











Les bases de données relationnelles sont fondées sur des tables et des lignes, une structure conçue pour les données plates. Toutefois, le monde réel adhère rarement à une telle simplicité. Les organisations, les systèmes de fichiers, les fils de commentaires et les arbres de catégories existent tous en structures hiérarchiques. Représenter ces relations parent-enfant dans un diagramme standard d’entités et de relations (ERD) nécessite des modèles de conception spécifiques qui préservent l’intégrité des données tout en permettant une récupération efficace.
Lorsque vous tentez de mapper une structure arborescente sur un schéma plat, vous rencontrez la tension classique entre la normalisation et les performances. Ce guide explore les techniques fondamentales pour modéliser les données hiérarchiques, en évaluant les compromis de chaque approche afin de vous aider à concevoir des systèmes robustes.
🧩 Le défi des schémas plats
Un diagramme d’entités et de relations visualise généralement les entités sous forme de boîtes et les relations sous forme de lignes. Dans une relation standard, une table est liée à une autre via une clé étrangère. Cela fonctionne parfaitement pour une relation plusieurs-à-plusieurs ou une-à-plusieurs où la direction est fixe. Mais que se passe-t-il lorsque une catégorie peut avoir des sous-catégories, qui elles-mêmes peuvent avoir des sous-sous-catégories, potentiellement à l’infini ?
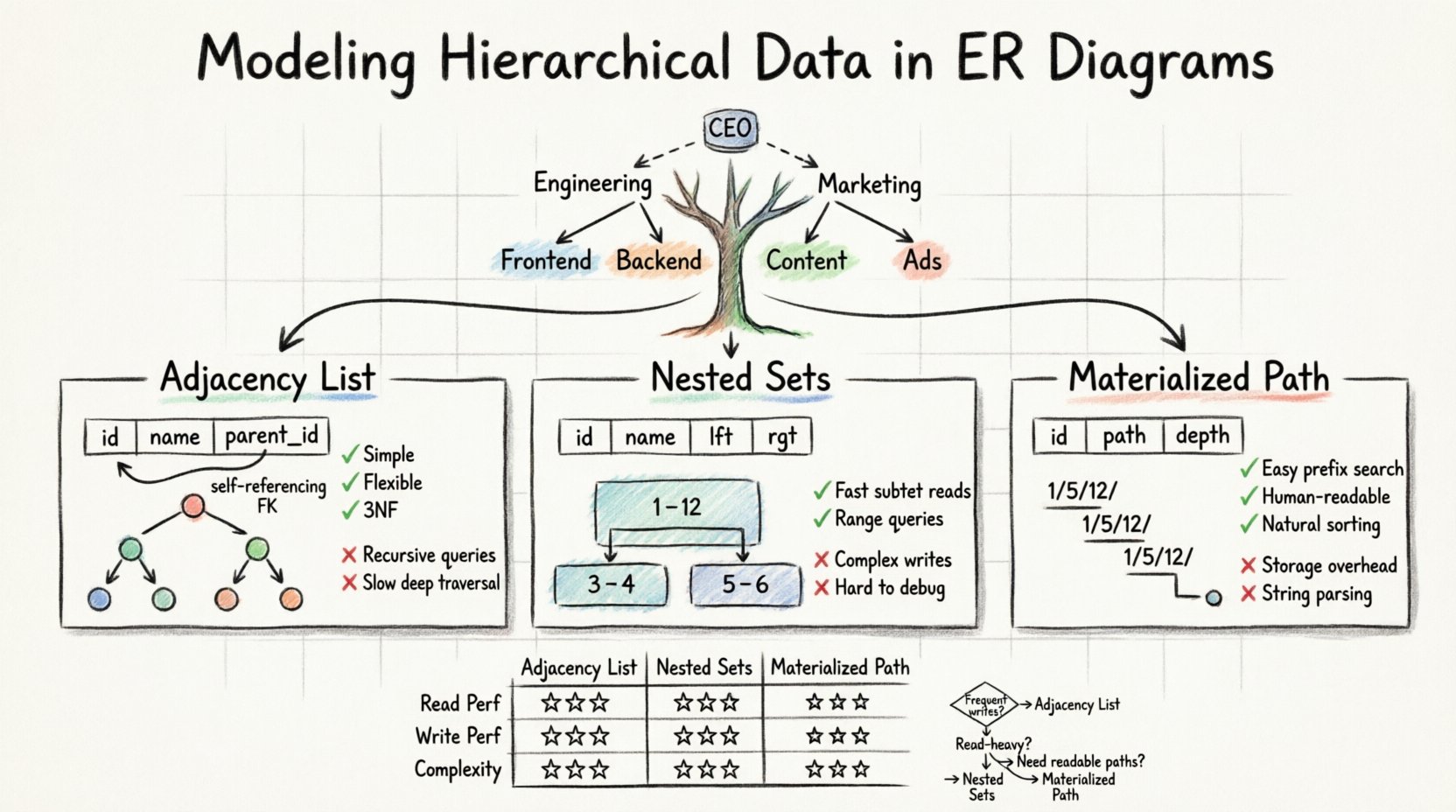
Les modèles relationnels standards peinent avec une profondeur variable. Une table plate ne peut pas facilement stocker un chemin de longueur arbitraire. Pour résoudre ce problème, nous devons adapter le schéma afin de stocker la hiérarchie de manière explicite. Il existe trois modèles principaux utilisés par les architectes de données pour y parvenir :
- Liste d’adjacence : Stocker l’identifiant du parent dans l’enregistrement enfant.
- Ensembles imbriqués : Attribuer des valeurs gauche et droite pour définir des plages.
- Énumération des chemins : Stocker le chemin complet depuis la racine jusqu’au nœud actuel.
🔗 Le modèle de liste d’adjacence
La liste d’adjacence est la méthode la plus courante et la plus simple pour représenter une hiérarchie dans un ERD standard. Elle repose sur une relation auto-référente. Cela signifie qu’une seule table contient une colonne qui fait référence à sa propre clé primaire.
📐 Structure du schéma
Dans ce modèle, vous créez une seule table pour stocker les données. Chaque ligne représente un nœud de l’arbre. L’élément essentiel est une colonne, souvent nommée parent_id ou ancestor_id, qui contient l’identifiant unique du nœud parent. Si un nœud se trouve au sommet de la hiérarchie, cette colonne contient une valeur nulle.
Considérez une table pour Département:
- id : La clé primaire unique du département.
- nom : Le nom affiché du département.
- parent_id : L’identifiant du département supérieur (peut être nul pour le niveau supérieur).
✅ Avantages
- Simplicité : Le schéma est intuitif et facile à comprendre pour les développeurs et les administrateurs de bases de données.
- Flexibilité : Déplacer un sous-arbre est simple ; il suffit de mettre à jour le
parent_iddu nœud racine de ce sous-arbre. - Normalisation : Il respecte bien la Troisième Forme Normale (3NF) car les données ne sont pas redondantes.
❌ Inconvénients
- Complexité des requêtes : Récupérer tous les descendants nécessite des requêtes récursives ou un traitement côté application.
- Performance : Les parcours profonds peuvent être lents sans stratégies d’indexation spécifiques ou des expressions de table communes récursives (CTEs).
- Intégrité référentielle : Bien que les clés étrangères aident, des références circulaires peuvent encore survenir si les contraintes ne sont pas strictement appliquées.
🌲 Le modèle des ensembles imbriqués
Le modèle des ensembles imbriqués transforme la structure arborescente en un ensemble d’intervalles. Au lieu de suivre les pointeurs vers le parent, chaque nœud reçoit deux nombres : gauche et droite. Ces valeurs représentent la position du nœud dans un parcours préfixe de l’arbre.
📐 Structure du schéma
Imaginez un arbre où le nœud racine est l’ensemble entier. En parcourant l’arbre, vous augmentez un compteur. Lorsque vous entrez dans un nœud, vous enregistrez le compteur actuel comme gauche. Lorsque vous avez terminé de traiter ce nœud et tous ses enfants, vous enregistrez le compteur comme droite. Le droite la valeur est toujours supérieure à la gauche valeur.
Un Catégorietable aurait l’aspect suivant :
- id : Identifiant unique.
- nom : Nom de la catégorie.
- gauche : La valeur de la limite gauche.
- droite : La valeur de la limite droite.
✅ Avantages
- Récupération rapide : Récupérer un sous-arbre est une requête simple sur une plage en utilisant
BETWEENlogique. - Efficacité : La performance de lecture est supérieure pour les grands arbres profonds par rapport aux listes d’adjacence.
❌ Inconvénients
- Coût d’écriture : Insérer ou déplacer un nœud est coûteux. Vous devez mettre à jour les valeurs de
gaucheetdroitedes nombreux autres nœuds pour maintenir l’intégrité des intervalles. - Complexité : La logique est difficile à implémenter et à déboguer sans un support de bibliothèque dédiée.
🛣️ Énumération des chemins et chemins matérialisés
Les méthodes d’énumération des chemins stockent la lignée d’un nœud sous forme de chaîne de caractères ou d’une liste délimitée. Cette approche est souvent appelée le modèle de chemin matérialisé. Elle combine la simplicité de la liste d’adjacence avec la lisibilité du chemin.
📐 Structure du schéma
Dans ce modèle, chaque enregistrement stocke le chemin complet depuis la racine. Par exemple, dans un modèle de système de fichiers, un fichier pourrait avoir une chaîne de chemin comme/home/utilisateur/documents/rapport.txt. Dans une base de données, cela est souvent stocké sous forme de chaîne délimitée dans la colonne, par exemple1/5/12/.
La table comprend :
- id : Clé primaire.
- chemin : Une chaîne représentant la lignée.
- profondeur : Un entier indiquant à quel niveau de profondeur se trouve le nœud.
✅ Avantages
- Parcours facile : Vous pouvez trouver tous les descendants en correspondant au préfixe du chemin.
- Lisibilité : Les données sont lisibles par un être humain et faciles à déboguer.
- Tri : Le tri par la chaîne de chemin donne souvent naturellement l’ordre arborescent correct.
❌ Inconvénients
- Surcharge de stockage : Les chemins longs peuvent consommer une quantité importante d’espace de stockage.
- Analyse de chaîne : Les requêtes nécessitent souvent des fonctions de manipulation de chaîne, ce qui peut être plus lent que les comparaisons d’entiers.
📊 Analyse comparative
Le choix du bon modèle dépend fortement de votre ratio lecture/écriture et de la profondeur de votre hiérarchie. Le tableau suivant décrit les caractéristiques de chaque méthode.
| Fonctionnalité | Liste d’adjacence | Ensembles imbriqués | Chemin matérialisé |
|---|---|---|---|
| Performance de lecture | Faible à moyenne | Élevée | Moyenne à élevée |
| Performance d’écriture | Élevée | Faible | Moyenne |
| Complexité d’implémentation | Faible | Élevée | Moyenne |
| Prend en charge les arbres profonds | Oui | Oui | Oui (avec des limites) |
| Logique des requêtes | Récursive | Balayage de plage | Correspondance de préfixe |
⚙️ Considérations sur les performances
Lors de la modélisation d’une hiérarchie, vous devez tenir compte de la manière dont le moteur de base de données gère les données. Les stratégies d’indexation jouent un rôle crucial, quelle que soit la méthode choisie.
- Liste d’adjacence : Indexez la colonne
parent_idcolonne de manière importante. Cela permet à la base de données de localiser rapidement tous les enfants d’un nœud spécifique sans scanner l’ensemble de la table. - Ensembles imbriqués : Indexez les deux
gaucheetdroit. Les index composés peuvent optimiser considérablement les requêtes sur des plages. - Chemin matérialisé : Indexez la colonne
chemincolonne. Selon la base de données, un index de préfixe pourrait être avantageux pour filtrer les sous-arbres.
🛠️ Maintenance et mises à jour
Les modèles de données ne sont pas statiques. Au fur et à mesure que votre organisation grandit, votre hiérarchie évoluera. Déplacer un nœud d’une branche à une autre est une opération courante qui affecte chaque modèle différemment.
🔄 Déplacement des nœuds
Dans un modèle Liste d’adjacence, déplacer un nœud consiste en une seule instruction de mise à jour. Vous modifiez le champ parent_id de la racine du sous-arbre. Toutefois, vous devez vous assurer qu’aucune référence circulaire n’est créée.
Dans un modèle Ensemble imbriquémodèle, déplacer un nœud est complexe. Cela implique de recalculer les valeurs gauche et droit de tous les nœuds du sous-arbre de destination afin de faire de la place au nœud déplacé. Cela constitue souvent une opération transactionnelle impliquant plusieurs mises à jour de table.
Dans un modèle Chemin matérialisémodèle, vous mettez à jour la chaîne de chemin du nœud déplacé et de tous ses descendants. Cela exige de mettre à jour le chemin de chaque enfant, ce qui peut être une opération d’écriture lourde pour de grands arbres.
🎯 Meilleures pratiques pour la modélisation des données
Pour garantir que votre MCD reste maintenable et performant, suivez ces recommandations lors de la mise en œuvre de structures hiérarchiques.
- Utilisez des conventions de nommage claires : Évitez les noms génériques comme
col1. Utilisezparent_id,ancestor_id,lft, ourgtexplicitement. - Appliquer des contraintes : Utilisez des contraintes de base de données pour empêcher les références circulaires. Un nœud ne peut pas être son propre ancêtre.
- Limitez la profondeur : Bien que techniquement possible, des hiérarchies extrêmement profondes (par exemple, plus de 10 niveaux) indiquent souvent un défaut de conception. Pensez à aplatir la structure si possible.
- Documentez le choix : Étant donné que ces modèles ne sont pas des fonctionnalités standard SQL, documentez quel modèle est utilisé dans la documentation du schéma.
- Considérez des approches hybrides : Certains systèmes combinent les listes d’adjacence avec les chemins matérialisés pour équilibrer les performances de lecture et d’écriture.
🧠 Choisir la bonne stratégie
Il n’existe pas de réponse unique « correcte » pour chaque scénario. Le choix repose sur les exigences spécifiques de votre application.
- Choisissez la liste d’adjacence si : Vos données changent fréquemment, et la profondeur de la hiérarchie est modérée. C’est le choix par défaut le plus sûr pour la plupart des applications générales.
- Choisissez les ensembles imbriqués si : Vous avez une application très lue où les données sont rarement déplacées, et vous devez récupérer rapidement de grandes sous-arbres.
- Choisissez le chemin matérialisé si : Vous avez besoin de chemins lisibles par les humains (comme les URLs) et la profondeur de la hiérarchie est relativement faible.
Comprendre ces nuances structurelles vous permet de concevoir des bases de données évolutives. En choisissant le bon modèle pour votre diagramme d’entités, vous assurez que vos données restent cohérentes, accessibles et efficaces tout au long du cycle de vie du système.