











Diseñar una estructura de base de datos robusta requiere precisión y visión de futuro. El diagrama Entidad-Relación (ERD) sirve como plano fundamental para esta arquitectura. Sin un mapa claro, la redundancia de datos y los cuellos de botella de consultas aparecen rápidamente, lo que conduce a una degradación del rendimiento con el tiempo. Esta guía explora cómo derivar técnicas de optimización directamente de estos modelos visuales. Nos enfocamos en la integridad estructural y la optimización del rendimiento sin depender de características específicas de plataformas ni herramientas propietarias. Al comprender las relaciones subyacentes, puedes construir sistemas que escalen de manera eficiente.
📐 Comprendiendo los fundamentos del ERD
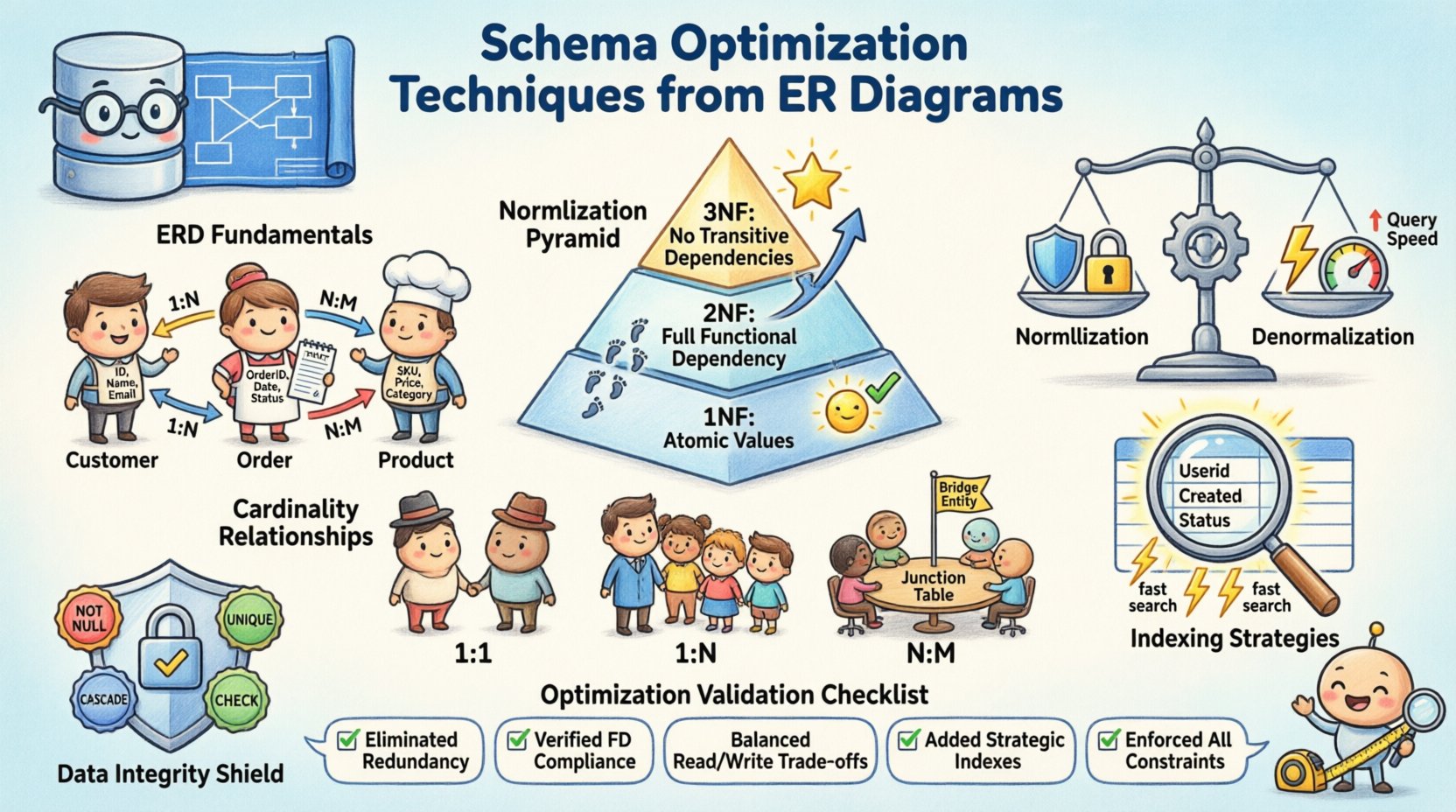
Antes de comenzar la optimización, los componentes principales deben estar claros. Un diagrama ER traduce los requisitos del negocio en un modelo de datos lógico. Define cómo se almacena y accede a la información. Una base sólida previene la deuda estructural más adelante en el ciclo de vida del desarrollo. Considere los siguientes elementos:
- Entidades: Representan objetos o conceptos, como clientes, pedidos o productos. Cada entidad se convierte en una tabla en el esquema físico.
- Atributos: Definen las propiedades de las entidades, como nombre, ID o marca de tiempo. Estos se convierten en columnas dentro de las tablas.
- Relaciones: Muestran cómo interactúan las entidades. Estas determinan el uso de claves foráneas y restricciones.
Visualizar estos componentes te permite identificar posibles problemas antes de escribir una sola línea de código. Asegura que el flujo lógico coincida con los requisitos de almacenamiento físico. Esta alineación es crítica para mantener la consistencia de los datos en aplicaciones complejas.
🔨 Estrategias de normalización para la integridad de los datos
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad. Implica dividir tablas grandes en unidades lógicas más pequeñas. Aunque una normalización excesiva puede ralentizar las lecturas, omitirla por completo genera anomalías de actualización. El objetivo es encontrar el equilibrio que mejor se adapte a tu carga de trabajo específica.
Primera Forma Normal (1FN)
La primera regla requiere que cada columna contenga valores atómicos. No se permiten grupos repetidos ni arreglos dentro de una sola celda. Esto garantiza que cada pieza de datos sea distinta y consultable. Por ejemplo, una lista de números de teléfono debe dividirse en filas separadas o en una tabla relacionada, y no almacenarse como una cadena separada por comas.
Segunda Forma Normal (2FN)
Una vez cumplida la 1FN, la 2FN aborda las dependencias parciales. Todos los atributos no clave deben depender de toda la clave primaria. En claves compuestas, esto evita la duplicación de datos donde solo parte de la clave determina un atributo. Este paso refina la estructura para asegurar que cada pieza de información esté correctamente vinculada a su padre.
Tercera Forma Normal (3FN)
La tercera forma elimina las dependencias transitivas. Los atributos no clave no deben depender de otros atributos no clave. Esto significa que si el atributo A depende del atributo B, y B depende de la clave, entonces A no debería existir en la misma tabla. Mover estos datos a una tabla separada mejora la mantenibilidad y reduce el desperdicio de almacenamiento.
La tabla a continuación resume la progresión de la normalización:
| Forma Normal | Objetivo principal | Restricción clave |
|---|---|---|
| 1FN | Valores atómicos | Sin grupos repetidos |
| 2FN | Dependencia completa | Eliminar dependencias parciales |
| 3FN | Independencia | Eliminar dependencias transitivas |
⚡ Denormalización para rendimiento
Mientras que la normalización garantiza la integridad, a menudo requiere uniones complejas durante las consultas. En sistemas con alta carga de lectura, la sobrecarga de unir múltiples tablas puede convertirse en un cuello de botella. La denormalización introduce intencionalmente redundancia para mejorar la velocidad de recuperación. Esta es una compensación entre la eficiencia del almacenamiento y el rendimiento de las consultas.
Considere los siguientes escenarios en los que la denormalización es adecuada:
- Paneles de informes:Los datos agregados pueden calcularse de antemano y almacenarse para evitar el cálculo en tiempo real.
- Capas de caché:Los datos frecuentemente accedidos pueden duplicarse en un almacén optimizado para lectura.
- Transacciones de alto rendimiento:Reducir la profundidad de las uniones minimiza la contención de bloqueos y el uso de CPU.
Al implementar esto, establezca un proceso claro para actualizar los datos redundantes. Las inconsistencias surgen si el origen de la verdad cambia sin actualizar las copias. Los desencadenantes automáticos o la lógica de la aplicación deben manejar la sincronización para mantener la precisión.
🔗 Gestión de cardinalidad y relaciones
La cardinalidad define la relación numérica entre entidades. Determina cómo se implementan las claves foráneas y cómo se enlazan los datos. Comprender estos patrones es esencial para prevenir registros huérfanos y garantizar la integridad referencial.
- Uno a uno:Rara en sistemas generales, a menudo utilizada para tablas de seguridad o de extensión. Una sola fila en la tabla A se vincula exactamente con una fila en la tabla B.
- Uno a muchos:La relación más común. Un registro padre se relaciona con múltiples registros hijos. La clave foránea reside en la tabla hija.
- Muchos a muchos:Requiere una tabla de unión para resolver la relación. Esta tabla intermedia enlaza las claves primarias de ambas entidades.
Las suposiciones incorrectas sobre la cardinalidad conducen a un almacenamiento ineficiente o a estados de datos inválidos. Por ejemplo, tratar una relación muchos a muchos como una columna simple impedirá múltiples asociaciones. Modelar correctamente estos enlaces asegura que la base de datos pueda aplicar las reglas de negocio definidas en el diagrama.
📉 Estrategias de indexación basadas en análisis estructural
Los índices son el mecanismo que permite al motor de la base de datos encontrar datos rápidamente. La estructura del ERD informa directamente qué columnas deben indexarse. Añadir índices ciegamente consume espacio en disco y ralentiza las operaciones de escritura.
Las consideraciones clave para la indexación incluyen:
- Claves primarias:Siempre se indexan por defecto. Definen la identidad única de cada fila.
- Claves foráneas:A menudo requieren indexación para acelerar las operaciones de unión y las comprobaciones de restricciones.
- Claves compuestas:Se utilizan cuando las consultas filtran por múltiples columnas. El orden de las columnas en el índice importa para el rendimiento.
- Columnas selectivas:Indexe columnas con alta cardinalidad. La baja selectividad (por ejemplo, género) rara vez se beneficia de un índice.
Analice sus patrones de consulta en relación con el diseño de esquema. Si una unión específica se ejecuta con frecuencia, asegúrese de que la columna de clave foránea esté indexada. Esto reduce el tiempo que la base de datos pasa escaneando tablas enteras.
🛡️ Integridad de datos y restricciones referenciales
Las restricciones de integridad protegen la precisión y consistencia de los datos. Actúan como una barrera de seguridad contra entradas inválidas o eliminaciones accidentales. Aunque algunas restricciones son impuestas por la aplicación, las restricciones a nivel de base de datos son más confiables.
Los tipos comunes de restricciones incluyen:
- NO NULO:Asegura que una columna siempre contenga un valor. Evita huecos en campos críticos de datos.
- ÚNICO:Asegura que ninguna fila comparta el mismo valor en una columna específica. Útil para correos electrónicos o nombres de usuario.
- CASCADE:Define qué sucede con los registros secundarios cuando se elimina un registro principal. Las opciones incluyen restringir, propagar o establecer nulo.
- CHECK:Impone condiciones específicas sobre los valores de datos, como rangos de fechas o límites numéricos.
Implementar estas reglas a nivel de base de datos evita que la aplicación tenga que validar cada punto de datos. Centraliza la lógica de validez de datos, reduciendo la duplicación de código y posibles errores.
🔄 Mejora iterativa y evolución del esquema
El diseño de esquema no es una tarea única. Los requisitos del negocio cambian, y el modelo de datos debe evolucionar. Las revisiones regulares del diagrama ERD y del esquema físico ayudan a identificar áreas de mejora. Monitorear el rendimiento de las consultas proporciona información sobre dónde la estructura tiene dificultades.
Durante la mejora, considere los siguientes pasos:
- Revisar el uso de índices:Elimine los índices no utilizados para reducir la sobrecarga de escritura.
- Verificar la partición:Las tablas grandes pueden beneficiarse de dividir los datos según rangos o claves.
- Actualizar cardinalidad:A medida que cambia la lógica de negocio, las relaciones pueden pasar de uno a muchos a muchos a muchos.
- Control de versiones:Trate los cambios de esquema como código. Registre las modificaciones para permitir un retorno a una versión anterior si es necesario.
Este enfoque iterativo asegura que la base de datos permanezca alineada con las necesidades de la aplicación con el tiempo. Evita la acumulación de deuda técnica que ralentiza el desarrollo futuro.
✅ Lista de verificación de optimización
Utilice esta lista para validar el diseño de su esquema antes de la implementación:
- Verifique que todas las tablas cumplan al menos con la Tercera Forma Normal (3FN).
- Asegúrese de que las claves foráneas estén indexadas donde las uniones son frecuentes.
- Verifique la existencia de dependencias circulares en las relaciones.
- Confirme que las claves primarias estén definidas para cada tabla.
- Revise las restricciones para asegurarse de que se apliquen las reglas de consistencia de datos.
- Analice los patrones de consulta para identificar posibles oportunidades de denormalización.
- Documente todas las suposiciones relacionadas con la cardinalidad y el volumen de datos.
Seguir estos pasos crea una base resistente para el almacenamiento de datos. Permite al sistema manejar el crecimiento sin requerir una reconstrucción completa. Un esquema bien optimizado es la diferencia entre una aplicación lenta y una reactiva.