











Die Gestaltung eines robusten Datenmodells erfordert mehr als nur die Definition von Beziehungen zwischen Tabellen. Es erfordert die Vorhersage der Entwicklung von Daten im Laufe der Zeit und die Sicherstellung, dass jede Änderung nachvollziehbar ist. Ein Audit-Verlauf innerhalb eines Entitäts-Beziehungs-Diagramms (ERD) dient als Grundlage für Verantwortlichkeit und Datenherkunft. Durch die explizite Modellierung von Nachverfolgungsmechanismen direkt in das Schema können Organisationen die Integrität aufrechterhalten, ohne sich ausschließlich auf externe Protokollierungssysteme zu verlassen.
Warum Datenänderungen verfolgen? 📊
Die Implementierung von Audit-Funktionen ist nicht nur eine technische Vorliebe; sie ist oft eine regulatorische Anforderung. Branchen, die sensible Informationen verarbeiten, müssen nachweisen können, wer auf welche Daten und wann zugegriffen hat. Abgesehen von der Compliance liefern Audit-Verläufe kritische Informationen zur Fehlersuche bei Systemausfällen. Wenn ein Datenunterschied auftritt, ermöglichen historische Aufzeichnungen Ingenieuren, den Zustand der Datenbank zu jedem beliebigen Zeitpunkt wiederherzustellen.
- Compliance: Vorschriften verlangen oft die Aufbewahrung von Änderungsprotokollen für bestimmte Zeiträume.
- Sicherheit: Erkennen von nicht autorisierten Änderungen oder Datenverletzungen.
- Debugging: Rückverfolgung der Ursache von Datenkorruption oder Logikfehlern.
- Verantwortlichkeit: Genau wissen, welcher Benutzer oder Prozess eine Datensatzaktualisierung initiiert hat.
Wichtige Bestandteile eines Audit-Schemas 🏗️
Beim Einbinden von Audit-Verläufen in Ihr ERD müssen bestimmte Spalten vorhanden sein, um die erforderlichen Metadaten zu erfassen. Diese Felder sollten über alle Entitäten hinweg standardisiert sein, um Konsistenz bei Berichten und Abfragen zu gewährleisten.
Wichtige Metadatenfelder
Jede nachvollziehbare Entität sollte eine Reihe grundlegender Attribute enthalten. Diese Felder dokumentieren den Lebenszyklus des Datensatzes.
- Datensatz-Identifikator: Ein eindeutiger Schlüssel, um die spezifische Version des Datensatzes zu unterscheiden.
- Erstellungszeitstempel: Das genaue Datum und die genaue Uhrzeit, zu der der Datensatz eingefügt wurde.
- Letzter Änderungszeitstempel: Der letzte Zeitpunkt, zu dem der Datensatz geändert wurde.
- Erstellt von: Die Benutzer-ID oder der Systemprozess, der für die Einfügung verantwortlich ist.
- Zuletzt geändert von: Die Benutzer-ID oder der Systemprozess, der für die letzte Änderung verantwortlich ist.
- Aktionstyp: Gibt an, ob die Aktion eine Einfügung, Aktualisierung oder Löschung war.
Implementierungsstrategien 🛠️
Es gibt mehrere architektonische Ansätze zur Modellierung dieser Änderungen. Jede Strategie bietet unterschiedliche Kompromisse hinsichtlich Speicherplatz, Abfrageleistung und Komplexität. Die Wahl hängt von den spezifischen Anforderungen der Anwendung und dem Datenvolumen ab.
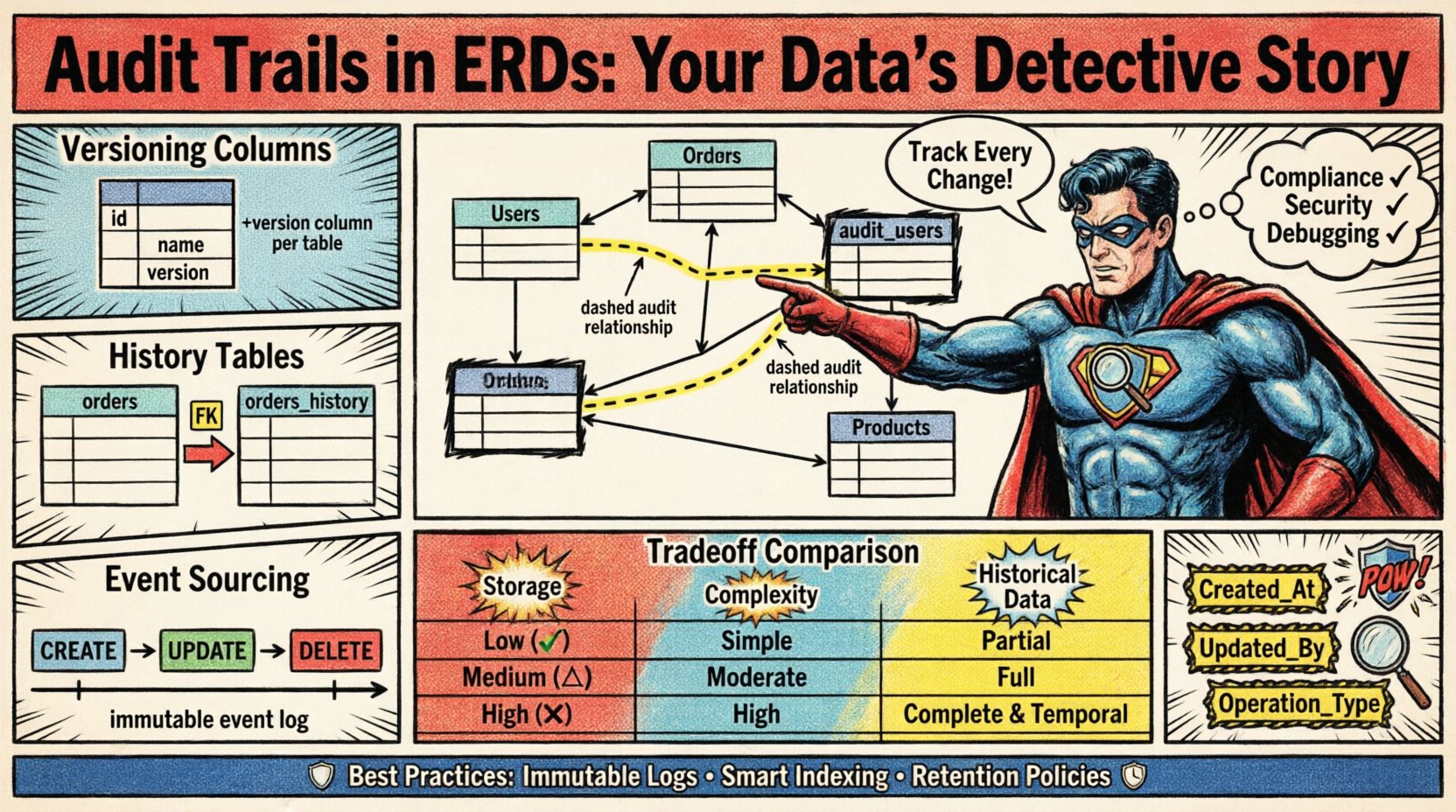
1. Versionsspalten (weiche Aktualisierungen)
Bei diesem Ansatz werden Audit-Spalten direkt in die Hauptentitätstabelle hinzugefügt. Es ist die einfachste Methode zur Umsetzung.
- Vorteile:Minimale Änderungen am Schema; einfache Abfrage des aktuellen Zustands mit Verlauf.
- Nachteile:Erhält keine historischen Snapshots; zeigt nur die Metadaten der letzten Änderung.
2. Parallele Historietabellen
Anstatt die Haupttabelle zu verändern, werden Änderungen in einer separaten Tabelle protokolliert, die über eine Fremdschlüsselbeziehung verknüpft ist. Dadurch ist ein vollständiger Verlauf jeder Änderung möglich.
- Vorteile:Saubere Trennung von aktuellen Daten und Historie; vollständige Snapshot-Funktion.
- Nachteile:Erhöhter Speicherbedarf; komplexere Abfragen, die Joins erfordern.
3. Ereignisquellen
Der gesamte Zustand der Entität wird aus einem Ereignisprotokoll rekonstruiert. Die Datenbank speichert nur die Änderungen, nicht den aktuellen Zustand.
- Vorteile:Vollständige Nachvollziehbarkeit; unveränderliche Datenquelle.
- Nachteile:Hohe Komplexität in der Rekonstruktionslogik; Leistungseinbußen bei der Zustandsberechnung.
Entwerfen der Beziehungen 🔗
Das ERD muss visuell darstellen, wie die Audit-Daten mit den Geschäftsentitäten verknüpft sind. Eine klare visuelle Unterscheidung hilft Entwicklern, das Schema zu verstehen, ohne Dokumentation lesen zu müssen.
- Eins-zu-Viele:Ein einzelner Entitätsdatensatz kann viele Audit-Protokolleinträge haben.
- Fremdschlüssel:Die Audit-Tabelle sollte auf den Primärschlüssel der Quellentität verweisen.
- Indizierung:Fremdschlüssel in der Audit-Tabelle müssen indiziert werden, um Abfragen zu beschleunigen.
Zeichnen Sie beim Erstellen des Diagramms gestrichelte Linien, um Audit-Beziehungen anzugeben. Dadurch unterscheiden sie sich von standardmäßigen Geschäftslogik-Beziehungen, wie Kundenbestellungen oder Produktlagerbestände.
Vergleichende Analyse der Methoden 📋
Die Auswahl des richtigen Musters erfordert das Verständnis des operativen Kontexts. Die folgende Tabelle beschreibt die Eigenschaften gängiger Ansätze.
| Funktion | Versionsverwaltungs-Spalten | Verlaufstabellen | Ereignisquellen |
|---|---|---|---|
| Speicherüberhead | Niedrig | Mittel | Hoch |
| Abfragekomplexität | Einfach | Mäßig | Komplex |
| Historische Daten | Nur Metadaten | Vollständige Schnappschüsse | Vollständiger Ereignisstrom |
| Implementierungsaufwand | Niedrig | Mittel | Hoch |
Leistungsüberlegungen ⚡
Audit-Protokolle fügen jeder Transaktion Schreib-Overhead hinzu. Je größer das Datenvolumen wird, desto signifikanter wird die Auswirkung auf die Systemleistung. Eine geeignete Indizierung und Partitionierung sind notwendig, um die Latenz zu minimieren.
- Indizierungsstrategie: Erstellen Sie Indizes auf den updated_by und updated_atSpalten. Dies erleichtert die schnelle Berichterstattung über Benutzeraktivitäten.
- Partitionierung: Bei Systemen mit hohem Datenaufkommen sollten Audit-Tabellen nach Datum partitioniert werden. Dadurch bleibt aktive Daten in schnellem Speicher, während ältere Datensätze in langsamen Speicher verlegt werden.
- Stapelverarbeitung: Anstatt jeden Mikro-Änderung zu protokollieren, überlegen Sie, Updates zu bündeln, wenn eine Echtzeitverfolgung nicht strikt erforderlich ist.
Datensicherheit und Integrität 🔒
Sicherheit ist bei der Gestaltung von Audit-Mechanismen von höchster Bedeutung. Die Audit-Spur selbst muss vor Manipulation geschützt werden. Wenn ein Angreifer die Protokolle verändern kann, verliert das System an Glaubwürdigkeit.
- Unveränderliche Protokolle: Stellen Sie sicher, dass Audit-Protokolle von normalen Benutzern nicht gelöscht oder verändert werden können.
- Zugriffssteuerung: Beschränken Sie den Schreibzugriff auf die Audit-Tabellen auf Systemprozesse oder privilegierte Konten.
- Validierung: Stellen Sie sicher, dass die in den Audit-Protokollen referenzierten Benutzer-IDs tatsächlich im Benutzerverzeichnis existieren.
Wartung und Lebenszyklus 🔄
Datenaufbewahrungsrichtlinien bestimmen, wie lange Audit-Informationen aufbewahrt werden müssen. Die unbegrenzte Speicherung dieser Daten ist ineffizient und kostspielig. Ein definiertes Lebenszyklus-Management ist unerlässlich.
- Archivierung: Verschieben Sie Datensätze, die älter als eine bestimmte Schwelle sind, in eine separate Archiv-Datenbank.
- Bereinigung: Löschen Sie automatisch Datensätze, die die gesetzlichen Aufbewahrungsfristen überschritten haben.
- Überwachung: Richten Sie Warnungen für die Wachstumsraten der Audit-Tabellen ein, um eine Speichererschöpfung zu verhindern.
Best Practices für die Namensgebung von Schemata 📝
Konsistente Namenskonventionen reduzieren die Verwirrung während der Entwicklung und Wartung. Die Einhaltung eines standardisierten Namensmusters stellt sicher, dass Audit-Spalten im gesamten System leicht identifizierbar sind.
- Präfixe: Verwenden Sie Präfixe wie
audit_oder_logfür Tabellennamen. - Zeitstempel: Verwenden Sie
_atSuffixe für Zeitspalten (z. B.created_at). - Bezeichner: Verwenden
_bySuffixe für Benutzerreferenzen (z. B.updated_by). - Fremdschlüssel: Benennen Sie Schlüssel explizit (z. B.
source_entity_id) zur Klärung der Beziehung.
Durch die Integration dieser Praktiken in das Entity-Relationship-Diagramm erstellen Entwickler ein System, das transparent und widerstandsfähig ist. Das Diagramm wird zu einem lebendigen Dokument, das nicht nur die Datenspeicherung, sondern auch die Datenverwaltung während ihres gesamten Bestehens leitet.
Fazit 📌
Die Einbindung einer Prüfungsverfolgung in das Datenmodell ist ein grundlegender Schritt für moderne Datenarchitektur. Sie verwandelt ein statisches Diagramm in ein dynamisches Werkzeug für die Datenverwaltung. Unabhängig davon, ob Versionierungs-Spalten oder spezielle Historietabellen verwendet werden, bleibt das Ziel gleich: sicherzustellen, dass jede Aktion innerhalb des Systems protokolliert und abrufbar ist. Sorgfältige Planung von Beziehungen, Indizierung und Archivierungsrichtlinien stellt sicher, dass die Prüfungsverfolgung die Geschäftstätigkeit unterstützt, ohne die Leistung zu beeinträchtigen.