










Die Gestaltung robuster Datenbank-Schemata erfordert ein tiefes Verständnis dafür, wie Datenentitäten miteinander interagieren. Zu den komplexesten Strukturen, die verwaltet werden müssen, gehören Many-to-Many-Beziehungen. Diese Szenarien treten auf, wenn eine einzelne Instanz einer Entität mit mehreren Instanzen einer anderen Entität verknüpft ist und umgekehrt. Ohne eine sorgfältige Planung können diese Verbindungen zu Datenredundanz, Integritätsproblemen und erheblichen Leistungsbremsschwellen führen. Dieser Leitfaden untersucht die Mechanismen zur Optimierung dieser Beziehungen innerhalb von Entitäts-Beziehungs-Modellen (ERMs), um skalierbare und wartbare Systeme zu gewährleisten.
Verständnis der zentralen Herausforderung 🔍
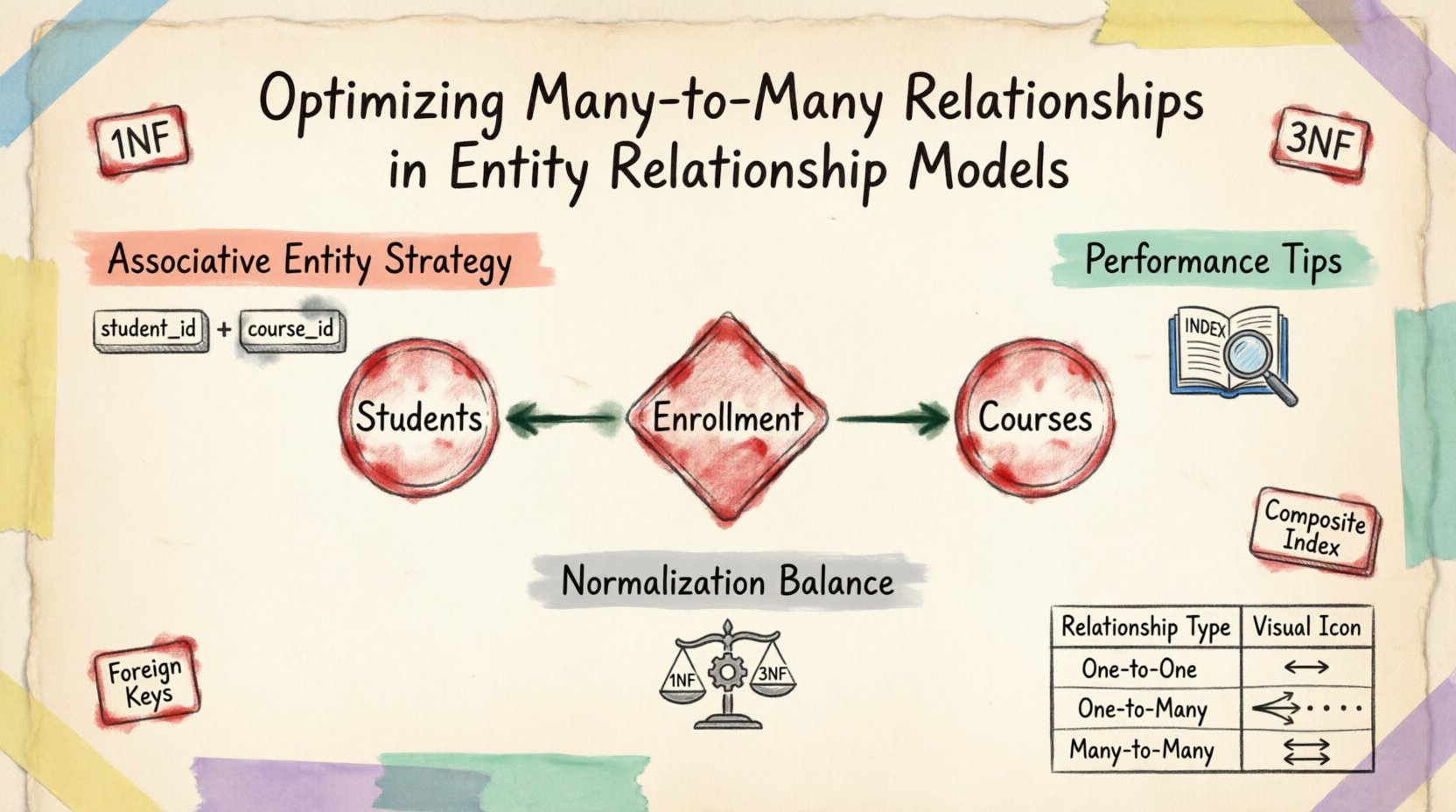
In einem konzeptuellen Modell ist eine Many-to-Many-Beziehung intuitiv. Denken Sie an Studierende und Kurse. Ein Studierender meldet sich für mehrere Kurse an, und jeder Kurs hat mehrere Studierende. Die direkte Darstellung dieser Beziehung in einer physischen Datenbankstruktur ist problematisch. Standardrelationstabellen unterstützen native ein-zu-viele- und ein-zu-eins-Beziehungen über Fremdschlüssel. Eine Many-to-Many-Beziehung erfordert eine Zwischenstruktur, um korrekt zu funktionieren.
Das Versuch, mehrere IDs in einer einzigen Spalte zu speichern (z. B. als durch Kommas getrennte Liste), verstößt gegen die Erste Normalform (1NF). Dieser Ansatz macht Abfragen, Indizierung und die Aufrechterhaltung der Datenintegrität nahezu unmöglich. Die Lösung besteht darin, die Beziehung in zwei ein-zu-viele-Beziehungen über eine assoziative Entität zu zerlegen, die oft als Verbindungstabelle oder Brückentabelle bezeichnet wird.
Die Strategie der assoziativen Entität 🧩
Die grundlegende Technik zur Lösung von Many-to-Many-Beziehungen ist die Einführung einer assoziativen Entität. Diese Entität fungiert als Brücke zwischen den beiden übergeordneten Tabellen. Sie enthält die Primärschlüssel beider übergeordneter Entitäten als Fremdschlüssel und bildet einen zusammengesetzten Primärschlüssel, der die Eindeutigkeit für jede Beziehungsinstantanz gewährleistet.
- Struktur: Die Tabelle enthält Fremdschlüssel, die auf die Primärschlüssel der zugehörigen Entitäten verweisen.
- Einzigartigkeit: Ein zusammengesetzter Schlüssel verhindert doppelte Beziehungen zwischen denselben beiden Datensätzen.
- Attribute: Diese Tabelle kann spezifische Daten über die Beziehung selbst speichern, nicht nur über die Entitäten.
Betrachten Sie eine Situation, bei der Mitarbeiter und Projekte verknüpft werden. Ein Mitarbeiter arbeitet an mehreren Projekten, und ein Projekt hat mehrere Mitarbeiter. Die Beziehungstabelle könnte das Zuweisungsdatum, die Rolle des Mitarbeiters in diesem Projekt oder die zugeordneten Stunden speichern. Diese Attribute gehören der Beziehung selbst, nicht dem Mitarbeiter oder dem Projekt einzeln.
Implementierungsschritte
- Entitäten identifizieren: Definieren Sie die beiden unterschiedlichen Entitäten, die an der Beziehung beteiligt sind.
- Verbindungstabelle erstellen: Erstellen Sie eine neue Tabelle mit einem beschreibenden Namen, z. B.
Mitarbeiter_Projekt_Zuweisungen. - Fremdschlüssel hinzufügen: Fügen Sie Spalten für die Primärschlüssel beider übergeordneter Entitäten hinzu.
- Einschränkungen definieren: Richten Sie Fremdschlüssel-Einschränkungen ein, um die Referenzintegrität zu gewährleisten.
- Indizierung: Wenden Sie Indizes auf Fremdschlüsselspalten an, um Join-Operationen zu beschleunigen.
Normalisierung und Datenintegrität 🛡️
Die Optimierung beinhaltet oft einen Kompromiss zwischen Normalisierung und Leistung. Während die Normalisierung Redundanz verringert, können übermäßig normalisierte Strukturen komplexe Joins erfordern, die Abfragen verlangsamen. Bei der Optimierung von Many-to-Many-Beziehungen ist es entscheidend, diese Faktoren im Gleichgewicht zu halten.
Die Dritte Normalform (3NF) ist im Allgemeinen das Ziel für operative Datenbanken. In diesem Zustand sollte die Verbindungstabelle keine transitiven Abhängigkeiten enthalten. Jedes nichtschlüsselbasierte Attribut muss vom Primärschlüssel abhängen. Wenn eine Verbindungstabelle Daten enthält, die sich nur auf einen der Fremdschlüssel beziehen, sollte sie in die jeweilige übergeordnete Tabelle verschoben werden.
Häufige Fehler bei der Normalisierung
- Redundante Fremdschlüssel: Einschließen desselben Fremdschlüssels in mehreren Verbindungstabellen ohne klare Hierarchie.
- Fehlende Einschränkungen: Nicht durchsetzen eindeutiger Einschränkungen für die Kombination von Fremdschlüsseln.
- Weiche Löschungen: Nicht Berücksichtigung gelöschter Datensätze in der Beziehungstabelle, was zu verwaisten Daten führt.
Strategien zur Leistungsoptimierung ⚡
Mit wachsendem Datenvolumen kann die Anzahl der Zeilen in einer Verbindungstabelle exponentiell ansteigen. Dies wirkt sich direkt auf die Ausführungszeiten von Abfragen aus. Mehrere Strategien können eine Leistungsverschlechterung abmildern.
1. Strategische Indizierung
Indizes sind entscheidend für die Join-Leistung. Ein zusammengesetzter Index auf den Fremdschlüsselspalten ist oft wirksamer als einzelne Indizes. Dadurch kann die Datenbankengine verwandte Zeilen schneller finden, ohne die gesamte Tabelle scannen zu müssen.
- Gebundene Indizes: In einigen Systemen kann das Gruppieren der Tabelle nach dem zusammengesetzten Schlüssel Bereichsabfragen verbessern.
- Abdeckende Indizes: Das Einbeziehen häufig abgefragter Spalten in den Index kann die Notwendigkeit vermeiden, auf den Tabellen-Heap zuzugreifen.
2. Partitionierung
Wenn eine Verbindungstabelle zu groß wird, um sie effizient verwalten zu können, kann die Partitionierung nach Datum oder Region die Last verteilen. Dies ist besonders nützlich für historische Daten, bei denen aktuelle Beziehungen häufiger abgerufen werden als ältere.
3. Abfrageoptimierung
Komplexe Abfragen mit mehreren Joins können Ressourcen belasten. Die Verwendung von Abfragehinweisen oder die Umstrukturierung des SQL, um Unterabfragen zu minimieren, kann helfen. Es ist auch wichtig, den Ausführungsplan zu analysieren, um Engpässe zu identifizieren.
| Strategie | Vorteil | Kompromiss |
|---|---|---|
| Zusammengesetzte Indizierung | Schnellerer Join-Zugriff | Erhöhter Speicher- und Schreibaufwand |
| Tabellenpartitionierung | Verbesserte Wartung und Scangeschwindigkeit | Komplexität in der Abfragelogik |
| Caching | Geringere Datenbanklast | Risiken für Datenkonsistenz |
Behandlung von Beziehungseigenschaften 📝
Einer der größten Vorteile der assoziativen Entität ist die Fähigkeit, Attribute spezifisch für die Beziehung zu speichern. Zum Beispiel haben in einem Vertragsverwaltungssystem ein Lieferant und ein Produkt eine many-to-many-Beziehung. Die Attribute könnten der Einzelpreis, das Beginndatum des Vertrags und die vereinbarte Menge umfassen.
Wenn Sie versuchen, diese Attribute in der Tabelle Lieferant oder Produkt zu speichern, entsteht Redundanz. Wenn sich der Preis ändert, müssten Sie mehrere Zeilen in der Produkttabelle aktualisieren. Indem Sie sie in der Verbindungstabelle platzieren, bewahren Sie eine einzige Quelle der Wahrheit für diese spezifische Beziehungseinheit auf.
Erweiterte Szenarien und Randfälle 🌐
Die Datenmodellierung in der Praxis stellt oft einzigartige Herausforderungen dar, die durch Standardmuster nicht sofort abgedeckt werden.
- Selbstreferenzierende Beziehungen: Eine Entität, die mit sich selbst verknüpft ist (z. B. ein Mitarbeiter, der andere Mitarbeiter verwaltet). Dazu ist ein Fremdschlüssel erforderlich, der auf den Primärschlüssel derselben Tabelle verweist.
- Kaskadierende Löschvorgänge: Entscheiden, ob das Löschen einer übergeordneten Entität automatisch deren Beziehungseinträge entfernen soll. Dies verhindert verwaiste Fremdschlüssel, kann aber historische Assoziationsdaten verlieren.
- Rekursive Beziehungen: Komplexe Hierarchien, bei denen die Verbindungstabelle auf sich selbst verweist.
Abfragen des optimierten Schemas 🔎
Sobald das Schema optimiert ist, erfordert die Abfrage präzise Arbeit. Entwickler müssen verstehen, wie der Datenbank-Engine die Join-Pfade durchläuft.
Beim Abrufen von Daten, wie allen Projekten für einen bestimmten Mitarbeiter, muss die Abfrage die Mitarbeiter-Tabelle mit der Verbindungstabelle und dann mit der Projekt-Tabelle verknüpfen. Effizientes SQL-Schreiben stellt sicher, dass die Datenbank die verfügbaren Indizes korrekt nutzt. Das Vermeiden von Funktionen auf indizierten Spalten im WHEREKlausel ist eine Standardpraxis, um die Nutzung von Indizes aufrechtzuerhalten.
Best Practices für Join-Logik
- Verwenden Sie explizite Joins:Bevorzugen Sie
INNER JOINoderLEFT JOINvor impliziten, durch Kommas getrennten Tabellen. - Beschränken Sie Spalten:Wählen Sie nur die erforderlichen Spalten aus, um die Netzwerkübertragung und die Verarbeitungszeit zu reduzieren.
- Filtern Sie früh:Wenden Sie Filter in der
WHEREKlausel an, bevor der Join erfolgt, falls möglich.
Vergleich von Beziehungstypen 📊
Das Verständnis, wo viele-zu-viele in den größeren Kontext der Datenmodellierung passt, hilft bei besseren Gestaltungsentscheidungen.
| Beziehungstyp | Struktur | Beispiel für einen Anwendungsfall |
|---|---|---|
| Ein-zu-einem | Einzelner Fremdschlüssel | Benutzerprofil und Benutzereinstellungen |
| Ein-zu-viele | Einzelner Fremdschlüssel | Bestellung und Bestellpositionen |
| Viele-zu-viele | Zwischentabelle | Schüler und Kurse |
Aufrechterhaltung der Datenkonsistenz 🔄
Sicherstellen, dass die Daten über verwandte Tabellen hinweg konsistent bleiben, ist von größter Bedeutung. Dies erfordert oft die Transaktionsverwaltung. Eine Transaktion sollte die Einfügung von Daten in die übergeordnete Tabelle und die Zwischentabelle umschließen. Wenn einer der Schritte fehlschlägt, sollte die gesamte Operation rückgängig gemacht werden, um partielle Datenzustände zu vermeiden.
Triggers können ebenfalls eingesetzt werden, um Geschäftslogik durchzusetzen, sollten aber sparsam verwendet werden, um versteckte Leistungseinbußen zu vermeiden. Beispielsweise könnte ein Trigger verhindern, dass ein Mitarbeiter einem Projekt zugewiesen wird, wenn dessen Abteilung nicht mit der Abteilung des Projekts übereinstimmt.
Überwachung und Wartung 📈
Nach der Bereitstellung erfordert das System eine kontinuierliche Überwachung. Das Wachstum der Zwischentabelle ist oft das erste Anzeichen für Skalierungsprobleme. Regelmäßige Audits der Tabellengrößen, Indexfragmentierung und Abfrageleistungsmetriken sind notwendig.
- Archivierung: Verschieben Sie historische Beziehungsdaten in eine kalte Speicherung, wenn sie nicht mehr aktiv abgefragt werden.
- Neuindizierung: Stellen Sie regelmäßig die Neuerstellung oder Umstrukturierung von Indizes sicher, um eine optimale Leistung aufrechtzuerhalten.
- Überprüfung von Joins: Stellen Sie sicher, dass Anwendungsänderungen keine ineffizienten Abfragemuster einführen.
Abschließende Gedanken zur Tabellengestaltung 🎯
Die Optimierung von viele-zu-viele-Beziehungen ist keine einmalige Aufgabe, sondern ein kontinuierlicher Prozess der Verfeinerung. Es erfordert ein Gleichgewicht zwischen theoretischer Korrektheit und praktischer Leistungsfähigkeit. Durch Einhaltung der Normalisierungsprinzipien, Nutzung assoziativer Entitäten und gezielte Indizierung können Datenbankarchitekten Systeme schaffen, die sowohl robust als auch effizient sind. Das Ziel besteht darin, eine Struktur zu schaffen, die die Geschäftslogik unterstützt, ohne unnötige Einschränkungen für die Datenabruf- oder Änderungsoperationen zu verursachen.