










Diseñar esquemas de bases de datos robustos requiere una comprensión profunda de cómo interactúan las entidades de datos. Entre las estructuras más complejas de gestionar están las relaciones muchos a muchos. Estos escenarios ocurren cuando una instancia única de una entidad está asociada con múltiples instancias de otra, y viceversa. Sin una planificación adecuada, estas conexiones pueden provocar redundancia de datos, problemas de integridad y cuellos de botella significativos en el rendimiento. Esta guía explora la mecánica de optimizar estas relaciones dentro de los Modelos de Entidad-Relación (MER) para garantizar sistemas escalables y mantenibles.
Comprendiendo el desafío principal 🔍
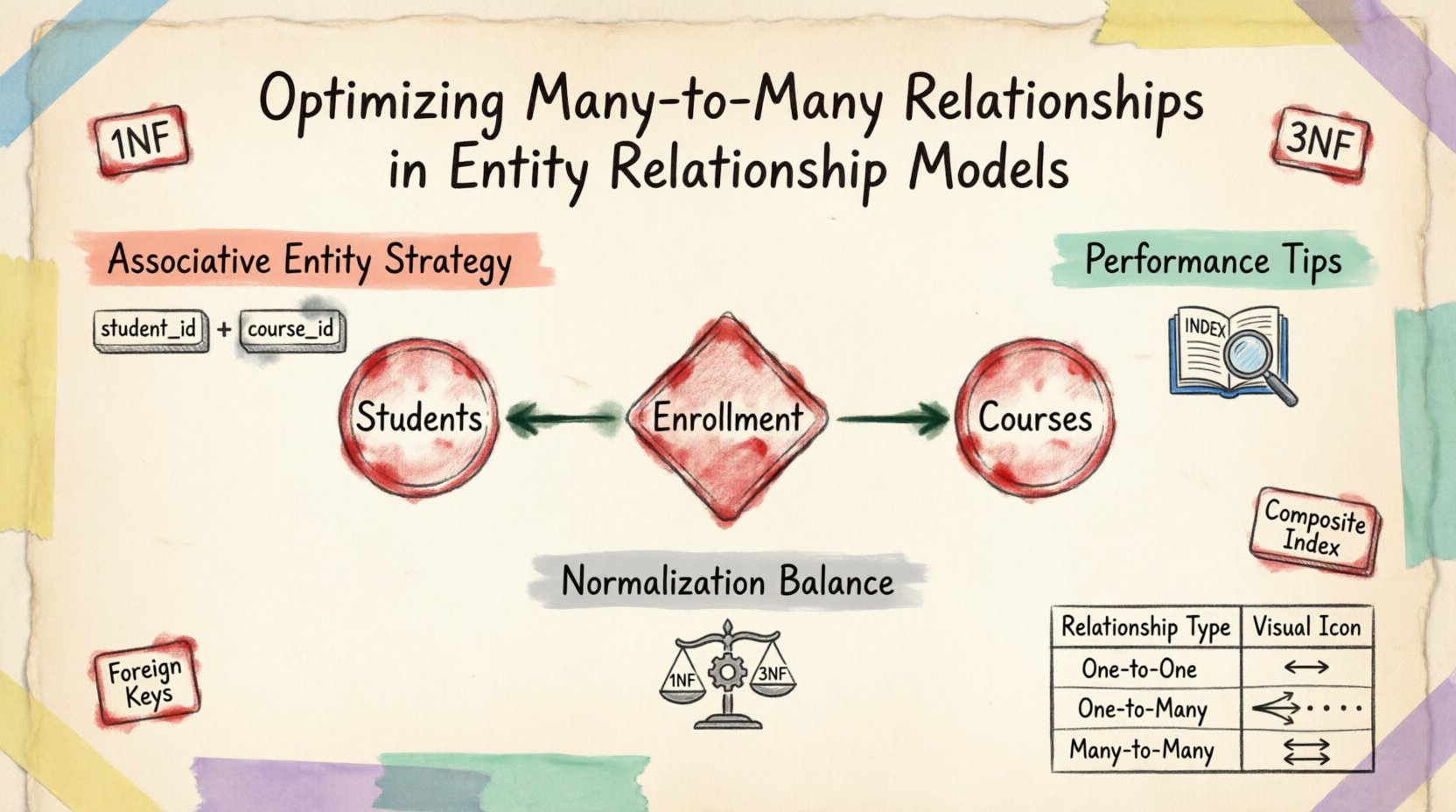
En un modelo conceptual, una relación muchos a muchos es intuitiva. Piense en estudiantes y cursos. Un estudiante se inscribe en múltiples cursos, y cada curso tiene múltiples estudiantes. Representar esto directamente en una estructura de base de datos física es problemático. Las tablas relacionales estándar admiten de forma nativa relaciones uno a muchos y uno a uno mediante claves foráneas. Una relación muchos a muchos requiere una estructura intermedia para funcionar correctamente.
Intentar almacenar múltiples IDs en una sola columna (por ejemplo, una lista separada por comas) viola la Primera Forma Normal (1FN). Este enfoque hace que la consulta, el índice y el mantenimiento de la integridad de los datos sean casi imposibles. La solución consiste en dividir la relación en dos relaciones uno a muchos mediante una entidad asociativa, a menudo denominada tabla de unión o tabla puente.
La estrategia de la entidad asociativa 🧩
La técnica fundamental para resolver las relaciones muchos a muchos es la introducción de una entidad asociativa. Esta entidad actúa como puente entre las dos tablas principales. Contiene claves primarias de ambas entidades principales como claves foráneas, creando una clave primaria compuesta que garantiza la unicidad para cada instancia de relación.
- Estructura: La tabla incluye claves foráneas que hacen referencia a las claves primarias de las entidades relacionadas.
- Unicidad: Una clave compuesta evita relaciones duplicadas entre los mismos dos registros.
- Atributos: Esta tabla puede almacenar datos específicos sobre la relación en sí, no solo sobre las entidades.
Considere un escenario que vincula Empleados y Proyectos. Un empleado trabaja en muchos proyectos, y un proyecto tiene muchos empleados. La tabla de relación podría almacenar la fecha de asignación, el rol del empleado en ese proyecto o las horas asignadas. Estos atributos pertenecen a la relación, no al empleado ni al proyecto individualmente.
Pasos de implementación
- Identificar entidades: Defina las dos entidades distintas involucradas en la relación.
- Crear tabla de unión: Genere una nueva tabla con un nombre descriptivo, como
Asignaciones_Empleado_Proyecto. - Agregar claves foráneas: Inserte columnas para las claves primarias de ambas entidades principales.
- Definir restricciones: Configure restricciones de clave foránea para garantizar la integridad referencial.
- Indexación: Aplicar índices a las columnas de clave foránea para acelerar las operaciones de unión.
Normalización e integridad de datos 🛡️
La optimización a menudo implica un compromiso entre la normalización y el rendimiento. Si bien la normalización reduce la redundancia, las estructuras sobrenormalizadas pueden requerir uniones complejas que ralentizan las consultas. Al optimizar relaciones muchos a muchos, es crucial equilibrar estos factores.
La Tercera Forma Normal (3FN) es generalmente el objetivo para bases de datos operativas. En este estado, la tabla de unión no debe contener dependencias transitivas. Cada atributo no clave debe depender de la clave primaria. Si una tabla de unión contiene datos que dependen únicamente de una de las claves foráneas, debe moverse a la tabla principal correspondiente.
Errores comunes en la normalización
- Claves foráneas redundantes:Incluir la misma clave foránea en múltiples tablas de unión sin una jerarquía clara.
- Falta de restricciones:No aplicar restricciones únicas sobre la combinación de claves foráneas.
- Eliminaciones suaves:No tener en cuenta los registros eliminados en la tabla de relaciones, lo que conduce a datos huérfanos.
Estrategias de optimización de rendimiento ⚡
A medida que crece el volumen de datos, el número de filas en una tabla de unión puede aumentar exponencialmente. Esto afecta directamente los tiempos de ejecución de las consultas. Varias estrategias pueden mitigar la degradación del rendimiento.
1. Indexación estratégica
Los índices son cruciales para el rendimiento de las uniones. Un índice compuesto sobre las columnas de claves foráneas suele ser más eficaz que los índices individuales. Esto permite al motor de base de datos localizar filas relacionadas más rápido sin escanear toda la tabla.
- Índices agrupados:En algunos sistemas, agrupar la tabla por la clave compuesta puede mejorar las consultas de rango.
- Índices cubiertos:Incluir columnas frecuentemente consultadas en el índice puede eliminar la necesidad de acceder al montón de la tabla.
2. Particionado
Cuando una tabla de unión se vuelve demasiado grande para gestionarla de forma eficiente, el particionado por fecha o región puede distribuir la carga. Esto es especialmente útil para datos históricos, donde las relaciones recientes se acceden con mayor frecuencia que las antiguas.
3. Optimización de consultas
Las consultas complejas que implican múltiples uniones pueden sobrecargar los recursos. Usar sugerencias de consulta o reestructurar el SQL para minimizar subconsultas puede ayudar. También es importante analizar el plan de ejecución para identificar cuellos de botella.
| Estrategia | Beneficio | Compromiso |
|---|---|---|
| Indexación compuesta | Recuperación de unión más rápida | Aumento del almacenamiento y sobrecarga de escritura |
| Particionado de tablas | Mejora en el mantenimiento y velocidad de escaneo | Complejidad en la lógica de consulta |
| Caché | Carga reducida en la base de datos | Riesgos de consistencia de datos |
Manejo de atributos de relación 📝
Una de las mayores ventajas de la entidad asociativa es la capacidad de almacenar atributos específicos de la relación. Por ejemplo, en un sistema de gestión de contratos, un Proveedor y un Producto tienen una relación muchos a muchos. Los atributos podrían incluir el precio unitario, la fecha de inicio del contrato y la cantidad acordada.
Si intentas almacenar estos atributos en la tabla de Proveedor o Producto, creas redundancia. Si el precio cambia, tendrías que actualizar múltiples filas en la tabla de productos. Al colocarlos en la tabla de unión, mantienes una única fuente de verdad para esa instancia específica de relación.
Escenarios avanzados y casos límite 🌐
La modelización de datos en el mundo real a menudo presenta desafíos únicos que los patrones estándar no abordan de inmediato.
- Relaciones de auto-referencia: Una entidad relacionada consigo misma (por ejemplo, un Empleado que gestiona a otros Empleados). Esto requiere una clave foránea que apunte a la clave primaria de la misma tabla.
- Eliminaciones en cascada: Decidir si eliminar una entidad padre debe eliminar automáticamente sus registros de relación. Esto evita claves foráneas huérfanas, pero podría perder datos históricos de asociación.
- Relaciones recursivas: Jerarquías complejas en las que la tabla de unión apunta a sí misma.
Consulta del esquema optimizado 🔎
Una vez que el esquema está optimizado, consultarlo requiere precisión. Los desarrolladores deben entender cómo el motor de base de datos recorre los caminos de unión.
Al recuperar datos, como todos los proyectos de un empleado específico, la consulta debe unir la tabla Empleado con la tabla de unión, y luego con la tabla Proyecto. Escribir SQL de forma eficiente asegura que la base de datos utilice correctamente los índices disponibles. Evitar funciones en columnas indexadas en la WHEREcláusula es una práctica estándar para mantener la utilización de índices.
Mejores prácticas para la lógica de unión
- Usa uniones explícitas:Preferir
INNER JOINoLEFT JOINsobre tablas implícitas separadas por comas. - Limita columnas:Selecciona únicamente las columnas necesarias para reducir la transferencia de red y el tiempo de procesamiento.
- Filtra temprano:Aplica filtros en la
WHEREcláusula antes de que ocurra la unión, si es posible.
Comparando tipos de relación 📊
Comprender dónde encaja el tipo de relación muchos a muchos en el contexto más amplio de modelado de datos ayuda a tomar mejores decisiones de diseño.
| Tipo de relación | Estructura | Ejemplo de caso de uso |
|---|---|---|
| Uno a uno | Clave foránea única | Perfil de usuario y configuración de usuario |
| Uno a muchos | Clave foránea única | Pedido y artículos del pedido |
| Muchos a muchos | Tabla de unión | Estudiantes y cursos |
Mantenimiento de la consistencia de los datos 🔄
Asegurar que los datos permanezcan consistentes entre las tablas relacionadas es fundamental. Esto a menudo implica la gestión de transacciones. Una transacción debe envolver la inserción de datos en la tabla principal y en la tabla de unión. Si alguna de las dos operaciones falla, toda la operación debe deshacerse para evitar estados parciales de datos.
También se pueden utilizar desencadenadores para imponer lógica de negocio, aunque deben usarse con moderación para evitar costos ocultos de rendimiento. Por ejemplo, un desencadenador podría impedir que un empleado sea asignado a un proyecto si su departamento no coincide con el del proyecto.
Monitoreo y mantenimiento 📈
Una vez desplegado, el sistema requiere monitoreo continuo. El crecimiento en la tabla de unión suele ser la primera señal de problemas de escalabilidad. Son necesarias auditorías regulares del tamaño de las tablas, la fragmentación de índices y las métricas de rendimiento de las consultas.
- Archivado:Mover los datos históricos de relación a almacenamiento frío si ya no se consultan activamente.
- Reindexación:Reconstruir o reorganizar periódicamente los índices para mantener un rendimiento óptimo.
- Revisión de combinaciones:Asegurarse de que los cambios en la aplicación no introduzcan patrones de consulta ineficientes.
Reflexiones finales sobre el diseño de esquemas 🎯
Optimizar las relaciones muchos a muchos no es una tarea única, sino un proceso continuo de refinamiento. Requiere un equilibrio entre la corrección teórica y el rendimiento práctico. Al adherirse a los principios de normalización, utilizar entidades asociativas y aplicar un índice estratégico, los arquitectos de bases de datos pueden construir sistemas que sean tanto robustos como eficientes. El objetivo es crear una estructura que apoye la lógica de negocio sin imponer restricciones innecesarias en la recuperación o modificación de datos.