











Diseñar un esquema de base de datos rara vez es una elección binaria entre velocidad y estructura. Es un ejercicio de compromiso. Cuando los arquitectos construyen diagramas entidad-relación (ERD), a menudo enfrentan la tensión entre la integridad estricta de los datos y la velocidad cruda necesaria para aplicaciones de alto volumen. La normalización minimiza la redundancia, asegurando que los datos permanezcan consistentes. Sin embargo, el costo de mantener esa consistencia a menudo se paga en rendimiento de lectura.
Este artículo explora las sutilezas técnicas de este equilibrio. Examinaremos cómo la normalización afecta las uniones, cómo las cargas de trabajo intensivas en lectura dictan cambios en el esquema y dónde se traza la línea entre una base de datos bien estructurada y una de alto rendimiento.
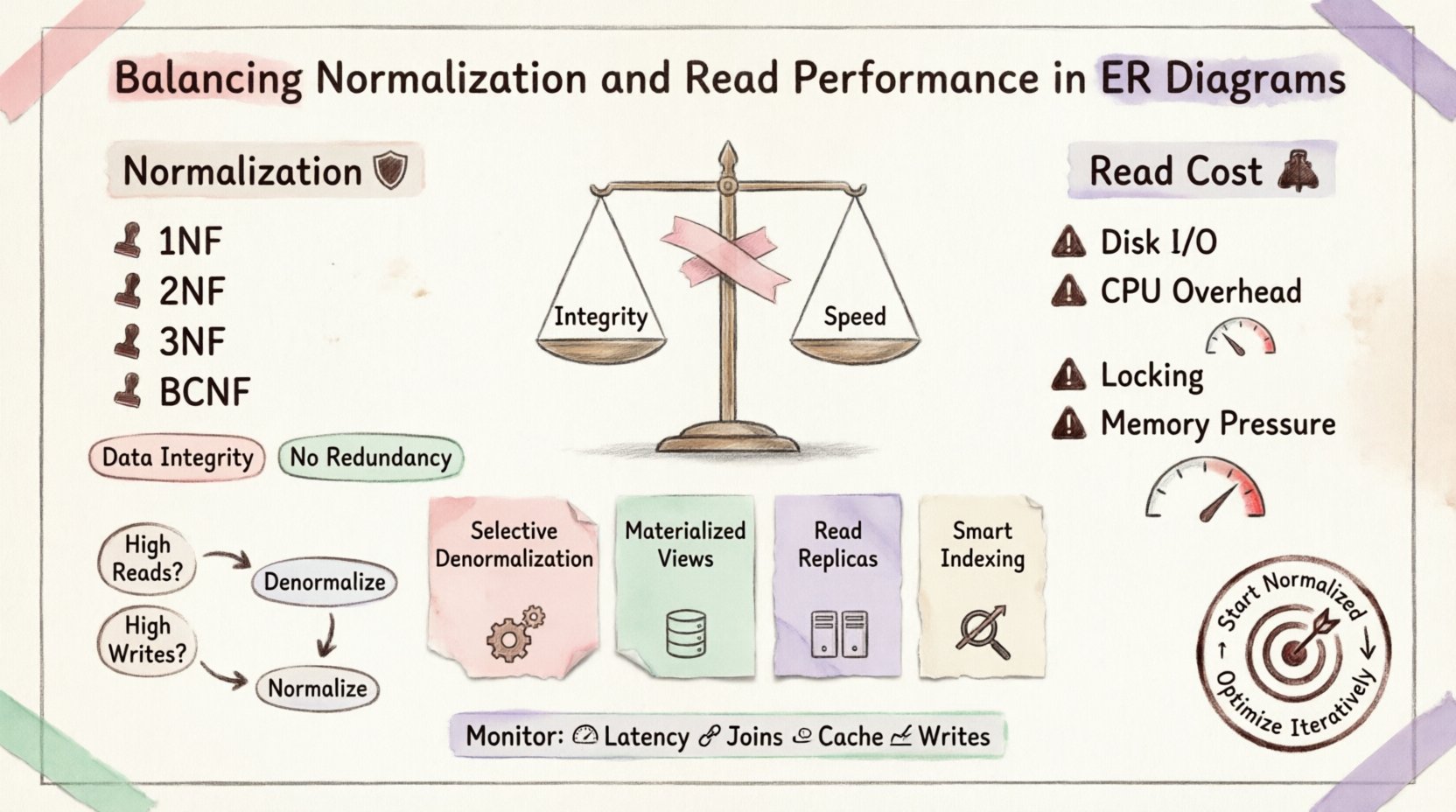
Comprender la normalización: la base 🛡️
La normalización es el proceso de organizar los datos para reducir la redundancia y mejorar la integridad de los datos. Implica dividir tablas grandes en otras más pequeñas y lógicas, y definir relaciones entre ellas. El objetivo es eliminar anomalías durante la inserción, actualización y eliminación.
Formas normales clave
-
Primera Forma Normal (1FN):Garantiza atomicidad. Cada columna contiene solo un valor. Sin grupos repetidos.
-
Segunda Forma Normal (2FN):Se basa en la 1FN. Todos los atributos no clave deben depender completamente de la clave primaria. Elimina dependencias parciales.
-
Tercera Forma Normal (3FN):Se basa en la 2FN. Elimina dependencias transitivas. Los atributos no clave dependen únicamente de la clave, de la clave completa y de nada más que de la clave.
-
Forma Normal de Boyce-Codd (BCNF):Una versión más estricta de la 3FN para manejar anomalías de dependencia específicas.
Aunque seguir estas formas garantiza una base de datos limpia, introduce complejidad en las consultas. Cada relación definida en el diagrama ER se convierte en una operación de unión potencial.
El costo de las lecturas 💸
Cuando normalizas los datos, a menudo divides la información entre múltiples tablas. Para recuperar un registro completo, el motor de base de datos debe realizar operaciones de unión. Las uniones son computacionalmente costosas.
Por qué las uniones ralentizan las consultas
-
Entrada/Salida de disco:Si las tablas no están perfectamente indexadas o almacenadas en caché, el motor debe buscar datos en diferentes ubicaciones físicas del disco.
-
Sobrecarga de CPU:La base de datos debe coincidir claves de una tabla con otra. Esto requiere una potencia de procesamiento significativa.
-
Contención de bloqueos:Las uniones complejas pueden mantener los bloqueos durante más tiempo, bloqueando otras transacciones que intentan acceder a datos relacionados.
-
Presión de memoria:Las operaciones de unión grandes requieren buffers de memoria sustanciales para ordenar y aplicar hash a los datos.
En un entorno intensivo en lecturas, como un panel de informes o una API de acceso público, esta latencia es inaceptable. Los usuarios esperan una respuesta instantánea. Una consulta que tarda 100 milisegundos en devolver datos normalizados podría tardar solo 10 milisegundos si los datos están desnormalizados.
Estrategias de optimización 🚀
Para equilibrar la integridad y la velocidad, los arquitectos emplean patrones específicos. Estas estrategias te permiten mantener la base de datos normalizada donde más importa, al tiempo que optimizas para lecturas donde realmente importa.
1. Desnormalización selectiva
No todas las tablas necesitan estar completamente normalizadas. Identifique los datos más frecuentemente accedidos y almacénelos de forma redundante. Por ejemplo, si consulta con frecuencia los nombres de usuario junto con su historial de pedidos, almacenar el nombre de usuario directamente en la tabla de pedidos ahorra una unión.
2. Vistas materializadas
Una vista materializada almacena el resultado de una consulta físicamente en disco. Esencialmente, es una tabla precalculada. Cuando los datos cambian, la vista debe actualizarse. Esto es ideal para agregaciones complejas que no requieren precisión en tiempo real.
3. Réplicas de lectura
Separe la carga de lectura de la carga de escritura. Dirija todas las operaciones de escritura a la base de datos principal, que permanece normalizada. Dirija todas las operaciones de lectura a una réplica. Esto permite optimizar la réplica de forma diferente, quizás con más índices o estructuras desnormalizadas, sin afectar la integridad transaccional.
4. Estrategia de índices
Incluso las bases de datos normalizadas pueden funcionar bien con los índices adecuados. Los índices cubiertos permiten que la base de datos satisfaga una consulta utilizando solo el índice, evitando búsquedas en la tabla. Los índices compuestos pueden acelerar las uniones en claves foráneas comunes.
Cuándo desnormalizar 📉
La desnormalización es una decisión deliberada, no un estado predeterminado. Debe tomarse basándose en evidencia obtenida del monitoreo del rendimiento, no en suposiciones.
|
Escenario |
Enfoque |
Razonamiento |
|---|---|---|
|
Alta frecuencia de escritura |
Mantenga normalizado |
Las actualizaciones son más rápidas. Menos redundancia que mantener. |
|
Alta frecuencia de lectura |
Considere la desnormalización |
Reduce las uniones. Tiempos de recuperación más rápidos. |
|
La consistencia de los datos es crítica |
Mantenga normalizado |
Una única fuente de verdad evita el desplazamiento de datos. |
|
Informes y análisis |
Desnormalice |
Las agregaciones son complejas; precalcularlas ayuda. |
|
Necesidades de escalabilidad |
Enfoque híbrido |
Divida los servicios o use capas de caché. |
El compromiso: Integridad de los datos frente a velocidad ⚙️
Cada vez que introduce redundancia, corre el riesgo de inconsistencia de datos. Si un usuario cambia su dirección de correo electrónico, pero el correo se almacena en ambos la Usuarios tabla y el Notificaciones tabla, una actualización podría fallar o pasarse por alto. Esto se conoce como una anomalía de actualización.
Para mitigar esto, la lógica de la aplicación debe ser robusta. Los desencadenantes pueden garantizar la consistencia, pero añaden complejidad. Alternativamente, diseña el esquema de modo que los datos desnormalizados sean derivados e inmutables, reduciendo así el riesgo de divergencia.
Gestión de la consistencia
-
Lógica a nivel de aplicación:Escribe código que actualice todas las copias redundantes de forma atómica.
-
Disparadores de base de datos:Permite que la base de datos aplique las reglas automáticamente. Esto mantiene la lógica cerca de los datos.
-
Consistencia eventual:Acepta que los datos podrían estar desactualizados durante un corto período. Usa trabajos en segundo plano para sincronizar los datos redundantes.
Monitoreo y mantenimiento 🔧
Un diseño estático no tiene en cuenta los patrones de uso cambiantes. Lo que funciona hoy podría convertirse en un cuello de botella el próximo año. El monitoreo continuo es esencial.
Métricas clave para monitorear
-
Latencia de consulta:Monitorea el tiempo que tardan las consultas de lectura críticas.
-
Número de uniones:Monitorea el número de uniones por consulta compleja.
-
Ratio de aciertos en caché:Si usas caché, verifica si está reduciendo eficazmente la carga de la base de datos.
-
Latencia de escritura:Asegúrate de que la desnormalización no haya ralentizado demasiado las escrituras.
Conclusión: Una decisión contextual 🎯
No existe una norma universal para el diseño de bases de datos. El mejor diagrama ER es aquel que se adapta a tu carga de trabajo específica. La normalización proporciona seguridad; la desnormalización proporciona velocidad. El objetivo es encontrar el punto de equilibrio.
Comienza con un diseño normalizado para garantizar la integridad de los datos. Cuando surjan cuellos de botella de rendimiento, identifica las consultas específicas que causan retrasos. Aplica la desnormalización o la caché solo en esas áreas. Este enfoque iterativo evita la optimización prematura y garantiza que el sistema permanezca mantenible con el tiempo.
Recuerda que la tecnología evoluciona. Los nuevos motores de almacenamiento y optimizadores de consultas siguen reduciendo el costo de las uniones. Revisa periódicamente tu esquema frente a las capacidades actuales. El equilibrio cambia, y tu diseño debe cambiar con él.
Al comprender la mecánica de la normalización y las realidades del rendimiento de lectura, puedes construir sistemas que sean tanto robustos como responsivos. Enfócate en los datos, no solo en el código.