









In der Architektur robuster Datensysteme dient das Entitäts-Beziehungs-Diagramm (ERD) als grundlegende Bauplan. Wenn Systeme an Komplexität gewinnen und die Datenmenge zunimmt, wird die Aufrechterhaltung einer sauberen Schemastruktur entscheidend. Redundanz in einem großskaligen ERD ist nicht nur eine Verschwendung von Speicherplatz, sondern auch eine Quelle systemischer Instabilität. Wenn identische Datenpunkte an mehreren Stellen ohne Mechanismus zur Synchronisierung gespeichert werden, steigt die Gefahr von Dateninkonsistenzen stark an.
Dieser Leitfaden untersucht die technischen Strategien, die erforderlich sind, um Redundanz zu minimieren, ohne die Flexibilität zu opfern, die für Anwendungen mit hoher Datenmenge notwendig ist. Wir werden Normalisierungsprinzipien, strukturelle Muster und Überprüfungsverfahren untersuchen, um sicherzustellen, dass Ihr Datenmodell über die Zeit stabil bleibt.
📉 Die Kosten der Duplizierung in Datenmodellen
Redundanz tritt auf, wenn derselbe Datenbestand innerhalb der Datenbankstruktur mehrfach gespeichert wird. Während eine gewisse Denormalisierung zur Leistungssteigerung akzeptabel ist, führt ungezügelte Duplizierung zu mehreren Risiken, die sich in großskaligen Umgebungen verstärken.
-
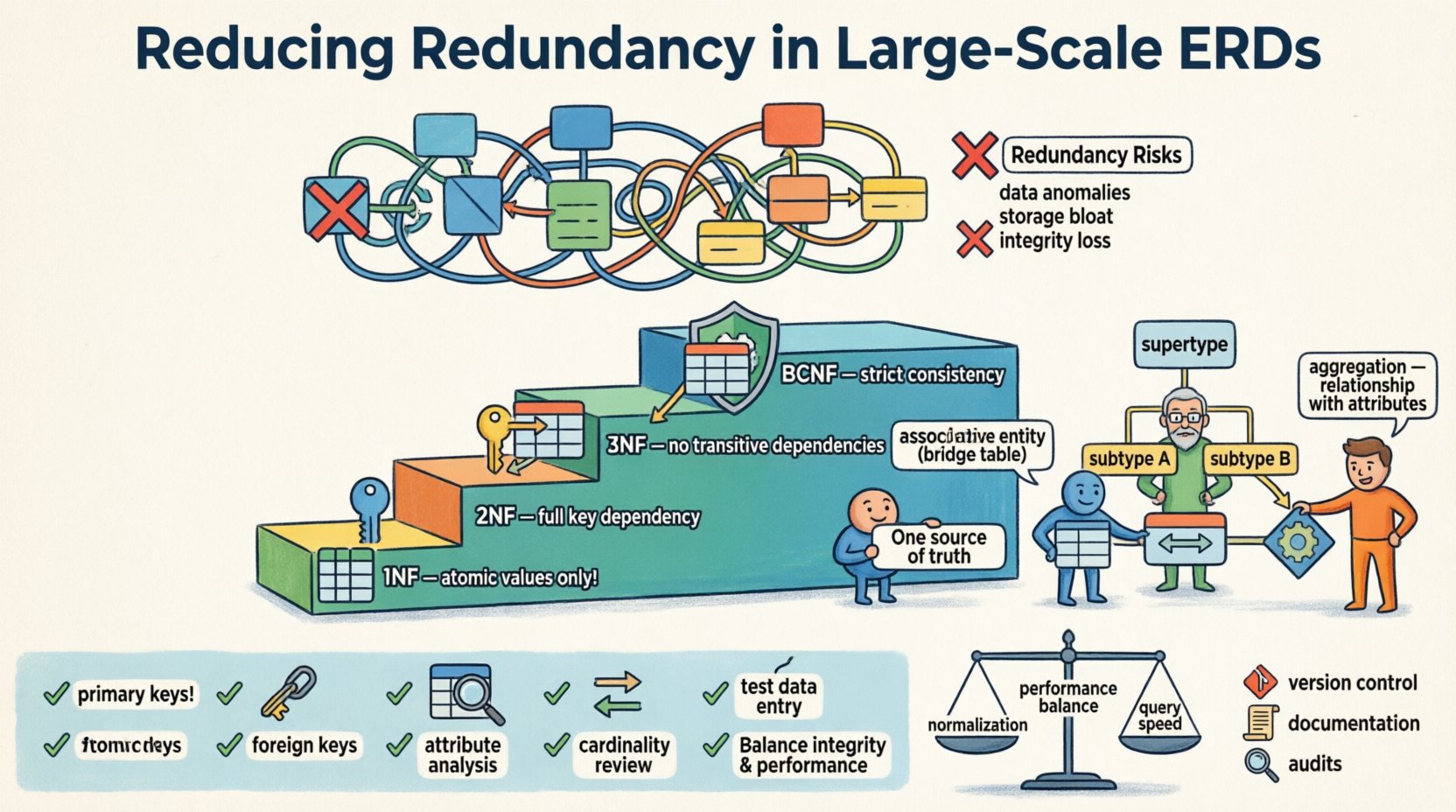
Datenanomalien:Die Aktualisierung von Informationen an einer Stelle, aber nicht an einer anderen, führt zu widersprüchlichen Datensätzen. Dies wird als Aktualisierungsanomalie bezeichnet.
-
Einfügeprobleme:Manchmal können Sie neue Daten nicht hinzufügen, weil verwandte Informationen an anderer Stelle fehlen. Dies wird als Einfügeanomalie bezeichnet.
-
Löschrisiken:Das Löschen eines Datensatzes könnte versehentlich eindeutige Informationen löschen, die redundant innerhalb dieser Zeile gespeichert waren. Dies wird als Löschanomalie bezeichnet.
-
Speicherplatzschwellung:Das wiederholte Speichern derselben Werte verbraucht unnötigerweise Festplattenspeicher und Arbeitsspeicher.
-
Integritätsverlust:Ohne Einschränkungen, die die Eindeutigkeit über redundanten Feldern erzwingen, wird die einzige Quelle der Wahrheit fragmentiert.
In großskaligen Diagrammen verstärken sich diese Probleme. Eine einzelne Tabelle mit duplizierten Fremdschlüsseln oder beschreibenden Attributen kann während Wartungsoperationen kaskadenartige Ausfälle verursachen. Das Ziel ist es, ein Gleichgewicht zu finden, bei dem die Datenintegrität gewahrt bleibt, ohne die Abfrageeffizienz zu opfern.
🔄 Verständnis der Normalisierungsprinzipien
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Abhängigkeitsverwaltung zu verbessern. Dabei werden Tabellen in kleinere, gut strukturierte Entitäten zerlegt. Obwohl die Theorie auf die 1970er Jahre zurückgeht, bleiben die Prinzipien die Grundlage der modernen Schema-Designs.
Erste Normalform (1NF)
Der erste Schritt besteht darin, die Attribut-Atomizität sicherzustellen. Jede Spalte muss unteilbare Werte enthalten. Listen innerhalb einer einzelnen Zelle verletzen dieses Prinzip. Zum Beispiel erfordert die Speicherung mehrerer Telefonnummern in einer einzigen Spalte, dass diese in separate Zeilen oder zugehörige Tabellen aufgeteilt werden.
Zweite Normalform (2NF)
Sobald 1NF erfüllt ist, behandeln wir partielle Abhängigkeiten. Eine Tabelle befindet sich in 2NF, wenn sie in 1NF ist und alle nichtschlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen. Bei zusammengesetzten Schlüsseln sollten Attribute nicht nur von einem Teil des Schlüssels abhängen.
Dritte Normalform (3NF)
Dies ist der häufigste Standard für allgemeine Transaktionssysteme. Eine Tabelle befindet sich in 3NF, wenn sie in 2NF ist und keine transitiven Abhängigkeiten aufweist. Vereinfacht ausgedrückt sollten nichtschlüsselbasierte Attribute nicht von anderen nichtschlüsselbasierten Attributen abhängen. Wenn A bestimmt B und B bestimmt C, dann A bestimmt C, was redundant ist, es sei denn, B ist ein Schlüssel.
Boyce-Codd-Normalform (BCNF)
BCNF ist eine strengere Version von 3NF. Sie behandelt Fälle, in denen mehrere Kandidatenschlüssel und überlappende Abhängigkeiten vorliegen. Obwohl sie nicht immer notwendig ist, gewährleistet sie das höchste Maß an logischer Konsistenz.
|
Form |
Schwerpunkt |
Wichtige Anforderung |
Auswirkung auf Redundanz |
|---|---|---|---|
|
1NF |
Atomarität |
Keine wiederholenden Gruppen |
Grundstruktur |
|
2NF |
Partielle Abhängigkeiten |
Vollständige Abhängigkeit vom Primärschlüssel |
Verringert Redundanz bei geteilten Schlüsseln |
|
3NF |
Transitive Abhängigkeiten |
Nicht-Schlüssel-Attribute hängen nur vom Schlüssel ab |
Beseitigt die Duplikation von Attributen |
|
BCNF |
Strenge Abhängigkeiten |
Jeder Determinant ist ein Kandidatenschlüssel |
Minimiert komplexe Überlappungen |
🏛️ Fortgeschrittene strukturelle Muster für Skalierung
Die Standardnormalisierung funktioniert gut für transaktionale Datenbanken, aber große Systeme erfordern oft spezifische Muster, um die Komplexität zu verwalten, ohne übermäßige Joins zu erzeugen.
Assoziative Entitäten
Vielen-zu-viele-Beziehungen sind eine primäre Quelle für Redundanz, wenn sie schlecht behandelt werden. Statt Fremdschlüssel in beide betroffene Tabellen einzufügen, erstellen Sie eine assoziative Tabelle. Diese Tabelle enthält nur die Fremdschlüssel und alle Attribute, die spezifisch für die Beziehung selbst sind.
-
Vorteil:Änderungen an den Beziehungseigenschaften erfordern keine Änderung der übergeordneten Entitäten.
-
Nutzen: Verhindert die Doppelung von Beziehungs-Metadaten über mehrere Zeilen hinweg.
Untertypen und OberTypen
Wenn Entitäten gemeinsame Attribute teilen, aber spezifische Variationen aufweisen, reduziert das Verwenden eines OberTyp/Untertyp-Musters die Duplikation von Attributen. Anstatt optionale Spalten in einer Haupttabelle hinzuzufügen, die nur für bestimmte Instanzen gelten, erstellen Sie separate Tabellen für die Untertypen, die über einen gemeinsamen Primärschlüssel verknüpft sind.
-
Nutzen: Hält die Hauptentitätstabelle sauber.
-
Nutzen: Erlaubt spezifische Einschränkungen für Untertypen, ohne den Eltern-Typ zu beeinflussen.
Aggregation
Aggregation wird verwendet, wenn eine Beziehung Attribute besitzt, die der Beziehung selbst zugehören und nicht den beteiligten Entitäten. In einer großskaligen ERD erscheint dies oft als Zusammenfassung oder transaktionale Verbindung zwischen zwei Hauptdomänen.
🧩 Komplexitätsmanagement in großen Modellen
Wenn die Anzahl der Entitäten wächst, wird das Diagramm selbst dann eine Belastung, wenn es nicht korrekt verwaltet wird. Großskalige ERDs erfordern Modularisierungsstrategien.
Logische vs. physische Modelle
Trennen Sie die logische Gestaltung von der physischen Implementierung. Das logische Modell konzentriert sich auf Entitäten und Beziehungen, ohne Rücksicht auf spezifische Speichermechanismen. Das physische Modell behandelt Indizierung, Partitionierung und Datentypen. Die Trennung verhindert, dass physische Einschränkungen logische Redundanz erzwingen.
Modulare Gestaltung
Teilen Sie das System in funktionale Domänen auf. Zum Beispiel trennen Sie die Benutzer-Domäne von der Abrechnungs-Domäne. Jede Domäne bewahrt ihre eigene interne Konsistenz. Interaktionen zwischen Domänen erfolgen über definierte Schnittstellen oder Schlüssel, anstatt über gemeinsame Tabellen.
Umgang mit historischen Daten
Das Speichern historischer Versionen von Daten kann Redundanz erzeugen. Anstatt ganze Zeilen zu duplizieren, verwenden Sie Versionsspalten oder getrennte Audit-Tabellen. Dadurch bleibt der aktuelle Zustand erhalten, ohne die Hauptentität mit früheren Versionen zu verunreinigen.
🛠️ Häufige Fehler bei der Schema-Gestaltung
Die Vermeidung von Redundanz erfordert Aufmerksamkeit. Häufige Fehler sind:
-
Über-Normalisierung: Aufteilung von Tabellen so fein, dass Abfragen übermäßige Joins erfordern, was die Leistung beeinträchtigt. Manchmal ist ein kontrollierter Grad an Redundanz bei Lese-lastigen Workloads gerechtfertigt.
-
Ignorieren funktionaler Abhängigkeiten: Das Nichterkennen, welche Attribute von welchen Schlüsseln abhängen, führt zu versteckter Duplikation.
-
Verwirren von Anliegen: Plazieren von Geschäftslogik-Attributen im Datenmodell. Attribute sollten die Daten beschreiben, nicht den Prozess.
-
Hartkodierte Werte: Speichern spezifischer Status-Codes oder Kategorien als Zeichenketten anstelle der Referenzierung einer Abfrage-Tabelle.
✅ Überprüfungs- und Validierungs-Checkliste
Bevor Sie eine großskalige ERD abschließen, führen Sie eine gründliche Überprüfung durch. Verwenden Sie diese Checkliste, um Ihre Gestaltung zu validieren.
-
Primärschlüssel identifizieren: Stellen Sie sicher, dass jede Tabelle einen eindeutigen Bezeichner hat.
-
Fremdschlüssel überprüfen:Stellen Sie sicher, dass alle Beziehungen über Schlüssel, nicht durch Wiederholung von Daten, durchgesetzt werden.
-
Attribute analysieren:Fragen Sie sich, ob jedes nicht-schlüsselbezogene Attribut vom Schlüssel, dem ganzen Schlüssel und nichts anderem abhängt.
-
Kardinalität überprüfen:Stellen Sie sicher, dass ein-zu-viele-Beziehungen durch einen einzigen Fremdschlüssel, nicht durch mehrere, dargestellt werden.
-
Daten-Eingabe testen:Simulieren Sie das Einfügen, Aktualisieren und Löschen von Datensätzen, um Anomalien zu überprüfen.
🔍 Die Rolle von Einschränkungen
Einschränkungen sind die technische Durchsetzung des Entwurfs. Eindeutige Einschränkungen verhindern doppelte Werte in bestimmten Spalten. Fremdschlüssel-Einschränkungen gewährleisten die Referenzintegrität und verhindern verwaiste Datensätze. In großen Systemen sollten Einschränkungsdefinitionen Teil der Schema-Definition sein, nicht eine Nachüberlegung.
Berücksichtigen Sie zusätzlich Prüfeinschränkungen, um den Wertebereich einzuschränken. Dadurch wird verhindert, dass ungültige Daten in das System gelangen, was die Notwendigkeit für Fehlerbehandlungscode später reduziert.
📈 Leistungsaspekte
Es besteht ein Kompromiss zwischen Normalisierung und Leistung. Hochgradig normalisierte Schemata erfordern Joins, um Daten wiederherzustellen. In lesedominanten Umgebungen kann dies die Antwortzeiten verlangsamen. Allerdings kann die Hinzufügung von Redundanz, um Lesevorgänge zu beschleunigen, die Schreibgeschwindigkeit verlangsamen, da mehrere Stellen aktualisiert werden müssen.
Moderne Datenbank-Engines verarbeiten Joins effizient. Daher sollte der Standardansatz die Normalisierung bevorzugen, es sei denn, die Profilierung von Daten zeigt einen spezifischen Engpass auf. Wenn die Leistung entscheidend ist, sollten materialisierte Ansichten oder Lese-Replicas in Betracht gezogen werden, anstatt die grundlegende Schema-Struktur zu verändern.
🔄 Pflege des Schemas im Laufe der Zeit
Datenbankschemata entwickeln sich weiter. Anforderungen ändern sich, und neue Entitäten entstehen. Um im Laufe der Zeit eine geringe Redundanz zu gewährleisten:
-
Versionskontrolle:Behandeln Sie Schema-Definitionen wie Code. Verfolgen Sie Änderungen in einem Repository.
-
Dokumentation:Pflegen Sie aktuelle Dokumentation, die Beziehungen und Abhängigkeiten beschreibt.
-
Regelmäßige Prüfungen:Planen Sie regelmäßige Überprüfungen des ERD, um neue Muster der Redundanz zu identifizieren.
Durch Einhaltung dieser Prinzipien stellen Sie sicher, dass die Datenarchitektur skalierbar bleibt. Ein sauberes ERD ist nicht nur eine Frage der Ästhetik; es geht darum, ein System zu schaffen, das einfacher zu verstehen, zu pflegen und zu erweitern ist, je mehr das Unternehmen wächst.
🎯 Letzte Überlegungen zur Datenintegrität
Die Reduzierung von Redundanz ist ein kontinuierlicher Prozess. Er erfordert ein tiefes Verständnis dafür, wie Daten durch das System fließen und wie Beziehungen miteinander interagieren. Durch die Anwendung von Normalisierungsregeln, die Nutzung fortgeschrittener Strukturmustern und die Einhaltung strenger Validierungsprotokolle bauen Sie eine Grundlage für langfristige Stabilität. Die Investition in ein sauberes Design zahlt sich in Form reduzierter Wartungskosten und höherer Datenqualität aus.
Konzentrieren Sie sich zunächst auf die logischen Beziehungen. Lassen Sie die physische Implementierung eine Spiegelung dieser Logik sein, nicht ein Kompromiss. Mit einer disziplinierten Herangehensweise an die ERD-Entwicklung wird Redundanz zu einer beherrschbaren Variable, statt zu einem anhaltenden Hindernis.