










El rendimiento de la base de datos a menudo depende de factores invisibles para el observador casual. Uno de estos factores críticos es la contención de bloqueos. Cuando múltiples usuarios o procesos intentan acceder a los mismos datos simultáneamente, el sistema debe imponer reglas para mantener la integridad de los datos. Estas reglas generan bloqueos. Un bloqueo excesivo conduce a cuellos de botella, ralentiza los tiempos de respuesta y frustra a los usuarios finales. La causa raíz a menudo no reside en el hardware, sino en el Diagrama Entidad-Relación (ERD) que define la estructura de los datos.
Un esquema bien diseñado actúa como la base para una alta concurrencia. Al anticipar cómo se accederá y modificará los datos, los arquitectos pueden estructurar las tablas para minimizar los conflictos. Este enfoque requiere un profundo conocimiento de la aislamiento de transacciones, las estrategias de indexación y la mecánica física de los bloqueos. La siguiente guía detalla cómo optimizar su modelo de datos para un mejor rendimiento sin depender de herramientas externas.
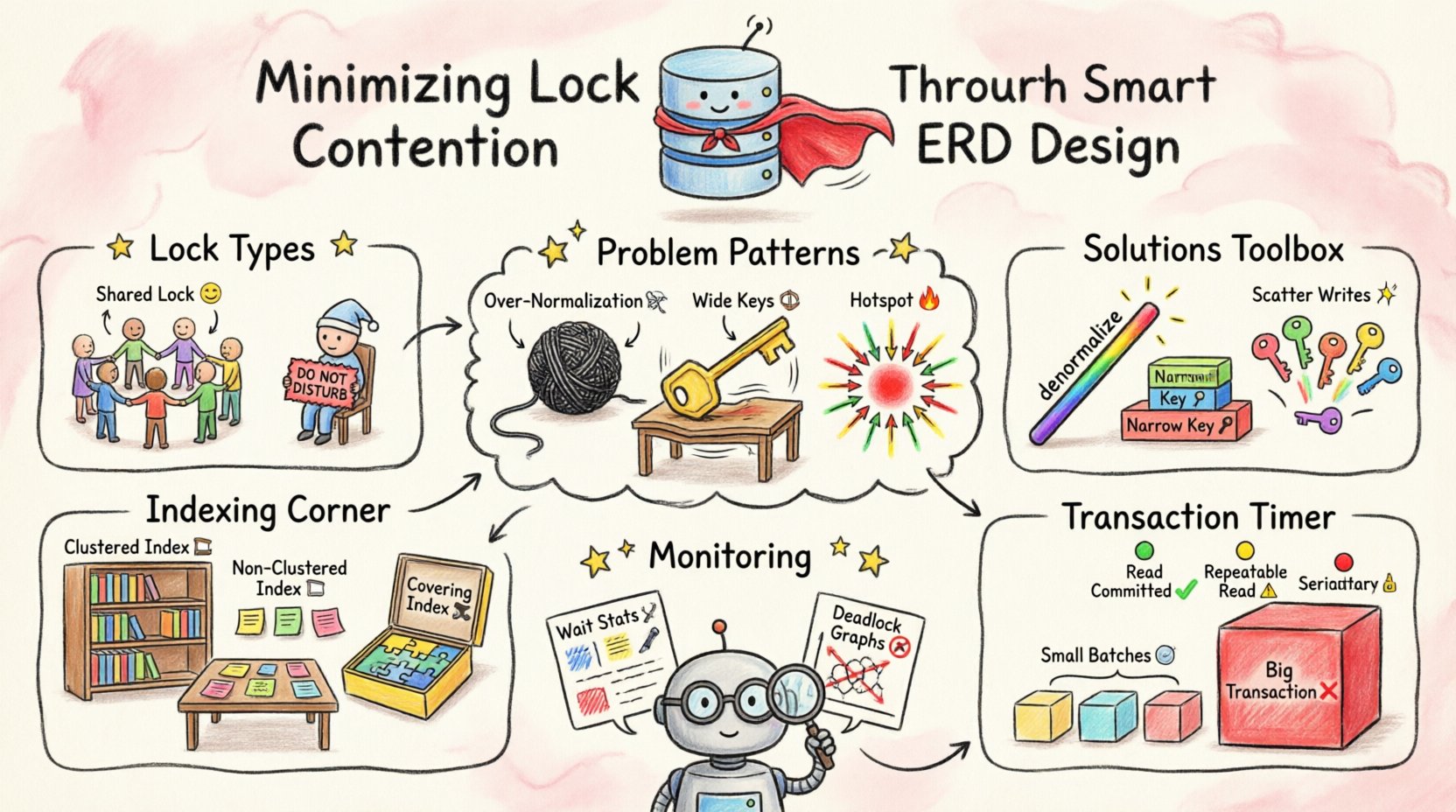
Comprender los mecanismos de bloqueo 🛡️
Antes de optimizar el diseño, es esencial comprender qué hacen realmente los bloqueos. Las bases de datos utilizan bloqueos para prevenir inconsistencias. Si dos transacciones intentan actualizar la misma fila en el mismo momento exacto, se produce un conflicto. El sistema debe decidir quién pasa primero.
- Bloqueos compartidos (S):Utilizados para leer datos. Varias transacciones pueden mantener bloqueos compartidos sobre el mismo recurso simultáneamente.
- Bloqueos exclusivos (X):Utilizados para escribir o modificar datos. Solo una transacción puede mantener un bloqueo exclusivo sobre un recurso en cualquier momento.
- Bloqueos de intención:Indican que una transacción tiene la intención de colocar un bloqueo en un nivel inferior de la jerarquía, como una tabla o página.
La contención de bloqueos surge cuando la demanda de bloqueos exclusivos supera la capacidad de acceso compartido. Si su ERD obliga a la base de datos a escanear grandes porciones de una tabla para encontrar datos, aumenta el alcance de los bloqueos mantenidos. Esto amplifica la probabilidad de colisiones entre procesos concurrentes.
Patrones de esquema que generan contención 📉
Algunas decisiones de diseño aumentan inherentemente el área de superficie para bloqueos. Reconocer estos patrones le permite refactorizar temprano en el ciclo de desarrollo.
1. Sobrenormalización
Si bien la normalización reduce la redundancia, una normalización excesiva puede perjudicar el rendimiento. Unir muchas tablas para recuperar un solo registro requiere bloquear múltiples filas en múltiples tablas. Si una transacción necesita leer datos de cinco tablas normalizadas, adquiere bloqueos en todas ellas.
- El riesgo:Si otra transacción modifica una de esas tablas, la primera transacción podría tener que esperar.
- La solución:Considere la desnormalización de columnas frecuentemente unidas. Reducir el número de uniones disminuye el número de bloqueos necesarios por consulta.
2. Claves primarias amplias
Las claves primarias se utilizan para identificar filas de forma única. Si una clave primaria es una clave compuesta que abarca múltiples columnas, afecta cómo se construyen los índices. Las claves amplias aumentan el tamaño del índice.
- El riesgo:Los índices más grandes significan más páginas que leer y bloquear durante las búsquedas. Las actualizaciones en la clave primaria pueden desencadenar cambios en cascada en tablas relacionadas.
- La solución:Utilice claves sustitutas simples y estrechas (como enteros) cuando sea posible. Mantenga las claves compuestas mínimas y solo cuando sea lógicamente necesario.
3. Puntos calientes en claves secuenciales
Utilizar enteros autoincrementales para las claves primarias es común. Sin embargo, si la aplicación inserta datos de forma secuencial, todas las nuevas escrituras apuntan al final del índice. Esto crea un “punto caliente” donde muchas transacciones compiten por la misma página hoja.
- El riesgo:El motor de la base de datos debe bloquear la última página del índice para cada nueva inserción.
- La solución:Utilice claves aleatorizadas o distribuciones basadas en hash para escenarios de alta escritura para distribuir la carga entre diferentes páginas.
Estrategias para la optimización de esquemas 🛠️
Optimizar el diagrama ER implica tomar decisiones específicas sobre columnas, relaciones y restricciones. La tabla a continuación describe decisiones de diseño comunes y su impacto en el comportamiento de bloqueo.
| Decisión de diseño | Impacto en el bloqueo | Enfoque recomendado |
|---|---|---|
| Restricciones de clave externa | Puede causar bloqueos en cadena en las tablas padre. | Utilice restricciones diferidas o validación a nivel de aplicación para sistemas de alta escritura. |
| Columnas grandes de BLOB/texto | Aumenta el tamaño de fila, lo que requiere más páginas por fila. | Almacene datos grandes por separado para mantener la tabla principal estrecha. |
| Columnas de alta cardinalidad | Puede provocar un uso ineficiente del índice. | Asegúrese de que las columnas selectivas estén indexadas para evitar escaneos de tabla. |
| Valores predeterminados | Actualiza filas innecesariamente si se aplican valores predeterminados. | Permita valores NULL cuando sea apropiado para evitar desencadenadores de escritura. |
Desacoplamiento de modelos de escritura y lectura
Separar el esquema utilizado para escritura del esquema utilizado para lectura puede reducir significativamente la contención. Los modelos de escritura se enfocan en la integridad y normalización. Los modelos de lectura se enfocan en la velocidad y la desnormalización.
- Almacene los datos en una estructura altamente normalizada para el procesamiento de transacciones.
- Replica los datos en una estructura optimizada para lectura para informes o visualización.
- Esto garantiza que las consultas de lectura intensivas no bloqueen las operaciones de escritura.
Indexación y elección de claves 📊
Los índices son vitales para el rendimiento, pero no son gratuitos. Cada índice debe mantenerse durante una actualización. Si una tabla tiene demasiados índices, cada inserción o actualización requiere bloquear múltiples estructuras de índice.
Clusterizado frente a no clusterizado
- Índice clusterizado:Determina el orden físico de los datos. Normalmente solo hay uno por tabla. Elija este con cuidado, ya que afecta cómo se almacenan los datos.
- Índice no clusterizado: Una estructura separada que apunta a los datos. Útil para cubrir consultas sin tocar la tabla principal.
Evite crear índices en columnas que se actualizan con frecuencia. Cuando cambia el valor de una columna, el índice debe reconstruirse. Este proceso genera bloqueos de escritura en la estructura del índice.
Índices cubrientes
Un índice cubriente incluye todas las columnas necesarias para una consulta. Esto permite que la base de datos satisfaga la solicitud sin tener que buscar los datos reales de la tabla. Esto reduce el alcance de los bloqueos mantenidos, ya que el motor no necesita bloquear las filas de la tabla base.
- Identifique consultas de lectura frecuentes.
- Cree índices que incluyan las
SELECTcolumnas. - Monitoree los planes de ejecución de consultas para asegurarse de que se están utilizando estos índices.
Alcance y aislamiento de transacciones ⏱️
El diagrama ER influye en cómo se comportan las transacciones. Las transacciones de larga duración mantienen los bloqueos durante períodos más largos. Un esquema bien estructurado ayuda a mantener las transacciones cortas.
Procesamiento por lotes
En lugar de procesar miles de filas en una sola transacción, divida el trabajo en lotes más pequeños. Esto libera los bloqueos antes, permitiendo que otros procesos continúen.
- Límite el número de filas modificadas por confirmación.
- Use cursores o bucles para procesar datos por trozos.
- Equilibre la sobrecarga de múltiples confirmaciones frente al beneficio de una duración de bloqueo reducida.
Niveles de aislamiento
Los sistemas de bases de datos ofrecen diferentes niveles de aislamiento. Los niveles de aislamiento más altos (como Serializable) previenen más anomalías, pero aumentan el bloqueo. Los niveles de aislamiento más bajos (como Read Committed) permiten más concurrencia.
- Evite Serializable a menos que sea estrictamente necesario para la precisión financiera.
- Use Read Committed o Repeatable Read para la mayoría de las tareas operativas.
- Alinee el nivel de aislamiento con el requisito del negocio para la consistencia de los datos.
Monitoreo e iteración 🔄
El diseño no es una actividad única. A medida que cambian los patrones de uso, también cambian los problemas de contención de bloqueos. Se requiere un monitoreo continuo para mantener el rendimiento.
- Estadísticas de espera:Monitoree cuánto tiempo las transacciones esperan por bloqueos.
- Gráficos de interbloqueos:Analice diagramas que muestren qué consultas causaron interbloqueos.
- Rendimiento de consultas:Identifique consultas lentas que podrían estar manteniendo bloqueos más tiempo del esperado.
Revise regularmente el diagrama ER frente a las métricas de rendimiento actuales. Si una tabla específica muestra tiempos de espera altos de forma consistente, considere particionar los datos o ajustar el esquema para reducir la carga.
Consideraciones finales sobre la arquitectura de datos 🧩
Minimizar la contención de bloqueos es un equilibrio entre la integridad de los datos y el rendimiento del sistema. Al diseñar esquemas teniendo en cuenta la concurrencia, reduces la necesidad de que el motor de base de datos resuelva conflictos. Esto conduce a tiempos de respuesta más rápidos y un sistema más estable.
Comienza auditando tus relaciones y claves actuales. Busca oportunidades para simplificar las uniones y reducir el crecimiento excesivo de índices. Prueba tus cambios en un entorno de preproducción para verificar el impacto en el comportamiento de bloqueo. Con una planificación cuidadosa y atención al detalle, puedes construir una capa de datos robusta que se escala de forma efectiva.