











Die Datenbankarchitektur ist selten statisch. Wenn Anwendungen wachsen und Anforderungen sich ändern, müssen die zugrundeliegenden Datenstrukturen sich anpassen. Dieser Prozess wird als Schema-Evolution bezeichnet. Die Einführung von Änderungen in einer Produktionsdatenbank birgt jedoch erhebliche Risiken. Ein einzelner falscher Constraint oder eine gelöschte Spalte kann die Funktionalität der Anwendung stoppen oder kritische Daten beschädigen. Um diese Risiken zu minimieren, verlassen sich Ingenieure auf eine robuste Validierungsstrategie, die auf Entity-Relationship-Modellen (ERMs) basiert. 🛡️
Die Validierung der Schema-Evolution vor der Bereitstellung stellt sicher, dass logische Änderungen mit physischen Beschränkungen übereinstimmen. Sie schließt die Lücke zwischen dem Gestaltungsintention und der Laufzeitrealität. Indem ER-Modelle als Quelle der Wahrheit genutzt werden, können Teams Änderungen simulieren, Abhängigkeiten prüfen und Kompatibilität überprüfen, ohne Live-Daten zu berühren. Dieser Ansatz reduziert Ausfallzeiten und verhindert die oft mit manuellen Migrations-Skripten verbundene Chaos.
Warum die Schema-Evolution wichtig ist 📉
In modernen Entwicklungszyklen ist Daten die Grundlage jedes Features. Wenn sich eine Geschäftsanforderung ändert, muss die Datenbank diese Veränderung oft widerspiegeln. Das könnte das Hinzufügen eines neuen Feldes, das Aufteilen einer Tabelle oder die Änderung eines Datentyps bedeuten. Ohne einen strukturierten Validierungsprozess werden diese Änderungen zu einem Wagnis.
Häufige Herausforderungen während der Evolution sind:
- Breaking Changes:Das Entfernen einer Spalte, auf die Anwendungen angewiesen sind, führt sofort zu Fehlern.
- Leistungsverschlechterung:Das Hinzufügen von Indizes oder das Ändern der Speicher-Engines kann Abfragen unerwartet verlangsamen.
- Verlust der Datenintegrität:Schlecht definierte Constraints können es ungültigen Daten erlauben, in das System einzutreten.
- Ausfallzeiten:Das Sperren von Tabellen während der Migration kann die Anwendung für Benutzer unerreichbar machen.
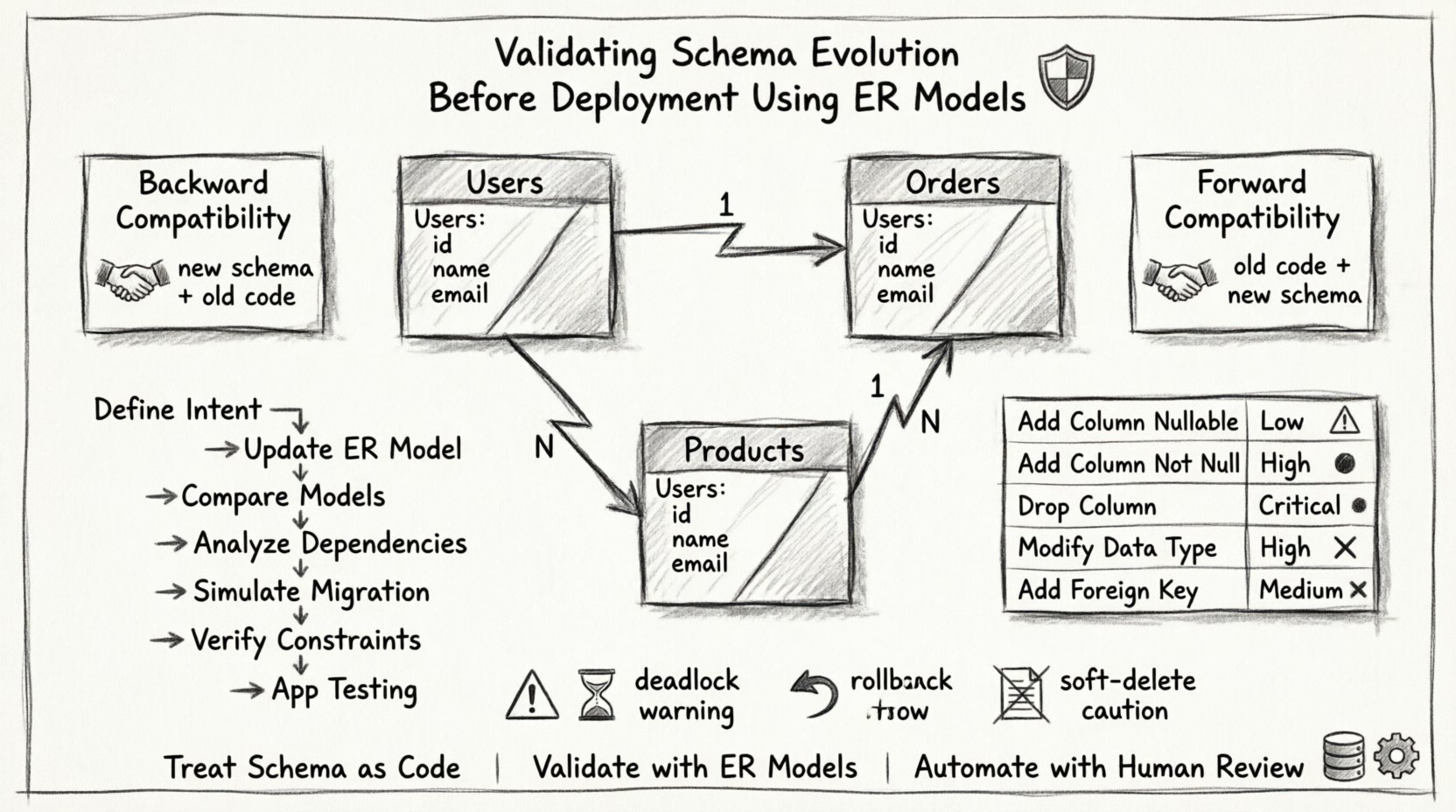
Durch die Verwendung eines ER-Modells können Architekten diese Risiken vorhersehen. Das Modell dient als Bauplan und zeigt Beziehungen, Kardinalitäten und Constraints klar und übersichtlich. 📐
Die Rolle von ER-Modellen bei der Validierung 🧩
Ein Entity-Relationship-Modell stellt die logische Struktur einer Datenbank dar. Es definiert Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel). Bei der Validierung der Evolution fungiert das ER-Modell als Baseline für den Vergleich.
Hier ist, wie das Modell bei der Validierung hilft:
- Abhängigkeitszuordnung:Es zeigt, welche Tabellen von anderen abhängen. Wenn eine übergeordnete Tabelle geändert wird, muss die untergeordnete Tabelle überprüft werden.
- Constraint-Überprüfung:Primärschlüssel und eindeutige Constraints sind auf einen Blick sichtbar, was sicherstellt, dass sie während Aktualisierungen nicht verletzt werden.
- Normalisierungsprüfungen:Es hilft dabei, sicherzustellen, dass neue Strukturen weiterhin den Normalisierungsregeln entsprechen und so Redundanz verhindert wird.
- Historischer Kontext:Der Vergleich des aktuellen ER-Diagramms mit dem vorgeschlagenen zeigt genau, was sich verändert hat.
Indem das ER-Diagramm als versioniertes Artefakt behandelt wird, können Teams die Evolution im Laufe der Zeit verfolgen. Dadurch entsteht eine Nachverfolgung, warum bestimmte Schema-Entscheidungen getroffen wurden.
Identifizierung von Änderungstypen 🔍
Nicht alle Schema-Änderungen sind gleich. Einige sind sicher, während andere komplexe Migrationsstrategien erfordern. Die Kategorisierung von Änderungen hilft dabei, die erforderliche Validierungstiefe zu bestimmen.
| Änderungstyp | Risikostufe | Validierungs-Fokus |
|---|---|---|
| Spalte hinzufügen (nullable) | Niedrig | Überprüfen Sie Standardwerte und Speichergröße. |
| Spalte hinzufügen (nicht null) | Hoch | Stellen Sie sicher, dass bestehende Daten die Einschränkung erfüllen, oder geben Sie einen Standardwert an. |
| Spalte löschen | Kritisch | Stellen Sie sicher, dass kein Anwendungscode auf die Spalte verweist. |
| Datentyp ändern | Hoch | Überprüfen Sie auf Datenbeschneidung oder Genauigkeitsverlust. |
| Fremdschlüssel hinzufügen | Mittel | Stellen Sie sicher, dass die Referenzintegrität bei allen vorhandenen Zeilen erhalten bleibt. |
Das Verständnis dieser Kategorien ermöglicht es Ingenieuren, ihre Testanstrengungen zu priorisieren. Kritische Änderungen erfordern eine manuelle Überprüfung, während Änderungen mit geringem Risiko automatisiert werden könnten.
Kompatibilitätsstrategien 🔄
Beim Bereitstellen von Schemaänderungen ist die Aufrechterhaltung der Kompatibilität mit der Anwendung entscheidend. Es gibt zwei Hauptstrategien, die berücksichtigt werden müssen: Rückwärtskompatibilität und Vorwärtskompatibilität.
Rückwärtskompatibilität
Dies stellt sicher, dass das neue Schema mit dem alten Anwendungscode funktioniert. Es ist entscheidend, wenn Datenbankänderungen vor Anwendungsaktualisierungen bereitgestellt werden. Zum Beispiel sollte der alte Code nicht abstürzen, wenn er die neue Spalte ignoriert. Wenn Sie eine Spalte löschen, muss der alte Code weiterhin funktionieren oder gleichzeitig aktualisiert werden.
Vorwärtskompatibilität
Dies stellt sicher, dass die alte Anwendung das neue Schema weiterhin lesen kann. Dies ist nützlich, wenn die Datenbank vor der Anwendung aktualisiert wird. Zum Beispiel ermöglicht das Hinzufügen einer Spalte, dass alte Abfragen ohne Fehler ausgeführt werden, auch wenn sie die neuen Daten nicht nutzen.
Ein robustes Validierungsverfahren prüft beide Richtungen. Das ER-Modell hilft dabei, visuell zu erkennen, ob eine Änderung den Vertrag zwischen Anwendung und Datenbank verletzt. 🤝
Der Validierungsprozess Schritt für Schritt 🚀
Die Durchführung einer Schemaänderung erfordert einen disziplinierten Arbeitsablauf. Sich auf Gedächtnis oder schnelle Skripte zu verlassen, ist gefährlich. Folgen Sie diesem strukturierten Ansatz, um die Evolution sicher zu validieren.
- Definieren Sie das Ziel:Dokumentieren Sie klar, was geändert werden muss und warum. Dies verhindert eine Ausweitung des Umfangs.
- Aktualisieren Sie das ER-Modell: Erstellen Sie den vorgeschlagenen Zustand des Diagramms. Wenden Sie die Änderungen an der physischen Datenbank noch nicht an.
- Modelle vergleichen: Generieren Sie einen Unterschied zwischen dem aktuellen und dem vorgeschlagenen ER-Diagramm. Identifizieren Sie hinzugefügte, entfernte oder geänderte Entitäten.
- Abhängigkeiten analysieren: Verfolgen Sie Fremdschlüssel und Indizes. Stellen Sie sicher, dass durch die Änderung keine verwaisten Beziehungen entstehen.
- Migration simulieren: Führen Sie das Migrations-Skript in einer Staging-Umgebung aus, die das Datenvolumen der Produktion nachahmt.
- Einschränkungen überprüfen: Stellen Sie sicher, dass Trigger, Prüfungen und Einschränkungen korrekt angewendet werden.
- Anwendungstest: Führen Sie die Anwendung gegen das neue Schema aus, um sicherzustellen, dass die Abfragen die erwarteten Ergebnisse liefern.
Automatisierungstools können bei Schritten 3, 5 und 6 unterstützen, aber die menschliche Überprüfung bleibt für komplexe Logik unverzichtbar.
Datenintegrität und Einschränkungen 🛑
Der wichtigste Aspekt der Schema-Evolution ist die Datenintegrität. Eine Änderung, die auf Papier korrekt erscheint, kann fehlschlagen, wenn sie auf Millionen von Zeilen angewendet wird. ER-Modelle helfen dabei, Einschränkungen zu visualisieren, aber die Validierung erfordert die Prüfung anhand echter Daten.
Wichtige Bereiche, die gründlich geprüft werden müssen, sind:
- Primärschlüssel: Stellen Sie sicher, dass die Eindeutigkeit nicht beeinträchtigt wird.
- Fremdschlüssel: Prüfen Sie auf zirkuläre Abhängigkeiten, die zu Verklemmungen führen könnten.
- Prüfeinschränkungen: Stellen Sie sicher, dass Geschäftsvorgaben (z. B. Alter muss positiv sein) für die vorhandenen Daten gültig sind.
- Indizes: Bestätigen Sie, dass neue Indizes nicht mit bestehenden konflikten haben oder eine übermäßige Schreiblatenz verursachen.
Zum Beispiel: Ändern einer Spalte von INT auf VARCHAR mag sicher erscheinen, aber wenn die Anwendung numerische Operationen erwartet, treten Fehler auf. Das ER-Modell sollte den logischen Typ widerspiegeln, aber die physische Implementierung muss übereinstimmen.
Häufige Fehler, die vermieden werden sollten ⚠️
Sogar erfahrene Teams begehen Fehler. Die Kenntnis häufiger Fehler hilft dabei, einen widerstandsfähigeren Validierungsprozess zu gestalten.
- Ignorieren von Sperrungen:Langlaufende Migrationen können Tabellen sperren und zu Anwendungszeitüberschreitungen führen. Überprüfen Sie die Sperrdauer.
- Voraussetzung von null Ausfallzeit:Einige Änderungen erfordern inhärent eine Ausfallzeit. Planen Sie dies explizit, anstatt darauf zu hoffen, dass alles gut geht.
- Überspringen von Rückgängigmachungsplänen:Wenn die Validierung erfolgreich ist, aber die Produktion fehlschlägt, ist ein Rückgängigmachungsskript obligatorisch. Testen Sie die Rückgängigmachung genauso gründlich wie die Migration.
- Übersehen von Weichlöschungen:Die Änderung der Logik für weichgelöschte Datensätze kann zu Datenverlust führen, wenn sie nicht sorgfältig behandelt wird.
Automatisierung des Workflows ⚙️
Während die manuelle Validierung gründlich ist, skaliert sie nicht. Automatisierungstools können ER-Modelle parsen und Migrationsskripte generieren. Sie können außerdem Lint-Checks ausführen, um häufige Fehler vor der Bereitstellung zu erkennen.
Vorteile der Automatisierung umfassen:
- Konsistenz:Jede Änderung folgt denselben Regeln.
- Geschwindigkeit:Skripte laufen schneller als manuelle Überprüfungen.
- Dokumentation:Generierte Berichte dienen als Nachweis der Validierung für Compliance-Audits.
- Integration:Automatisierte Prüfungen können Teil der CI/CD-Pipeline sein und die Bereitstellung blockieren, wenn die Validierung fehlschlägt.
Allerdings sollte die Automatisierung das menschliche Urteil nicht ersetzen. Komplexe Geschäftslogik erfordert oft eine Überprüfung durch einen erfahrenen Ingenieur, der den Kontext der Daten versteht.
Abschließende Gedanken zur Schema-Verwaltung 🌱
Die Schema-Evolution ist ein kontinuierlicher Prozess, der Aufmerksamkeit erfordert. Die Behandlung des Datenbankschemas als Code ist der erste Schritt hin zu Zuverlässigkeit. Durch die Verwendung von ER-Modellen zur Validierung von Änderungen können Teams eine hohe Verfügbarkeit und Datenkorrektheit aufrechterhalten.
Das Ziel ist nicht nur, Änderungen vorzunehmen, sondern sie sicher vorzunehmen. Ein gut validiertes Schema stellt sicher, dass die Anwendung stabil bleibt, selbst wenn sich die Anforderungen ändern. Diese Disziplin stärkt das Vertrauen zwischen dem Entwicklerteam und der Infrastruktur. 🏗️
Investieren Sie Zeit in die Entwurfsphase. Erstellen Sie klare Diagramme. Dokumentieren Sie jede Einschränkung. Testen Sie jede Migration. Diese Praktiken bilden die Grundlage eines gesunden Datenökosystems. Wenn die Datenbank stabil ist, kann die Anwendung gedeihen.
Denken Sie daran, dass die Schema-Validierung kein einmaliger Vorgang ist. Es ist eine Kultur. Je größer das System wird, desto mehr muss der Validierungsprozess mitwachsen. Regelmäßige Überprüfungen des ER-Modells stellen sicher, dass die Architektur mit den Geschäftszielen Schritt hält. Dieser proaktive Ansatz verhindert, dass sich technischer Schulden im Laufe der Zeit ansammeln.