











Relationale Datenbanken basieren auf der Grundlage von Tabellen und Zeilen, einer Struktur, die für flache Daten konzipiert ist. Doch die reale Welt hält sich selten an eine solche Einfachheit. Organisationen, Dateisysteme, Kommentarverläufe und Kategorietrees existieren alle in hierarchischen Strukturen. Die Darstellung dieser Eltern-Kind-Beziehungen in einem standardmäßigen Entity-Relationship-Diagramm (ERD) erfordert spezifische Gestaltungsmuster, die die Datenintegrität bewahren, während gleichzeitig eine effiziente Abfrage ermöglicht wird.
Wenn Sie versuchen, eine Baumstruktur auf ein flaches Schema abzubilden, begegnen Sie der klassischen Spannung zwischen Normalisierung und Leistung. Dieser Leitfaden untersucht die zentralen Techniken zur Modellierung hierarchischer Daten und bewertet die Vor- und Nachteile jeder Herangehensweise, um Ihnen bei der Gestaltung robuster Systeme zu helfen.
🧩 Die Herausforderung flacher Schemata
Ein Entity-Relationship-Diagramm visualisiert Entitäten typischerweise als Rechtecke und Beziehungen als Linien. Bei einer Standardbeziehung verknüpft eine Tabelle über eine Fremdschlüsselverbindung eine andere Tabelle. Dies funktioniert perfekt bei vielen-zu-viele- oder ein-zu-viele-Szenarien, bei denen die Richtung festgelegt ist. Doch was passiert, wenn eine Kategorie Unterkategorien haben kann, die wiederum Untertypen haben können, potenziell unendlich?
Standardrelationale Modelle haben Schwierigkeiten mit variabler Tiefe. Eine flache Tabelle kann keine Pfadlänge beliebiger Länge einfach speichern. Um dies zu lösen, müssen wir das Schema anpassen, um die Hierarchie explizit zu speichern. Es gibt drei primäre Muster, die Datenarchitekten verwenden, um dies zu erreichen:
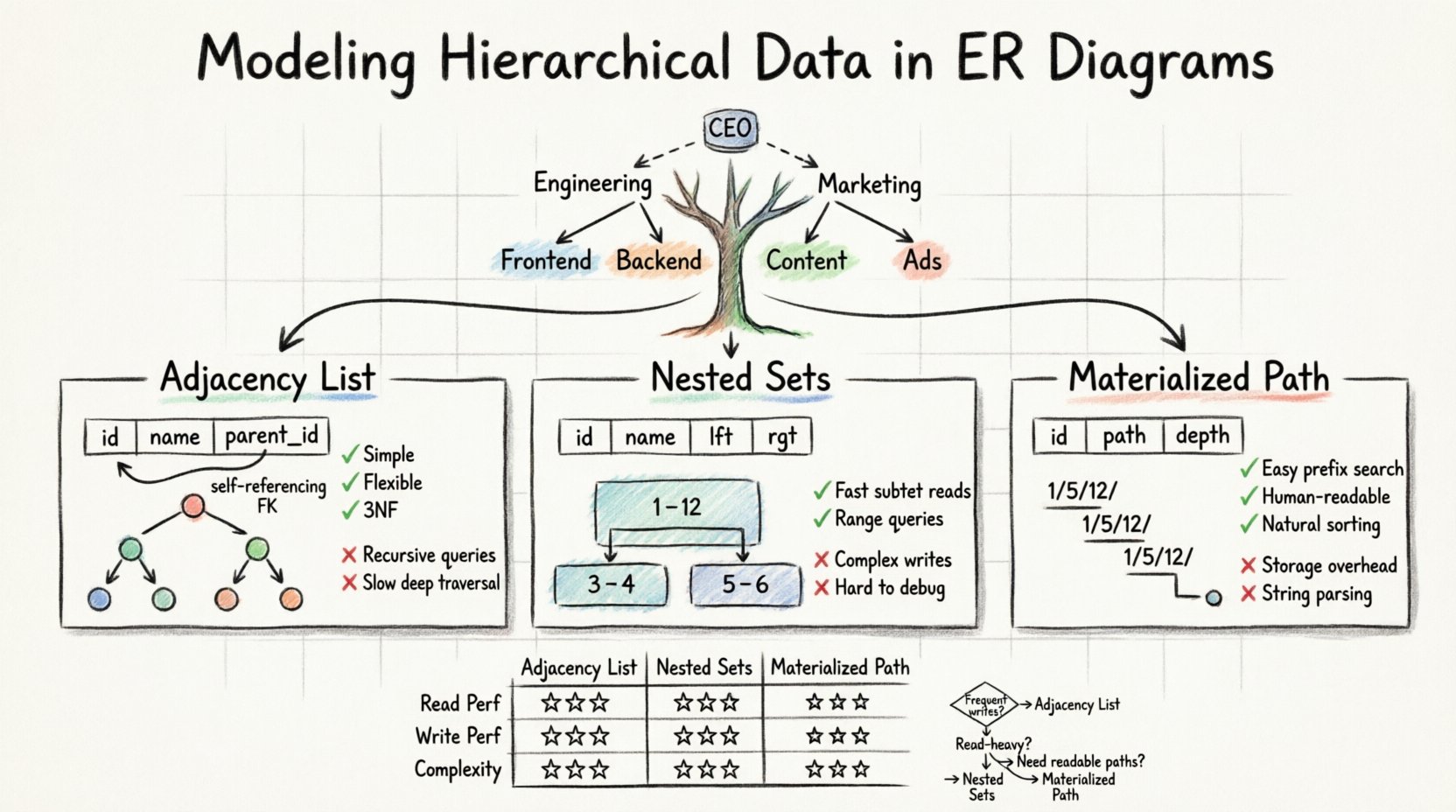
- Adjazenzliste: Speichern der Eltern-ID innerhalb des Kinddatensatzes.
- Verschachtelte Mengen: Zuweisen von linken und rechten Werten, um Bereiche zu definieren.
- Pfadzählung: Speichern des vollständigen Pfads vom Stammknoten zum aktuellen Knoten.
🔗 Das Adjazenzlistenmodell
Die Adjazenzliste ist die häufigste und einfachste Methode zur Darstellung von Hierarchien in einem standardmäßigen ERD. Sie beruht auf einer Selbstverweisung. Das bedeutet, dass eine einzelne Tabelle eine Spalte enthält, die auf ihren eigenen Primärschlüssel verweist.
📐 Schema-Struktur
Bei diesem Modell erstellen Sie eine einzelne Tabelle, um die Daten zu speichern. Jede Zeile stellt einen Knoten im Baum dar. Die entscheidende Ergänzung ist eine Spalte, die oft als parent_id oder ancestor_id, die die eindeutige Kennung des Elternknotens enthält. Wenn ein Knoten an der Spitze der Hierarchie steht, enthält diese Spalte einen Nullwert.
Betrachten Sie eine Tabelle für Abteilung:
- id: Der eindeutige Primärschlüssel für die Abteilung.
- name: Der Anzeigename der Abteilung.
- parent_id: Die ID der übergeordneten Abteilung (kann für die oberste Ebene null sein).
✅ Vorteile
- Einfachheit: Das Schema ist intuitiv und leicht verständlich für Entwickler und Datenbankadministratoren.
- Flexibilität: Das Verschieben eines Teilbaums ist einfach; Sie müssen nur die
parent_iddes Wurzelknotens dieses Teilbaums aktualisieren. - Normalisierung: Es entspricht gut der Dritten Normalform (3NF), da Daten nicht wiederholt werden.
❌ Nachteile
- Abfragekomplexität: Das Abrufen aller Nachkommen erfordert rekursive Abfragen oder Verarbeitung auf Anwendungsebene.
- Leistung: Tiefgehende Durchläufe können langsam sein, ohne spezifische Indexstrategien oder rekursive gemeinsame Tabellenausdrücke (CTEs).
- Referenzielle Integrität: Obwohl Fremdschlüssel helfen, können zirkuläre Referenzen dennoch auftreten, wenn Beschränkungen nicht strikt durchgesetzt werden.
🌲 Das verschachtelte Mengenmodell
Das verschachtelte Mengenmodell wandelt die Baumstruktur in eine Menge von Intervallen um. Anstatt Elternzeiger zu verfolgen, erhält jeder Knoten zwei Zahlen: links und rechts. Diese Werte stellen die Position des Knotens bei einer Vorwärtsdurchlauf des Baums dar.
📐 Schema-Struktur
Stellen Sie sich einen Baum vor, bei dem der Wurzelknoten die gesamte Menge ist. Wenn Sie den Baum durchlaufen, erhöhen Sie einen Zähler. Wenn Sie einen Knoten betreten, notieren Sie den aktuellen Zählerstand als links. Wenn Sie die Verarbeitung dieses Knotens und aller seiner Kinder abgeschlossen haben, notieren Sie den Zählerstand als rechts. Die rechts Wert ist immer größer als der links Wert.
Eine KategorieTabelle würde folgendermaßen aussehen:
- ID: Eindeutiger Bezeichner.
- Name: Kategorienname.
- links: Der Wert der linken Grenze.
- rechts: Der Wert der rechten Grenze.
✅ Vorteile
- Schnelle Abrufzeit:Das Abrufen eines Teilbaums ist eine einfache Bereichsabfrage mit Hilfe von
ZWISCHENLogik. - Effizienz: Die Leseleistung ist bei großen, tiefen Bäumen besser als bei Nachbarschaftslisten.
❌ Nachteile
- Schreibkosten:Das Einfügen oder Verschieben eines Knotens ist kostspielig. Sie müssen die
linksundrechtsWerte vieler anderer Knoten aktualisieren, um die Integrität der Intervalle aufrechtzuerhalten. - Komplexität: Die Logik ist schwierig zu implementieren und zu debuggen, ohne Unterstützung durch spezialisierte Bibliotheken.
🛣️ Pfadenumerierung und Materialisierte Pfade
Die Methoden der Pfadenumerierung speichern die Abstammung eines Knotens als Zeichenkette oder als durch Trennzeichen getrennte Liste. Dieser Ansatz wird oft als Muster des materialisierten Pfads bezeichnet. Er verbindet die Einfachheit der Nachbarschaftsliste mit der Lesbarkeit des Pfads.
📐 Schemastruktur
In diesem Modell speichert jeder Datensatz den vollständigen Pfad vom Stamm. Zum Beispiel könnte eine Datei im Dateisystemmodell eine Pfadzeichenkette wie /home/user/documents/report.txt. In einer Datenbank wird dies oft als durch Trennzeichen getrennte Zeichenkette innerhalb der Spalte gespeichert, beispielsweise 1/5/12/.
Die Tabelle enthält:
- id: Primärschlüssel.
- pfad: Eine Zeichenkette, die die Abstammung darstellt.
- tiefe: Eine Ganzzahl, die angibt, wie viele Ebenen tief der Knoten ist.
✅ Vorteile
- Einfache Durchquerung: Sie können alle Nachkommen finden, indem Sie den Pfadpräfix abgleichen.
- Lesbarkeit: Die Daten sind menschenlesbar und leicht zu debuggen.
- Sortierung: Die Sortierung nach der Pfadzeichenkette ergibt oft von Natur aus die richtige Baumreihenfolge.
❌ Nachteile
- Speicherüberhead: Lange Pfade können erheblichen Speicherplatz verbrauchen.
- Zeichenkettenanalyse: Abfragen erfordern oft Funktionen zur Zeichenkettenmanipulation, die langsamer sein können als Ganzzahlabgleiche.
📊 Vergleichsanalyse
Die Wahl des richtigen Modells hängt stark von Ihrem Lese-Schreib-Verhältnis und der Tiefe Ihrer Hierarchie ab. Die folgende Tabelle beschreibt die Eigenschaften jeder Methode.
| Funktion | Adjazenzliste | Verschachtelte Mengen | Materialisierter Pfad |
|---|---|---|---|
| Lesegeschwindigkeit | Niedrig bis mittel | Hoch | Mittel bis hoch |
| Schreibgeschwindigkeit | Hoch | Niedrig | Mittel |
| Implementierungskomplexität | Niedrig | Hoch | Mittel |
| Unterstützt tiefe Bäume | Ja | Ja | Ja (mit Einschränkungen) |
| Abfrage-Logik | Rekursiv | Bereichsscan | Präfixübereinstimmung |
⚙️ Leistungsaspekte
Beim Modellieren von Hierarchien müssen Sie berücksichtigen, wie der Datenbank-Engine die Daten verarbeitet. Indexstrategien spielen eine entscheidende Rolle, unabhängig vom gewählten Modell.
- Adjazenzliste: Indizieren Sie die
parent_idSpalte stark. Dadurch kann die Datenbank alle Kinder eines bestimmten Knotens schnell finden, ohne die gesamte Tabelle scannen zu müssen. - Verschachtelte Mengen: Indiziere beide
lftundrgt. Zusammengesetzte Indizes können Bereichsabfragen erheblich optimieren. - Materialisierter Pfad: Indiziere die
PfadSpalte. Je nach Datenbank kann ein Präfixindex vorteilhaft sein, um Unterbäume zu filtern.
🛠️ Wartung und Aktualisierungen
Datenmodelle sind nicht statisch. Je mehr sich Ihre Organisation entwickelt, desto mehr ändert sich Ihre Hierarchie. Das Verschieben eines Knotens von einer Verzweigung in eine andere ist eine häufige Operation, die jedes Modell unterschiedlich beeinflusst.
🔄 Verschieben von Knoten
Bei einem Nachbarschaftsliste, ist das Verschieben eines Knotens eine einzelne Aktualisierungsanweisung. Sie ändern die parent_id des Wurzelknotens des Unterbaums. Sie müssen jedoch sicherstellen, dass keine zirkulären Verweise entstehen.
Bei einem Verschachteltem SetModell ist das Verschieben eines Knotens komplex. Es erfordert die Neuberechnung der lft und rgt Werte aller Knoten im Zielunterbaum, um Platz für den verschobenen Knoten zu schaffen. Dies ist oft eine transaktionale Operation, die mehrere Tabellenaktualisierungen erfordert.
Bei einem Materialisierter PfadModell aktualisieren Sie die Pfadzeichenfolge des verschobenen Knotens und aller seiner Nachkommen. Dies erfordert die Aktualisierung des Pfads für jedes Kind, was bei großen Bäumen eine aufwendige Schreiboperation sein kann.
🎯 Best Practices für die Datenmodellierung
Um sicherzustellen, dass Ihr ERD wartbar und leistungsfähig bleibt, beachten Sie diese Richtlinien bei der Implementierung hierarchischer Strukturen.
- Verwenden Sie klare Namenskonventionen: Vermeide generische Namen wie
col1. Verwendeparent_id,ancestor_id,lft, oderrgtexplizit. - Beschränkungen durchsetzen: Verwende Datenbankbeschränkungen, um zirkuläre Referenzen zu verhindern. Ein Knoten kann nicht sein eigener Vorfahre sein.
- Tiefenbegrenzung: Obwohl technisch möglich, weisen extrem tiefe Hierarchien (z. B. mehr als 10 Ebenen) oft auf einen Designfehler hin. Überlege, die Struktur zu vereinfachen, wenn möglich.
- Wähle die Dokumentation: Da diese Muster keine Standard-SQL-Funktionen sind, dokumentiere, welches Muster in der Schema-Dokumentation verwendet wird.
- Überlege hybride Ansätze: Einige Systeme kombinieren Adjazenzlisten mit materialisierten Pfaden, um Lese- und Schreibleistung auszugleichen.
🧠 Die richtige Strategie wählen
Es gibt keine einzige „richtige“ Antwort für jedes Szenario. Die Entscheidung hängt von den spezifischen Anforderungen deiner Anwendung ab.
- Wähle Adjazenzliste, wenn: Deine Daten ändern sich häufig, und die Hierarchietiefe ist moderat. Dies ist die sicherste Voreinstellung für die meisten allgemeinen Anwendungen.
- Wähle verschachtelte Mengen, wenn: Du hast eine Lese-lastige Anwendung, bei der Daten selten verschoben werden, und du große Teilbäume schnell abrufen musst.
- Wähle materialisierten Pfad, wenn: Du brauchst menschenlesbare Pfade (wie URLs) und die Hierarchietiefe ist relativ gering.
Das Verständnis dieser strukturellen Feinheiten ermöglicht es dir, Datenbanken zu gestalten, die skalieren. Durch die Auswahl des geeigneten Musters für dein Entitäts-Beziehungs-Diagramm stellst du sicher, dass deine Daten während des gesamten Lebenszyklus des Systems konsistent, zugänglich und effizient bleiben.