









En la arquitectura de sistemas de datos robustos, el Diagrama de Relaciones Entidad-Entidad (ERD) sirve como el plano fundamental. A medida que los sistemas crecen en complejidad y aumenta el volumen de datos, mantener un esquema limpio se vuelve crítico. La redundancia en un ERD a gran escala no es meramente una cuestión de almacenamiento desperdiciado; es una fuente de inestabilidad sistémica. Cuando puntos de datos idénticos se almacenan en múltiples ubicaciones sin un mecanismo para sincronizarlos, el riesgo de inconsistencia de datos aumenta bruscamente.
Esta guía explora las estrategias técnicas necesarias para minimizar la redundancia mientras se preserva la flexibilidad requerida para aplicaciones de alto volumen. Examinaremos los principios de normalización, patrones estructurales y métodos de verificación para garantizar que su modelo de datos permanezca estable con el tiempo.
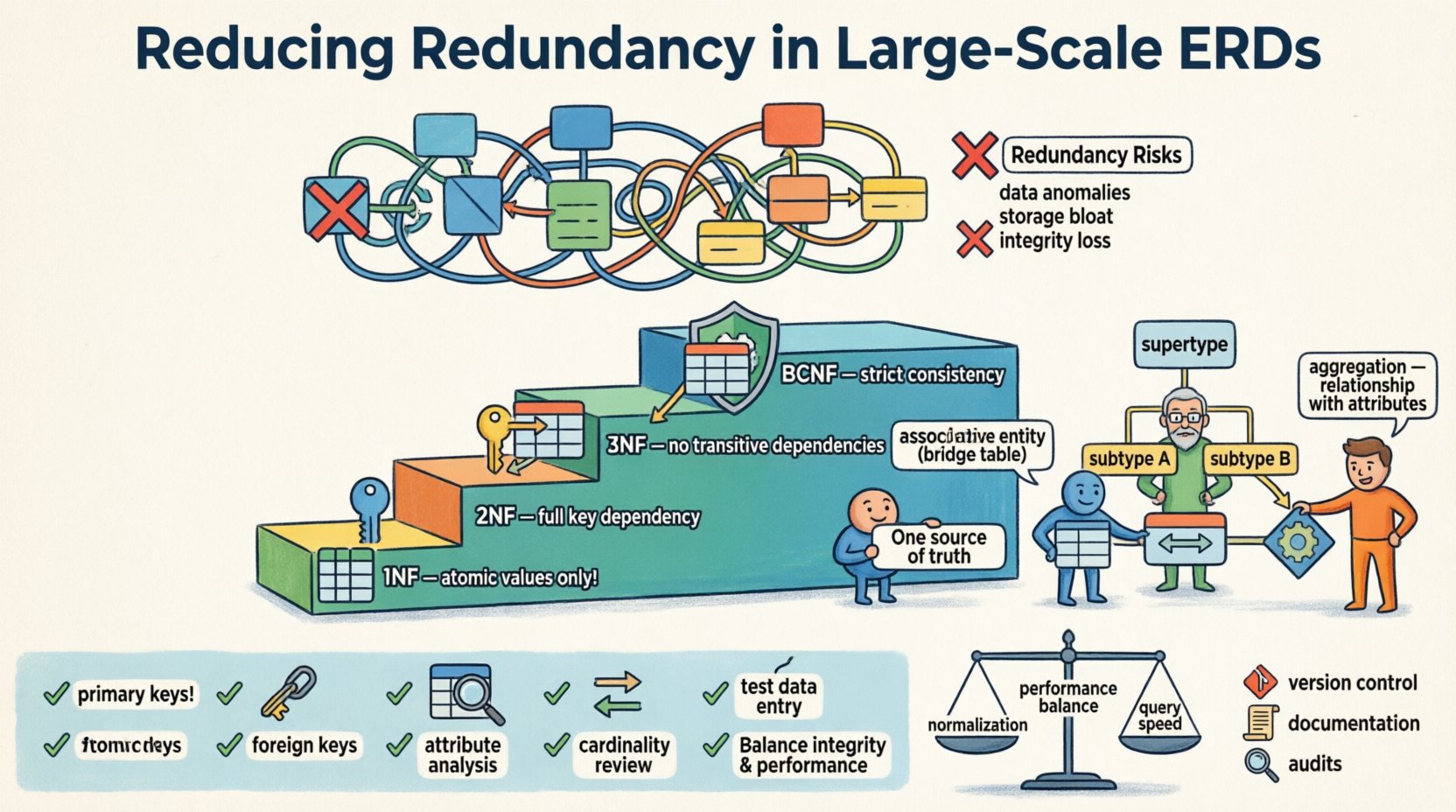
📉 El costo de la duplicación en modelos de datos
La redundancia ocurre cuando la misma pieza de datos se almacena más de una vez dentro del esquema de la base de datos. Aunque cierta desnormalización es aceptable para la optimización del rendimiento, la duplicación descontrolada introduce varios riesgos que se magnifican en entornos a gran escala.
-
Anomalías de datos:Actualizar la información en una ubicación pero no en otra genera registros conflictivos. Esto se conoce como una anomalía de actualización.
-
Problemas de inserción:A veces, no puedes agregar nuevos datos porque la información relacionada falta en otra parte. Esto se conoce como una anomalía de inserción.
-
Riesgos de eliminación:Eliminar un registro podría borrar accidentalmente información única que se almacenó de forma redundante dentro de esa fila. Esto se conoce como una anomalía de eliminación.
-
Hinchazón del almacenamiento:Almacenar los mismos valores repetidamente consume espacio en disco y memoria de forma innecesaria.
-
Pérdida de integridad:Sin restricciones que obliguen a la unicidad en campos redundantes, la única fuente de verdad se fragmenta.
En diagramas a gran escala, estos problemas se agravaron. Una sola tabla con claves foráneas o atributos descriptivos duplicados puede causar fallas en cadena durante operaciones de mantenimiento. El objetivo es lograr un equilibrio en el que se preserve la integridad de los datos sin sacrificar la eficiencia de las consultas.
🔄 Comprendiendo los principios de normalización
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la gestión de dependencias. Implica descomponer las tablas en entidades más pequeñas y bien estructuradas. Aunque la teoría data de los años 70, los principios siguen siendo la base del diseño de esquemas modernos.
Primera Forma Normal (1FN)
El primer paso consiste en garantizar la atomicidad. Cada columna debe contener valores indivisibles. Las listas dentro de una sola celda violan este principio. Por ejemplo, almacenar múltiples números de teléfono en un solo campo requiere dividirlos en filas separadas o tablas relacionadas.
Segunda Forma Normal (2FN)
Una vez cumplida la 1FN, abordamos las dependencias parciales. Una tabla está en 2FN si está en 1FN y todos los atributos no clave dependen completamente de la clave primaria. En claves compuestas, los atributos no deben depender solo de parte de la clave.
Tercera Forma Normal (3FN)
Esta es la norma más común para sistemas transaccionales generales. Una tabla está en 3FN si está en 2FN y no tiene dependencias transitivas. En términos más simples, los atributos no clave no deben depender de otros atributos no clave. Si A determina B y B determina C, entonces A determina C, lo cual es redundante a menos que Bes una clave.
Forma Normal de Boyce-Codd (BCNF)
BCNF es una versión más estricta de la 3FN. Maneja casos en los que hay múltiples claves candidatas y dependencias superpuestas. Aunque no siempre es necesario, garantiza el más alto nivel de consistencia lógica.
|
Forma |
Enfoque |
Requisito clave |
Impacto en la redundancia |
|---|---|---|---|
|
1FN |
Atomicidad |
Sin grupos repetidos |
Estructura básica |
|
2FN |
Dependencias parciales |
Dependencia completa en la clave primaria |
Reduce la redundancia de claves divididas |
|
3FN |
Dependencias transitivas |
Los no-claves dependen únicamente de la clave |
Elimina la duplicación de atributos |
|
BCNF |
Dependencias estrictas |
Cada determinante es una clave candidata |
Minimiza superposiciones complejas |
🏛️ Patrones estructurales avanzados para escalar
La normalización estándar funciona bien para bases de datos transaccionales, pero los sistemas a gran escala a menudo requieren patrones específicos para gestionar la complejidad sin crear uniones excesivas.
Entidades asociativas
Las relaciones muchos a muchos son una fuente principal de redundancia si se manejan mal. En lugar de agregar claves foráneas a ambas tablas relacionadas, crea una tabla asociativa. Esta tabla contiene únicamente las claves foráneas y cualquier atributo específico de la relación misma.
-
Beneficio:Los cambios en los atributos de la relación no requieren modificar las entidades padres.
-
Beneficio:Evita la duplicación de metadatos de relación a través de múltiples filas.
Subtipos y superTipos
Cuando las entidades comparten atributos comunes pero tienen variaciones específicas, usar un patrón de supertipo/subtipo reduce la duplicación de atributos. En lugar de agregar columnas opcionales a una tabla principal que solo aplican a instancias específicas, cree tablas separadas para los subtipos vinculadas por una clave primaria compartida.
-
Beneficio:Mantiene la tabla principal de entidades limpia.
-
Beneficio:Permite restricciones específicas en subtipos sin afectar al padre.
Agregación
La agregación se utiliza cuando una relación tiene atributos que pertenecen a la relación misma, y no a las entidades participantes. En un ERD a gran escala, esto suele aparecer como un enlace de resumen o transaccional entre dos dominios principales.
🧩 Gestión de la complejidad en modelos grandes
A medida que aumenta el número de entidades, el diagrama en sí mismo se convierte en una carga si no se gestiona correctamente. Los ERD a gran escala requieren estrategias de modularización.
Modelos lógicos frente a físicos
Separe el diseño lógico de la implementación física. El modelo lógico se centra en entidades y relaciones sin preocuparse por mecanismos específicos de almacenamiento. El modelo físico maneja el índice, particionado y tipos de datos. Mantenerlos separados evita que las restricciones físicas obliguen a redundancias lógicas.
Diseño modular
Divida el sistema en dominios funcionales. Por ejemplo, separe el dominio de usuarios del dominio de facturación. Cada dominio mantiene su propia consistencia interna. Las interacciones entre dominios ocurren a través de interfaces o claves definidas, en lugar de tablas compartidas.
Manejo de datos históricos
Almacenar versiones históricas de datos puede generar redundancia. En lugar de duplicar filas enteras, utilice columnas de versionado o tablas de auditoría separadas. Esto preserva el estado actual sin llenar la entidad principal con iteraciones pasadas.
🛠️ Errores comunes en el diseño de esquemas
Evitar la redundancia requiere vigilancia. Los errores comunes incluyen:
-
Sobrenormalización:Dividir las tablas de forma tan fina que las consultas requieran joins excesivos, deteriorando el rendimiento. A veces, una cantidad controlada de redundancia está justificada para cargas de trabajo intensivas en lectura.
-
Ignorar dependencias funcionales:Fallar en identificar qué atributos dependen de qué claves conduce a duplicaciones ocultas.
-
Mezclar preocupaciones:Colocar atributos de lógica de negocio en el modelo de datos. Los atributos deben describir los datos, no el proceso.
-
Valores codificados:Almacenar códigos de estado o categorías específicas como cadenas en lugar de referirse a una tabla de búsqueda.
✅ Lista de verificación de verificación y validación
Antes de finalizar un ERD a gran escala, realice una revisión rigurosa. Utilice esta lista de verificación para validar su diseño.
-
Identifique las claves primarias: Asegúrese de que cada tabla tenga un identificador único.
-
Verifique las claves foráneas: Verifique que todas las relaciones se mantengan mediante claves, no mediante la repetición de datos.
-
Analice los atributos: Pregunte si cada atributo no clave depende de la clave, de toda la clave y de nada más que de la clave.
-
Revise la cardinalidad: Asegúrese de que las relaciones uno a muchos se representen mediante una sola clave foránea, no múltiples.
-
Pruebe la entrada de datos: Simule la inserción, actualización y eliminación de registros para verificar anomalías.
🔍 El papel de las restricciones
Las restricciones son la aplicación técnica del diseño. Las restricciones únicas evitan valores duplicados en columnas específicas. Las restricciones de clave foránea garantizan la integridad referencial, evitando registros huérfanos. En sistemas grandes, las definiciones de restricciones deben formar parte de la definición del esquema, no ser una consideración posterior.
Además, considere las restricciones de verificación para limitar el rango de valores. Esto evita que los datos inválidos ingresen al sistema, reduciendo la necesidad de código de manejo de errores más adelante.
📈 Consideraciones de rendimiento
Existe un compromiso entre la normalización y el rendimiento. Los esquemas altamente normalizados requieren combinaciones para reconstruir los datos. En entornos con muchas lecturas, esto puede ralentizar los tiempos de respuesta. Sin embargo, agregar redundancia para acelerar las lecturas puede ralentizar las escrituras debido a la necesidad de actualizar múltiples ubicaciones.
Los motores de bases de datos modernos manejan las combinaciones de forma eficiente. Por lo tanto, el enfoque predeterminado debe favorecer la normalización, a menos que el análisis de datos indique un cuello de botella específico. Si el rendimiento es crítico, considere vistas materializadas o réplicas de lectura en lugar de alterar la estructura básica del esquema.
🔄 Mantenimiento del esquema con el tiempo
Los esquemas de bases de datos evolucionan. Los requisitos cambian y surgen nuevas entidades. Para mantener una baja redundancia con el tiempo:
-
Control de versiones:Trate las definiciones de esquema como código. Registre los cambios en un repositorio.
-
Documentación:Mantenga documentación actualizada que describa relaciones y dependencias.
-
Auditorías regulares:Programar revisiones periódicas del diagrama entidad-relación para identificar nuevos patrones de redundancia.
Al adherirse a estos principios, asegura que la arquitectura de datos permanezca escalable. Un diagrama entidad-relación limpio no es solo cuestión de estética; se trata de crear un sistema más fácil de entender, mantener y ampliar a medida que crece el negocio.
🎯 Reflexiones finales sobre la integridad de los datos
Reducir la redundancia es un proceso continuo. Requiere una comprensión profunda de cómo fluyen los datos a través del sistema y cómo interactúan las relaciones. Al aplicar reglas de normalización, utilizar patrones estructurales avanzados y mantener protocolos de validación estrictos, construye una base que respalda la estabilidad a largo plazo. La inversión realizada en un diseño limpio genera beneficios en costos reducidos de mantenimiento y mayor calidad de los datos.
Enfóquese primero en las relaciones lógicas. Permita que la implementación física sea un reflejo de esa lógica, no una concesión a ella. Con un enfoque disciplinado en el diseño del diagrama entidad-relación, la redundancia se convierte en una variable manejable, no en un obstáculo persistente.