation supplémentaire. Un diagramme de séquence agit comme une carte. Il oblige l’auteur à reconnaître chaque participant dans une interaction spécifique. Il révèle où le système passe du temps et où il attend.
Prenons un module hérité typique. Une requête arrive. Elle atteint un contrôleur, qui appelle un service. Le service interroge un répertoire. Une base de données renvoie les résultats. Le service les transforme et les renvoie au contrôleur. Dans le code, cela pourrait être réparti sur dix fichiers. Dans un diagramme, c’est un flux vertical du haut vers le bas. La représentation visuelle réduit la charge cognitive nécessaire pour comprendre le système.
La valeur des diagrammes de séquence UML 📐
Pourquoi choisir un diagramme de séquence plutôt que d’autres formes de documentation ? D’autres diagrammes, comme les diagrammes de classes, montrent une structure statique. Ils vous indiquent quels objets existent et comment ils sont liés. Ils ne vous disent pas ce qui se passe lorsque le système s’exécute. Un diagramme de séquence capture le comportement dynamique. Il répond à la question :Que se passe-t-il lorsque cette action a lieu ?
Principaux avantages pour le refactoring
- Validation de la logique : En dessinant le flux, vous vérifiez si le code fait réellement ce qu’il est censé faire. Les écarts entre le diagramme et le code révèlent souvent des bogues.
- Identification des goulets d’étranglement : Des lignes verticales longues ou de nombreuses interactions entre objets mettent en évidence des problèmes de performance avant qu’ils ne deviennent critiques.
- Outil de communication : Un diagramme est une langue universelle. Il permet aux parties prenantes non techniques de comprendre le flux sans lire le code source.
- Sécurité du refactoring : Lorsqu’on modifie le code, le diagramme sert de référence. Si le nouveau code s’écarte du diagramme, le refactoring peut avoir introduit des effets secondaires non désirés.
Préparation : Mettre en place le cadre 🛠️
Construire un diagramme fiable exige une préparation. On ne peut pas simplement commencer à dessiner en lisant le code ligne par ligne. Une stratégie doit être en place. Le processus commence par définir le périmètre. Un diagramme de séquence peut représenter une application entière, mais il est souvent plus efficace de se concentrer sur un seul cas d’utilisation ou un chemin critique.
Définition du périmètre
Sélectionnez une transaction spécifique. Par exemple, « Connexion utilisateur » ou « Traitement du paiement ». Cela fournit un point de départ et un point d’arrivée clairs. Sans limites, le diagramme devient trop grand pour être lu. Le focus doit rester sur l’interaction entre les objets au cours de cette transaction spécifique.
Récolte du contexte
Avant d’ouvrir l’éditeur, comprenez le domaine. Quelles sont les entités impliquées ? Y a-t-il une API externe ? Y a-t-il une interface utilisateur ? Connaître le contexte aide à nommer correctement les lignes de vie. Des noms génériques comme « Objet 1 » ou « Gestionnaire » apportent peu de valeur. Des noms précis comme « AuthController » ou « PaymentGateway » transmettent un sens.
Le processus d’extraction : du code au diagramme 🔍
La tâche principale consiste en une ingénierie inverse. Cela implique de suivre le chemin d’exécution et de traduire les constructions de code en éléments de diagramme. Cela exige de la patience et une attention aux détails. Les étapes suivantes décrivent le flux de travail.
Étape 1 : Identifier les acteurs
Chaque interaction commence par une source. Dans un diagramme de séquence, cela est représenté par un Acteur. Les acteurs sont des entités externes qui initient le processus. Ils peuvent être des utilisateurs humains, d’autres systèmes ou des tâches planifiées.
- Utilisateurs humains :Représentés par l’icône standard de figure en bâton.
- Systèmes externes :Représentés par un rectangle étiqueté « Acteur » ou par un nom spécifique de système.
- Tâches planifiées :Représentés de manière similaire aux systèmes externes.
Commencez par localiser le point d’entrée dans le code. Il s’agit généralement de la méthode racine ou du gestionnaire de point d’entrée API. Cette méthode est le déclencheur de l’interaction.
Étape 2 : Cartographier les lignes de vie
Une fois l’acteur identifié, identifiez les objets participant au processus. Chaque objet reçoit une ligne de vie. Une ligne de vie est une ligne pointillée verticale s’étendant vers le bas à partir du nom de l’objet. Elle représente l’existence de cet objet au fil du temps.
Lorsque vous analysez le code, recherchez :
- Instanciation de classe :Où les objets sont-ils créés ? Ceux-ci deviennent des lignes de vie.
- Appels de méthode :Quelles méthodes sont appelées ? Cela indique quels objets sont actifs.
- Changements d’état :Quels objets détiennent les données en cours de traitement ?
Disposez les lignes de vie horizontalement. L’ordre doit refléter le flux logique. Généralement, l’initiateur est à gauche, et le stockage de données ou les dépendances externes sont à droite. Ce placement spatial facilite la lecture.
Étape 3 : Dessiner les messages
Les messages représentent la communication entre les lignes de vie. Ils sont dessinés sous forme de flèches horizontales. Il existe deux types principaux de messages à distinguer :
- Messages synchrones : L’appelant attend une réponse. Dans le code, cela ressemble à un appel de fonction standard. La flèche est pleine avec une tête remplie.
- Messages asynchrones : L’appelant ne patiente pas. Il envoie le signal et continue. Dans le code, cela pourrait être un déclencheur d’événement ou une tâche « déclencher et oublier ». La flèche est pointillée avec une tête ouverte.
Étiquetez chaque message avec le nom de la méthode ou l’action effectuée. Cela fournit le « verbe » de l’interaction. Par exemple, getUserById() ou validateToken().
Étape 4 : Représenter les barres d’activation
Une Barre d’activation (ou occurrence d’exécution) est un mince rectangle sur une ligne de vie. Elle indique quand un objet effectue une action. Elle montre la durée de l’opération.
Pour déterminer quand dessiner une barre d’activation :
- Commencez la barre lorsque le message est reçu.
- Terminez la barre lorsque la réponse est envoyée.
- Si l’objet s’appelle lui-même (appel récursif), la barre d’activation continue à travers le message self.
Ce repère visuel est crucial pour le restructurage. Il met en évidence les parties du code qui bloquent le thread. Si une barre d’activation est exceptionnellement longue, cela suggère un calcul intensif ou une opération d’E/S bloquante qui pourrait nécessiter une optimisation.
Gestion de la logique complexe 💻
Le code du monde réel suit rarement une ligne droite. Il contient des boucles, des conditions et une gestion des erreurs. Un diagramme de séquence doit représenter ces complexités pour rester précis.
Boucles et itérations
Si un processus implique une itération sur une collection, utilisez le fragment Boucle fragment. Il est dessiné comme une boîte avec le mot « Boucle » en haut. À l’intérieur de la boîte, placez les messages qui se répètent. Ajoutez une étiquette de condition (par exemple, « Pour chaque élément ») pour clarifier la portée.
Ne dessinez pas chaque itération individuellement. Cela encombrerait le diagramme. Le fragment de boucle indique que les messages inclus se répètent jusqu’à ce qu’une condition soit remplie.
Chemins conditionnels
Utilisez le fragment Alt (Alternative) pour la logique if-else. Cette boîte contient plusieurs sections, chacune portant une étiquette de condition (par exemple, « [Jeton valide] », « [Jeton invalide] »). Un seul chemin est suivi lors d’une exécution spécifique. Dessiner tous les chemins montre l’arbre décisionnel complet du système.
Gestion des exceptions
Les erreurs font partie du flux. Utilisez le Opt (Optimal) ou Exceptionfragment pour montrer ce qui se passe lorsque quelque chose échoue. Si une erreur est capturée et gérée correctement, montrez le chemin de récupération. Si elle se propage, montrez la flèche d’exception qui revient au appelant.
Ignorer les chemins d’erreur crée un faux sentiment de sécurité. Un diagramme robuste prend en compte les états d’échec.
Affiner le diagramme pour plus de clarté ✨
Une fois le brouillon initial terminé, le diagramme doit être revu et affiné. Une extraction brute du code contient souvent trop de détails. L’objectif est une abstraction qui conserve le sens.
Regroupement des interactions
Si un seul objet effectue de nombreuses petites tâches, regroupez-les en un seul message composite. Par exemple, au lieu de dessiner cinq appels distincts pour charger la configuration, les données du fichier et valider les paramètres, regroupez-les sous un seul InitializeContext()message. Cela réduit le bruit visuel.
Suppression de la redondance
Ne dessinez pas chaque getter et setter individuellement. Ce sont des détails d’implémentation. Concentrez-vous sur la logique métier. Si une méthode renvoie simplement une valeur sans traitement, elle n’a souvent pas besoin d’apparaître comme un message distinct, sauf si elle est critique pour le flux.
Standardisation de la notation
Assurez-vous de la cohérence dans la façon dont les éléments sont dessinés. Utilisez des lignes pleines pour les appels synchrones et des lignes pointillées pour les appels asynchrones dans tout le document. Utilisez des étiquettes UML standard pour les fragments (Alt, Opt, Boucle). La cohérence aide les lecteurs à interpréter rapidement le diagramme.
Tableau de référence des éléments courants 📋
Pour aider au processus de construction, voici une référence des éléments standards et de leurs équivalents en code.
| Élément UML | Représentation visuelle | Équivalent en code | Objectif |
|---|---|---|---|
| Acteur | Figure en bois | API externe, Utilisateur, Planificateur | Déclenche le processus |
| Ligne de vie | Ligne verticale pointillée | Instance de classe | Représente l’existence dans le temps |
| Message | Flèche horizontale | Appel de méthode | Communication entre objets |
| Barre d’activation | Boîte rectangulaire | Bloc d’exécution de méthode | Indique un traitement actif |
| Message de retour | Flèche pointillée (ouverte) | Instruction de retour | Réponse à l’appelant |
| Fragment (Alt) | Boîte avec [Condition] | Bloc Si / Sinon | Chemins de logique conditionnelle |
| Fragment (Boucle) | Boîte avec étiquette « Boucle » | Boucle Pour / Tant que | Exécution répétée |
Pièges à éviter ⚠️
Même avec un processus clair, des erreurs peuvent s’infiltrer dans la documentation. Être conscient des erreurs courantes aide à maintenir la qualité.
- Surcharger un seul diagramme : Essayer de montrer tout le cycle de vie du système sur une seule image le rend illisible. Divisez les systèmes complexes en plusieurs diagrammes par fonctionnalité.
- Ignorer le timing : Bien que les diagrammes de séquence ne soient pas des diagrammes de timing, l’ordre compte. Assurez-vous que l’ordre vertical des messages correspond à la séquence logique d’exécution.
- Sauter les messages de retour : Dans certains styles, les messages de retour sont facultatifs. Toutefois, pour le restructurage, montrer le flux de données de retour aide à comprendre comment les données remontent dans la pile.
- Ambiguïté de nommage : Utiliser des noms génériques comme « Processus » ou « Données » rend le diagramme inutile. Utilisez des termes spécifiques au domaine.
- Confusion entre statique et dynamique : N’confondez pas les relations de classe avec les flux de messages. Un diagramme de séquence concerne le comportement, et non la structure.
Intégrer les diagrammes dans le flux de travail 🔄
Créer un diagramme est un effort ponctuel si le code reste statique. Cependant, le code évolue. Pour garder la documentation utile, elle doit faire partie du flux de développement.
Lors de l’ajout d’une nouvelle fonctionnalité, la première étape doit être la mise à jour du diagramme de séquence. Cela garantit que la nouvelle logique est comprise avant d’être écrite. Lors d’un refactoring, le diagramme sert d’état cible. Le code est modifié jusqu’à ce qu’il corresponde au diagramme.
Cette pratique crée une boucle de rétroaction. Le code informe le diagramme, et le diagramme informe le code. Cela réduit le risque d’introduire un décalage architectural.
Conclusion sur l’architecture propre 🏗️
Transformer un code désordonné en diagrammes clairs est un exercice de discipline. Il demande la volonté de s’arrêter et d’observer avant d’agir. L’effort investi dans la documentation rapporte des dividendes en temps de débogage réduit et en communication plus claire. En suivant les étapes décrites ci-dessus, les équipes peuvent reprendre le contrôle de leurs systèmes. Le résultat n’est pas seulement une image, mais une compréhension plus profonde du logiciel qu’elles entretiennent. Cette compréhension est la fondation du développement durable.
Concentrez-vous sur le flux. Respectez les données. Documentez les interactions. En faisant cela, le chaos devient ordre, et la complexité devient clarté. Le chemin à suivre est défini par les lignes que vous tracez maintenant.