











Las bases de datos relacionales se construyen sobre la base de tablas y filas, una estructura diseñada para datos planos. Sin embargo, el mundo real rara vez se adhiere a una simplicidad así. Las organizaciones, los sistemas de archivos, los hilos de comentarios y los árboles de categorías todos existen en estructuras jerárquicas. Representar estas relaciones padre-hijo en un diagrama estándar de entidad-relación (ERD) requiere patrones de diseño específicos que mantienen la integridad de los datos al tiempo que permiten una recuperación eficiente.
Cuando intentas mapear una estructura de árbol sobre un esquema plano, te enfrentas a la tensión clásica entre normalización y rendimiento. Esta guía explora las técnicas fundamentales para modelar datos jerárquicos, evaluando las compensaciones de cada enfoque para ayudarte a diseñar sistemas robustos.
🧩 El desafío de los esquemas planos
Un diagrama de entidad-relación suele visualizar entidades como cuadros y relaciones como líneas. En una relación estándar, una tabla se vincula con otra mediante una clave foránea. Esto funciona perfectamente para escenarios muchos a muchos o uno a muchos donde la dirección es fija. Pero ¿qué sucede cuando una categoría puede tener subcategorías, que a su vez pueden tener sub-subcategorías, potencialmente de forma infinita?
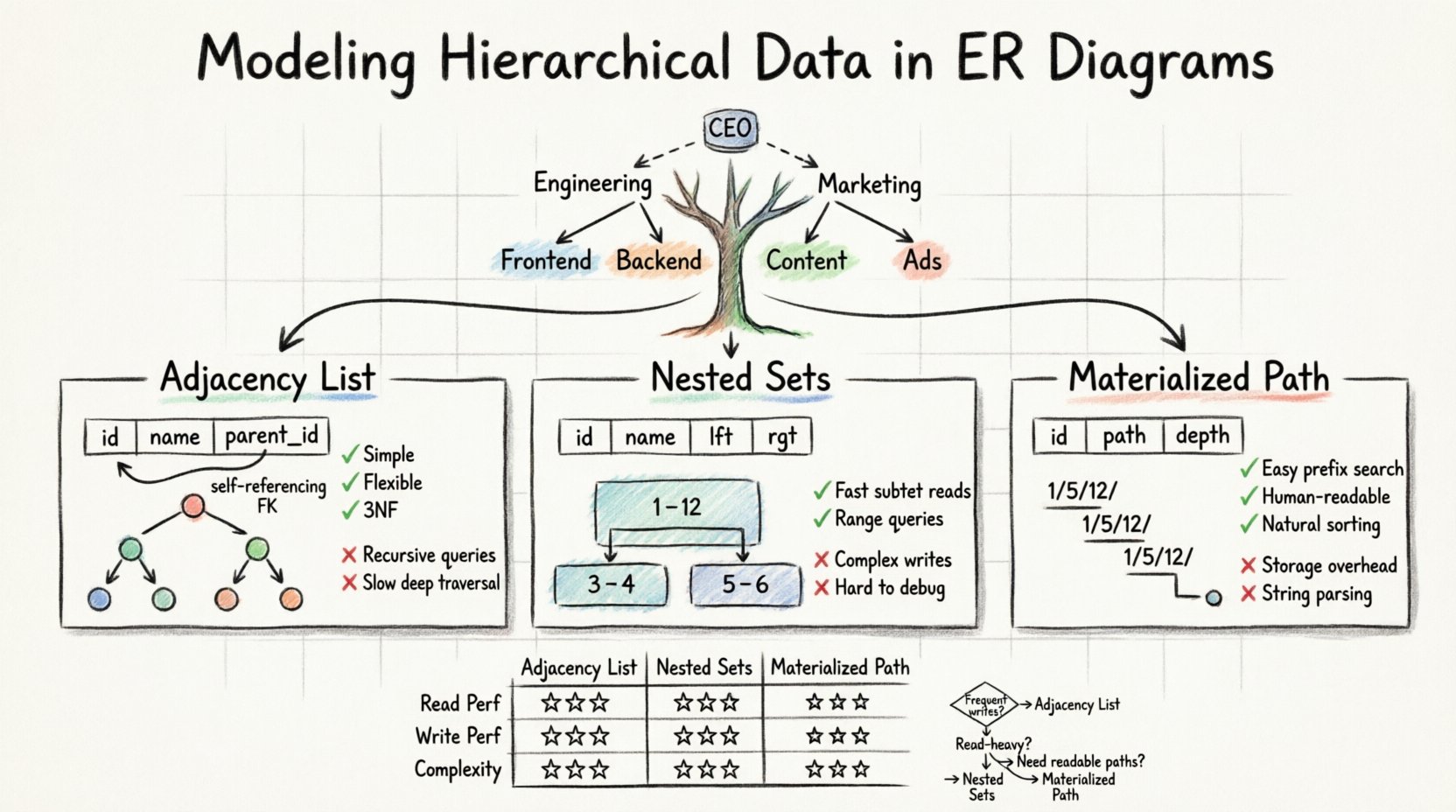
Los modelos relacionales estándar tienen dificultades con profundidades variables. Una tabla plana no puede almacenar fácilmente una ruta de longitud arbitraria. Para resolver esto, debemos adaptar el esquema para almacenar la jerarquía explícitamente. Existen tres patrones principales utilizados por los arquitectos de datos para lograr esto:
- Lista de adyacencia: Almacenar el ID del padre dentro del registro del hijo.
- Conjuntos anidados: Asignar valores izquierdo y derecho para definir rangos.
- Enumeración de caminos: Almacenar la ruta completa desde la raíz hasta el nodo actual.
🔗 El modelo de lista de adyacencia
La lista de adyacencia es el método más común y sencillo para representar jerarquías en un ERD estándar. Se basa en una relación auto-referenciada. Esto significa que una sola tabla contiene una columna que hace referencia a su propia clave primaria.
📐 Estructura del esquema
En este modelo, creas una sola tabla para almacenar los datos. Cada fila representa un nodo en el árbol. La adición crítica es una columna, a menudo denominada parent_id o ancestor_id, que almacena el identificador único del nodo padre. Si un nodo está en la cima de la jerarquía, esta columna contiene un valor nulo.
Considera una tabla para Departamento:
- id: La clave primaria única para el departamento.
- nombre: El nombre que se muestra del departamento.
- parent_id: El ID del departamento superior (puede ser nulo para el nivel superior).
✅ Ventajas
- Simplicidad: El esquema es intuitivo y fácil de entender para desarrolladores y administradores de bases de datos.
- Flexibilidad: Mover un subárbol es sencillo; solo necesitas actualizar el
parent_iddel nodo raíz de ese subárbol. - Normalización: Cumple bien con la Tercera Forma Normal (3NF) ya que los datos no se repiten.
❌ Desventajas
- Complejidad de las consultas: Recuperar todos los descendientes requiere consultas recursivas o procesamiento del lado de la aplicación.
- Rendimiento: Los recorridos profundos pueden ser lentos sin estrategias de indexación específicas o expresiones de tabla común recursivas (CTEs).
- Integridad referencial: Aunque las claves foráneas ayudan, las referencias circulares aún pueden ocurrir si las restricciones no se aplican estrictamente.
🌲 El modelo de conjunto anidado
El modelo de conjunto anidado transforma la estructura de árbol en un conjunto de intervalos. En lugar de rastrear punteros al padre, cada nodo recibe dos números: izquierda y derecha. Estos valores representan la posición del nodo en un recorrido en orden previo del árbol.
📐 Estructura del esquema
Imagina un árbol donde el nodo raíz es el conjunto completo. Al recorrer el árbol, incrementas un contador. Cuando entras en un nodo, registras el conteo actual como izquierda. Cuando terminas de procesar ese nodo y todos sus hijos, registras el conteo como derecha. El derecha el valor siempre es mayor que el izquierda valor.
Un Categoría tabla tendría este aspecto:
- id: Identificador único.
- nombre: Nombre de la categoría.
- izq: El valor del límite izquierdo.
- der: El valor del límite derecho.
✅ Ventajas
- Recuperación rápida: Recuperar un subárbol es una consulta de rango simple usando
ENTRElógica. - Eficiencia: El rendimiento de lectura es superior para árboles grandes y profundos en comparación con las listas de adyacencia.
❌ Desventajas
- Costo de escritura: Insertar o mover un nodo es costoso. Debes actualizar los valores de
izqyderde muchos otros nodos para mantener la integridad de los intervalos. - Complejidad: La lógica es difícil de implementar y depurar sin el soporte de una biblioteca especializada.
🛣️ Enumeración de caminos y rutas materializadas
Los métodos de enumeración de caminos almacenan la línea de un nodo como una cadena o una lista delimitada. A este enfoque a menudo se le llama patrón de ruta materializada. Combina la simplicidad de la lista de adyacencia con la legibilidad de la ruta.
📐 Estructura del esquema
En este modelo, cada registro almacena la ruta completa desde la raíz. Por ejemplo, en un modelo de sistema de archivos, un archivo podría tener una cadena de ruta como/home/user/documents/report.txt. En una base de datos, esto a menudo se almacena como una cadena delimitada dentro de la columna, como1/5/12/.
La tabla incluye:
- id: Clave primaria.
- ruta: Una cadena que representa la línea de descendencia.
- profundidad: Un entero que indica cuántos niveles de profundidad tiene el nodo.
✅ Ventajas
- Recorrido fácil: Puedes encontrar todos los descendientes al coincidir con el prefijo de la ruta.
- Legibilidad: Los datos son legibles por humanos y fáciles de depurar.
- Ordenación: Ordenar por la cadena de ruta a menudo produce el orden correcto del árbol de forma natural.
❌ Desventajas
- Sobrecarga de almacenamiento: Las rutas largas pueden consumir una cantidad significativa de espacio de almacenamiento.
- Análisis de cadenas: Las consultas a menudo requieren funciones de manipulación de cadenas, que pueden ser más lentas que las comparaciones de enteros.
📊 Análisis comparativo
Elegir el modelo adecuado depende en gran medida de la relación de lectura frente escritura y de la profundidad de su jerarquía. La siguiente tabla describe las características de cada método.
| Característica | Lista de adyacencia | Conjuntos anidados | Ruta materializada |
|---|---|---|---|
| Rendimiento de lectura | Bajo a medio | Alto | Medio a alto |
| Rendimiento de escritura | Alto | Bajo | Medio |
| Complejidad de implementación | Bajo | Alto | Medio |
| Soporta árboles profundos | Sí | Sí | Sí (con límites) |
| Lógica de consulta | Recursivo | Escaneo de rango | Coincidencia de prefijo |
⚙️ Consideraciones de rendimiento
Al modelar jerarquías, debe considerar cómo maneja el motor de base de datos los datos. Las estrategias de indexación juegan un papel fundamental independientemente del modelo elegido.
- Lista de adyacencia: Indexe la
parent_idcolumna intensamente. Esto permite al motor de base de datos localizar rápidamente todos los hijos de un nodo específico sin escanear toda la tabla. - Conjuntos anidados: Índice ambos
izqyder. Los índices compuestos pueden optimizar significativamente las consultas de rango. - Ruta materializada: Índice la
rutacolumna. Dependiendo de la base de datos, un índice de prefijo podría ser beneficioso para filtrar subárboles.
🛠️ Mantenimiento y actualizaciones
Los modelos de datos no son estáticos. A medida que crece su organización, su jerarquía cambiará. Mover un nodo de una rama a otra es una operación común que afecta a cada modelo de manera diferente.
🔄 Moviendo nodos
En un Lista de adyacencia, mover un nodo es una sola sentencia de actualización. Cambia el id_padre de la raíz del subárbol. Sin embargo, debes asegurarte de que no se creen referencias circulares.
En un Conjunto anidadomodelo, mover un nodo es complejo. Implica recalcular los valores de izq y der para todos los nodos en el subárbol de destino para hacer espacio para el nodo movido. Esta operación suele ser transaccional y requiere múltiples actualizaciones de tablas.
En un Ruta materializadamodelo, actualizas la cadena de ruta del nodo movido y de todos sus descendientes. Esto requiere actualizar la ruta de cada hijo, lo que puede ser una operación de escritura intensa para árboles grandes.
🎯 Mejores prácticas para el modelado de datos
Para asegurarte de que tu diagrama ERD permanezca mantenible y eficiente, sigue estas directrices al implementar estructuras jerárquicas.
- Utiliza convenciones de nombres claras: Evite nombres genéricos como
col1. Useparent_id,ancestor_id,lft, orgtexplícitamente. - Aplicar restricciones: Use restricciones de base de datos para evitar referencias circulares. Un nodo no puede ser su propio antecesor.
- Limitar profundidad: Aunque técnicamente posible, jerarquías extremadamente profundas (por ejemplo, más de 10 niveles) a menudo indican un defecto de diseño. Considere aplanar la estructura si es posible.
- Documentar la elección: Dado que estos patrones no son características estándar de SQL, documente qué patrón se utiliza en la documentación del esquema.
- Considerar enfoques híbridos: Algunos sistemas combinan listas de adyacencia con rutas materializadas para equilibrar el rendimiento de lectura y escritura.
🧠 Elegir la estrategia adecuada
No existe una única respuesta ‘correcta’ para cada escenario. La decisión depende de los requisitos específicos de su aplicación.
- Elija lista de adyacencia si: Sus datos cambian con frecuencia y la profundidad de la jerarquía es moderada. Este es el valor predeterminado más seguro para la mayoría de las aplicaciones generales.
- Elija conjuntos anidados si: Tiene una aplicación con carga pesada de lectura, donde los datos rara vez se mueven, y necesita recuperar grandes subárboles rápidamente.
- Elija ruta materializada si: Necesita rutas legibles para humanos (como URLs) y la profundidad de la jerarquía es relativamente baja.
Comprender estas sutilezas estructurales le permite diseñar bases de datos escalables. Al seleccionar el patrón adecuado para su diagrama de relaciones de entidades, garantiza que sus datos permanezcan consistentes, accesibles y eficientes durante todo el ciclo de vida del sistema.