











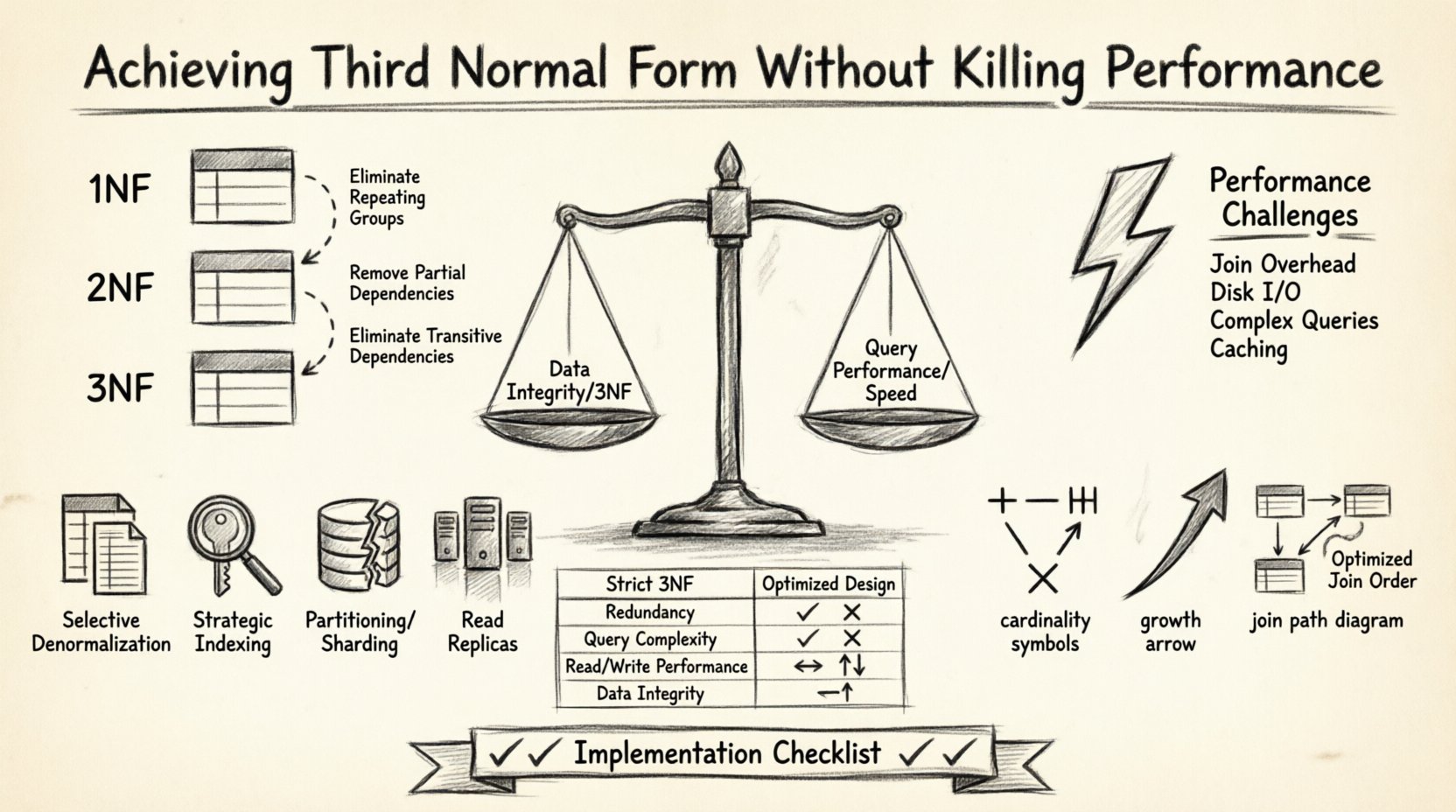
Diseñar una estructura de base de datos robusta es un equilibrio. Por un lado, tienes la integridad de los datos y la eliminación de la redundancia mediante la normalización. Por el otro, tienes la velocidad de las consultas y la reactividad del sistema. Muchos arquitectos de bases de datos enfrentan una elección difícil: adherirse estrictamente a las reglas de normalización y arriesgarse a consultas lentas, o denormalizar de forma agresiva y arriesgarse a inconsistencias de datos. El objetivo es encontrar un punto intermedio donde la base de datos cumpla con la Tercera Forma Normal (3FN) manteniendo un alto rendimiento. Este artículo explora cómo estructurar Diagramas de Relación de Entidades (ERD) para lograr este equilibrio sin comprometer ni la integridad ni la velocidad.
Entendiendo la Tercera Forma Normal 🧩
La Tercera Forma Normal es un nivel específico de normalización de bases de datos. Antes de alcanzar la 3FN, una tabla debe cumplir primero con la Primera Forma Normal (1FN) y la Segunda Forma Normal (2FN). El principio fundamental de la 3FN es que todos los atributos deben depender únicamente de la clave primaria. No debe haber dependencias transitivas.
- Primera Forma Normal:Elimina grupos repetidos y garantiza valores atómicos.
- Segunda Forma Normal:Elimina dependencias parciales donde los atributos no clave dependen solo de parte de una clave compuesta.
- Tercera Forma Normal:Elimina dependencias transitivas. Si A determina B, y B determina C, entonces C no debería depender directamente de A en la misma tabla.
Cuando alcanzas la 3FN, minimizas las anomalías de actualización. Estos son errores que ocurren cuando los datos se modifican en un lugar pero no en otros, lo que genera inconsistencias. Por ejemplo, si la dirección de un cliente se almacena tanto en la tabla Pedidos como en la tabla Clientescomo en la tabla, cambiar la dirección en una tabla pero no en la otra genera una discrepancia. La 3FN te obliga a almacenar esa dirección en un solo lugar.
La compensación de rendimiento ⚡
Aunque la 3FN es excelente para la integridad de los datos, a menudo conlleva un costo para el rendimiento. Las bases de datos normalizadas requieren típicamente más tablas. Para recuperar un conjunto de datos completo, el motor de la base de datos debe realizar múltiples uniones. Cada operación de unión requiere que el sistema lea datos desde el disco o la memoria, coincida claves y combine resultados.
Considera una consulta de informes que necesita nombres de clientes, detalles de pedidos, descripciones de productos y direcciones de envío. En un diseño 3FN completamente normalizado, esto podría implicar unir cinco o más tablas. Si el volumen de datos es grande, estas uniones pueden convertirse en un cuello de botella.
Estos son los desafíos específicos de rendimiento asociados con la 3FN:
- Sobrecarga aumentada de uniones:Cada relación requiere una operación de unión durante las consultas de lectura.
- Entrada/Salida de disco:Distribuir los datos a través de muchas tablas aumenta el número de páginas que el motor de la base de datos debe acceder.
- Lógica de consulta compleja:Las aplicaciones deben construir declaraciones SQL más complejas para recuperar datos relacionados.
- Complejidad de caché:Cachear una sola fila denormalizada es más sencillo que cachear múltiples filas relacionadas.
Estrategias para equilibrar integridad y velocidad 🚀
No necesitas abandonar la normalización para mejorar el rendimiento. Existen técnicas específicas para optimizar una base de datos 3FN manteniendo la estructura intacta. Las siguientes estrategias ayudan a mantener la calidad de los datos sin sacrificar la velocidad.
1. Denormalización selectiva
No todas las tablas necesitan ser estrictamente 3FN. Identifique las tablas con alta carga de lectura y las rutas de datos críticas. Puede introducir redundancia controlada en estas áreas específicas. Por ejemplo, almacene el nombre de un cliente directamente en la Pedidos tabla. Aunque esto duplica datos, la ganancia de rendimiento para las búsquedas de pedidos es significativa. Debe implementar entonces un desencadenador o lógica de aplicación para mantener actualizada esta copia cuando cambie el registro del cliente.
2. Indexación estratégica
Los índices son la herramienta principal para acelerar las uniones. Sin índices, una base de datos realiza una escaneo completo de la tabla para cada condición de unión. Con un índice adecuado, las búsquedas se vuelven casi instantáneas.
- Índices de claves foráneas: Siempre indexe las columnas utilizadas en relaciones de clave foránea. Esto garantiza que unir tablas sea rápido.
- Índices compuestos: Cree índices en múltiples columnas si sus consultas filtran frecuentemente por esa combinación.
- Índices cubrientes: Diseñe índices que incluyan todas las columnas necesarias para una consulta específica. Esto permite que la base de datos satisfaga la consulta utilizando solo el índice, evitando una búsqueda en los datos principales de la tabla.
3. Particionado y fragmentación
Si el conjunto de datos crece demasiado, dividir las tablas puede mejorar el rendimiento. El particionado divide una tabla grande en piezas físicas más pequeñas y manejables basadas en una clave, como la fecha o la región. La fragmentación distribuye los datos entre varias instancias de base de datos. Ambos métodos reducen la cantidad de datos que el motor necesita escanear para responder a una consulta específica.
4. Réplicas de lectura
Separe sus operaciones de escritura de las operaciones de lectura. Utilice una instancia principal de base de datos para transacciones y actualizaciones. Repita esos datos en una o más réplicas de solo lectura. Las consultas complejas de informes que sobrecargan el sistema pueden ejecutarse en las réplicas, manteniendo el sistema principal rápido para las interacciones del usuario.
Consideraciones de diseño de ERD 📐
Al dibujar un diagrama de relaciones de entidades, la representación visual influye en cómo los desarrolladores escriben consultas. Un ERD claro ayuda a identificar relaciones desde temprano. Sin embargo, un diagrama que parece perfecto en papel podría funcionar mal en producción. Aquí tiene cómo abordar el diseño de ERD para el rendimiento.
- Identifique claramente la cardinalidad: Asegúrese de que cada relación tenga una cardinalidad definida (uno a uno, uno a muchos, muchos a muchos). Las relaciones ambiguas conducen a uniones ineficientes.
- Planifique para el crecimiento: Anticipe el volumen futuro de datos. Un diseño que funciona para 10,000 filas podría fallar con 10 millones de filas.
- Revise las rutas de unión: Trace las rutas que una consulta común tomará a través del diagrama. Si una ruta es demasiado larga, considere agregar una columna desnormalizada.
- Documente las restricciones: Documente explícitamente cuáles restricciones son impuestas por la base de datos y cuáles son manejadas por la capa de aplicación.
Comparación: Diseño normalizado frente a diseño optimizado 📊
La tabla a continuación ilustra las diferencias entre un enfoque estricto de 3FN y un enfoque optimizado para un escenario específico.
| Característica | Diseño estricto de 3FN | Diseño optimizado |
|---|---|---|
| Redundancia | Mínima | Controlada y limitada |
| Complejidad de la consulta | Alta (múltiples uniones) | Moderada (menos uniones) |
| Rendimiento de escritura | Rápido (menos datos) | Variable (disparadores de actualización) |
| Rendimiento de lectura | Más lento (E/S de disco) | Más rápido (datos en caché) |
| Integridad de los datos | Alta | Alta (con validación) |
Cuándo romper las reglas 🛑
Existen escenarios válidos en los que se debe dejar de lado estrictamente la 3FN. Comprender cuándo desviarse es crucial para los arquitectos de bases de datos.
- Informes y análisis:Los almacenes de datos a menudo utilizan un esquema estrella en lugar de la 3FN. El objetivo aquí es la velocidad de lectura para análisis, no la integridad transaccional.
- Sistemas transaccionales de alto rendimiento: Si el sistema maneja millones de escrituras por segundo, las uniones complejas podrían causar contención de bloqueos. Simplificar el esquema puede reducir la sobrecarga de bloqueos.
- Sistemas heredados: Si se está migrando desde un sistema antiguo, podría ser más rápido desnormalizar temporalmente mientras se reconstruye la capa de aplicación.
- Aplicaciones con carga pesada de lectura: Si su aplicación lee datos 100 veces por cada escritura, el costo de mantener la consistencia de la 3FN supera los beneficios.
Lista de verificación de implementación ✅
Antes de implementar su esquema de base de datos, revise esta lista de verificación para asegurarse de que ha equilibrado el rendimiento y la normalización.
- Analice los patrones de consulta: Identifique las consultas de lectura más frecuentes. ¿Requieren demasiadas uniones?
- Mida el rendimiento actual: Establece una línea base para tu sistema. Conoce la latencia actual de las consultas críticas.
- Revisa el uso de índices: Verifica si los índices están siendo utilizados o si están causando sobrecarga durante las escrituras.
- Prueba la carga de escritura: Asegúrate de que cualquier estrategia de denormalización no ralentice demasiado las operaciones de escritura.
- Planifica la sincronización de datos: Si duplicas datos, ¿cómo los mantendrás sincronizados? Define el mecanismo.
- Monitorea anomalías: Configura alertas para inconsistencias de datos si estás utilizando una denormalización parcial.
Consideraciones finales sobre la arquitectura de bases de datos 🏗️
Lograr la Tercera Forma Normal sin matar el rendimiento requiere un enfoque matizado. No se trata de una elección binaria entre velocidad e integridad. Al comprender el costo de las uniones, utilizar eficazmente los índices y aplicar la denormalización selectiva cuando sea apropiado, puedes construir sistemas que sean tanto confiables como rápidos. El mejor diseño de base de datos es aquel que se alinea con la carga de trabajo específica de la aplicación. Revisa periódicamente tu diagrama ERD y el rendimiento de las consultas a medida que crece el sistema. La adaptación es clave para el éxito a largo plazo en la gestión de datos.