











Concevoir un modèle de données robuste exige plus que la simple définition des relations entre les tables. Il s’agit d’anticiper l’évolution des données au fil du temps et de garantir que chaque modification soit traçable. Un journal de traçabilité intégré dans un diagramme d’entités et de relations (ERD) constitue le fondement de la responsabilité et de la traçabilité des données. En modélisant explicitement les mécanismes de suivi directement dans le schéma, les organisations peuvent préserver l’intégrité sans dépendre uniquement de systèmes de journalisation externes.
Pourquoi suivre les modifications des données ? 📊
Mettre en place des fonctionnalités de traçabilité n’est pas simplement un choix technique ; c’est souvent une exigence réglementaire. Les secteurs traitant des informations sensibles doivent démontrer qui a accédé à quelles données et quand. Au-delà de la conformité, les journaux de traçabilité fournissent des informations critiques pour le débogage en cas de panne du système. Lorsqu’une incohérence apparaît dans les données, les enregistrements historiques permettent aux ingénieurs de reconstruire l’état de la base de données à tout moment donné.
- Conformité :Les réglementations exigent souvent le maintien des journaux de modifications pendant des périodes spécifiques.
- Sécurité :Identifier les modifications non autorisées ou les violations de données.
- Débogage :Rechercher la source de la corruption des données ou des erreurs logiques.
- Responsabilité :Savoir exactement quel utilisateur ou processus a initié la mise à jour d’un enregistrement.
Composants fondamentaux d’un schéma de traçabilité 🏗️
Lors de l’intégration de journaux de traçabilité dans votre ERD, des colonnes spécifiques doivent être présentes pour capturer les métadonnées nécessaires. Ces champs doivent être standardisés sur toutes les entités afin d’assurer une cohérence dans les rapports et les requêtes.
Champs de métadonnées essentiels
Chaque entité sujette à traçabilité doit inclure un ensemble d’attributs fondamentaux. Ces champs enregistrent le cycle de vie de l’enregistrement.
- Identifiant de l’enregistrement :Une clé unique pour distinguer la version spécifique de l’enregistrement.
- Horodatage de création :La date et l’heure exactes de l’insertion de l’enregistrement.
- Horodatage de mise à jour :La dernière fois que l’enregistrement a été modifié.
- Créé par :L’identifiant de l’utilisateur ou du processus système responsable de l’insertion.
- Mis à jour par :L’identifiant de l’utilisateur ou du processus système responsable du dernier changement.
- Type d’opération :Indique si l’action était une insertion, une mise à jour ou une suppression.
Stratégies de mise en œuvre 🛠️
Il existe plusieurs approches architecturales pour modéliser ces modifications. Chaque stratégie présente des compromis différents en matière de stockage, de performance des requêtes et de complexité. Le choix dépend des besoins spécifiques de l’application et du volume de données.
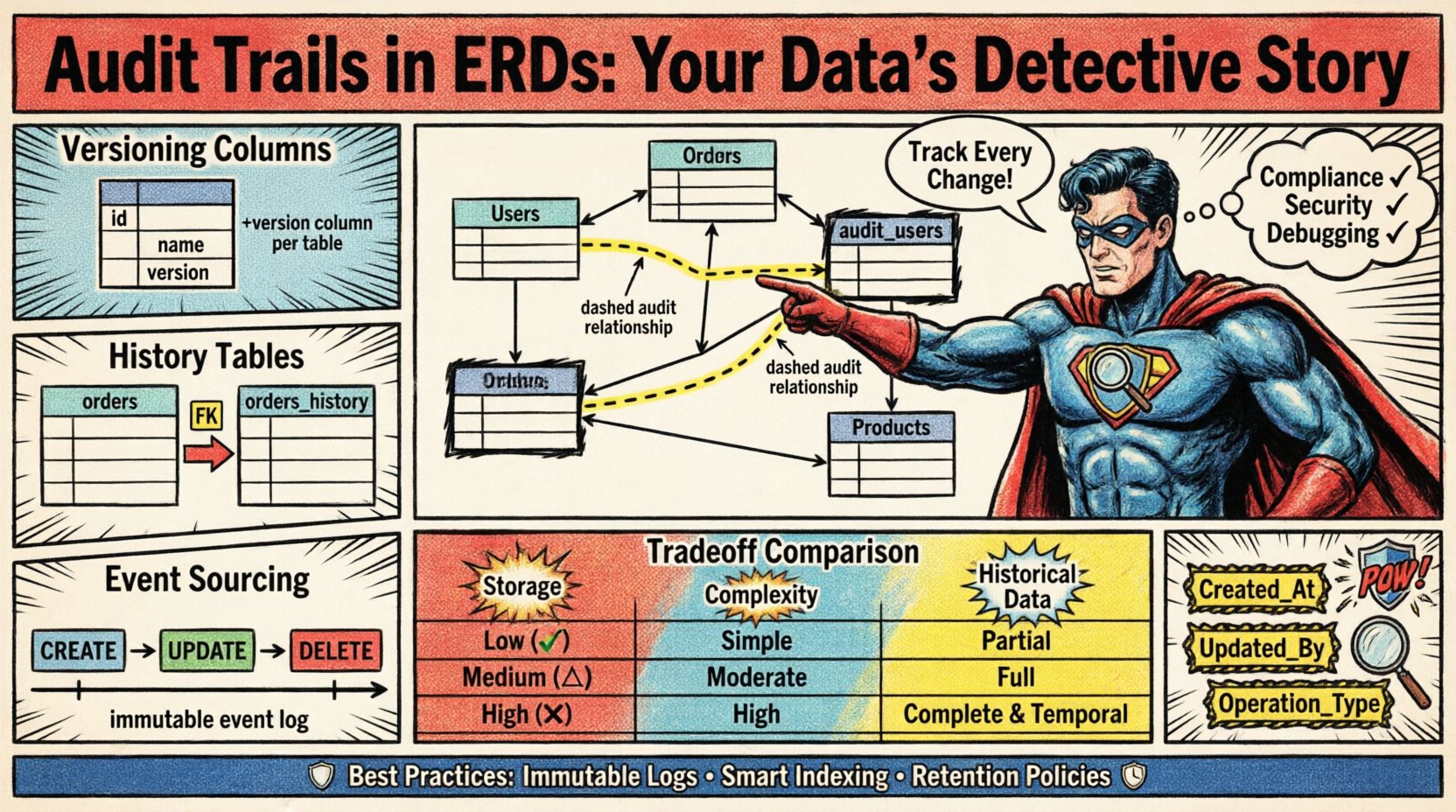
1. Colonnes de versionning (mises à jour douces)
Cette approche consiste à ajouter directement des colonnes de suivi dans la table principale de l’entité. C’est la méthode la plus simple à mettre en œuvre.
- Avantages :Modifications minimales du schéma ; interrogation facile de l’état actuel avec historique.
- Inconvénients :Ne préserve pas les instantanés historiques ; affiche uniquement les métadonnées du dernier changement.
2. Tables d’historique parallèles
Au lieu de modifier la table principale, les changements sont enregistrés dans une table séparée liée par une clé étrangère. Cela permet d’avoir un historique complet de chaque modification.
- Avantages :Séparation claire des données actuelles et de l’historique ; capacité complète à capturer des instantanés.
- Inconvénients :Besoin accru de stockage ; requêtes plus complexes nécessitant des jointures.
3. Sourcing d’événements
L’état complet de l’entité est reconstruit à partir d’un journal d’événements. La base de données ne stocke que les changements, pas l’état actuel.
- Avantages :Traçabilité complète ; source de données immuable.
- Inconvénients :Haute complexité dans la logique de reconstruction ; surcharge de performance lors du calcul de l’état.
Conception des relations 🔗
Le diagramme entité-relation doit représenter visuellement la manière dont les données de suivi sont liées aux entités métiers. Une distinction visuelle claire aide les développeurs à comprendre le schéma sans lire la documentation.
- Un-à-plusieurs :Un enregistrement d’entité peut avoir plusieurs entrées de journal de suivi.
- Clés étrangères :La table de suivi doit référencer la clé primaire de l’entité source.
- Indexation :Les clés étrangères dans la table de suivi doivent être indexées pour accélérer les recherches.
Lors du dessin du diagramme, utilisez des lignes pointillées pour indiquer les relations de suivi. Cela les distingue des relations logiques métier standard, telles que les commandes clients ou les stocks de produits.
Analyse comparative des méthodes 📋
Le choix du bon modèle nécessite de comprendre le contexte opérationnel. Le tableau ci-dessous décrit les caractéristiques des approches courantes.
| Fonctionnalité | Colonnes de versionning | Tables d’historique | Sourcing d’événements |
|---|---|---|---|
| Surcharge de stockage | Faible | Moyen | Élevé |
| Complexité des requêtes | Simple | Modéré | Complexe |
| Données historiques | Métadonnées uniquement | Captures intégrales | Flux d’événements complet |
| Effort d’implémentation | Faible | Moyen | Élevé |
Considérations sur les performances ⚡
Les journaux d’audit ajoutent une surcharge d’écriture à chaque transaction. À mesure que le volume de données augmente, l’impact sur les performances du système devient significatif. Un indexage et une partitionnement appropriés sont nécessaires pour atténuer la latence.
- Stratégie d’indexation :Créez des index sur les colonnes mis à jour_par et mis à jour_le colonnes. Cela facilite le reporting rapide de l’activité des utilisateurs.
- Partitionnement : Pour les systèmes à fort volume, partitionnez les tables d’audit par date. Cela maintient les données actives dans un stockage chaud tout en déplaçant les anciens enregistrements vers un stockage froid.
- Traitement par lots : Au lieu d’enregistrer chaque micro-changement, envisagez de regrouper les mises à jour si un suivi en temps réel n’est pas strictement nécessaire.
Intégrité des données et sécurité 🔒
La sécurité est primordiale lors de la conception des mécanismes d’audit. La traçabilité d’audit elle-même doit être protégée contre toute manipulation. Si un attaquant peut modifier les journaux, le système perd sa crédibilité.
- Journaux immuables : Assurez-vous que les enregistrements d’audit ne peuvent pas être supprimés ou modifiés par des utilisateurs standards.
- Contrôle d’accès : Limitez les accès en écriture aux tables d’audit aux processus système ou aux comptes privilégiés uniquement.
- Validation : Assurez-vous que les identifiants d’utilisateur mentionnés dans les journaux d’audit existent réellement dans le répertoire des utilisateurs.
Maintenance et cycle de vie 🔄
Les politiques de rétention des données déterminent pendant combien de temps les informations d’audit doivent être conservées. Le stockage indéfini de ces données est inefficace et coûteux. Un plan de gestion du cycle de vie défini est essentiel.
- Archivage : Déplacez les enregistrements datant d’une période supérieure à un seuil spécifique vers une base de données d’archivage distincte.
- Purge : Supprimez automatiquement les enregistrements qui ont dépassé les exigences légales de rétention.
- Surveillance : Configurez des alertes sur les taux de croissance des tables d’audit pour éviter l’épuisement du stockage.
Meilleures pratiques pour la nomenclature des schémas 📝
Des conventions de nommage cohérentes réduisent la confusion pendant le développement et la maintenance. Respecter un modèle de nommage standard garantit que les colonnes d’audit sont facilement identifiables dans l’ensemble du système.
- Préfixes : Utilisez des préfixes tels que
audit_ou_logpour les noms de tables. - Horodatages : Utilisez
_atdes suffixes pour les colonnes de temps (par exemple,created_at). - Identifiants : Utilisez
_parsuffixes pour les références utilisateur (par exemple,mis_a_jour_par). - Clés étrangères : Nommez les clés explicitement (par exemple,
source_entity_id) pour clarifier la relation.
En intégrant ces pratiques dans le diagramme d’entité et de relation, les développeurs créent un système transparent et résilient. Le diagramme devient un document vivant qui guide non seulement le stockage des données, mais aussi la gouvernance de ces données tout au long de leur existence.
Conclusion 📌
Intégrer une traçabilité dans le modèle de données est une étape fondamentale pour l’architecture des données modernes. Elle transforme un diagramme statique en un outil dynamique de gouvernance. Que vous utilisiez des colonnes de versioning ou des tables historiques dédiées, l’objectif reste le même : garantir que chaque action au sein du système est enregistrée et récupérable. Une planification soigneuse des relations, de l’indexation et des politiques de rétention assure que la fonctionnalité de traçabilité soutient l’activité sans nuire aux performances.