











In der modernen Datenarchitektur hängt die Zuverlässigkeit der Informationen von den strukturellen Schutzmaßnahmen ab, die in die Entwurfsphase integriert sind. Datenintegrität ist kein nachträglicher Gedanke, sondern die Grundlage vertrauenswürdiger Systeme. Beim Entwerfen eines Entitäts-Beziehungs-Diagramms (ERD) soll ein Leitbild geschaffen werden, das von Natur aus Korruption, Inkonsistenz und Verlust verhindert. Durch die Anwendung strenger Beschränkungen stellen Architekten sicher, dass die Datenbank unter Last und über Transaktionen hinweg vorhersehbar reagiert.
Ohne diese durchgesetzten Regeln wird Daten anfällig für menschliche Fehler, Anwendungsfehler und Probleme bei gleichzeitiger Zugriffsvergabe. Ein gut strukturiertes ERD fungiert als Vertrag zwischen der Anwendungslogik und der Speicherebene und definiert, was zulässig und was verboten ist. Dieser Artikel erläutert die Mechanismen zur Aufrechterhaltung der Konsistenz durch strenge Gestaltungsprinzipien.
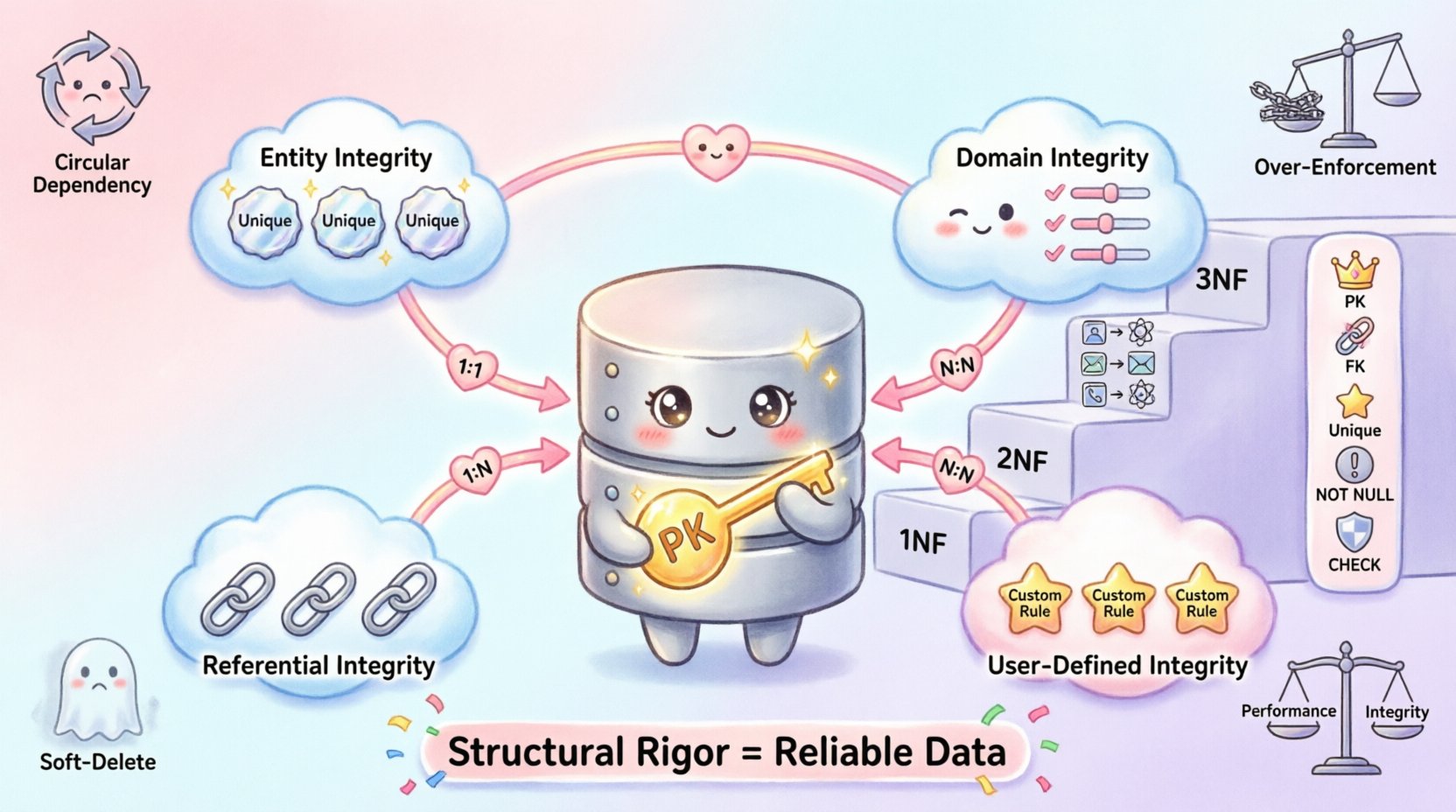
Verständnis der Ebenen der Datenintegrität 🔍
Integrität ist kein einzelner Begriff, sondern eine Sammlung von Regeln, die auf verschiedenen Ebenen der Datenbankstruktur gelten. Die Erkennung dieser Ebenen ermöglicht eine gezielte Implementierung von Beschränkungen.
1. Entitätsintegrität
Die Entitätsintegrität stellt sicher, dass jede Zeile in einer Tabelle eindeutig identifizierbar ist. Dies ist die grundlegendste Anforderung für jedes relationale Modell. Ohne eindeutige Identifikation ist das Verfolgen von Änderungen oder Beziehungen unmöglich.
- Primärschlüssel: Eine Spalte oder eine Gruppe von Spalten, die als eindeutiger Identifikator für einen Datensatz festgelegt ist.
- Nicht null: Die Spalte des Primärschlüssels darf keine Nullwerte enthalten, was sicherstellt, dass jeder Datensatz existiert.
- Einzigartigkeit: Zwei Zeilen können keinen gemeinsamen Primärschlüsselwert haben.
2. Domänenintegrität
Die Domänenintegrität beschränkt die Werte, die in einer bestimmten Spalte gespeichert werden dürfen. Dadurch wird sichergestellt, dass die Daten innerhalb der erwarteten Parameter bleiben, wie z. B. Datentypen, Bereiche oder Formate.
- Daten-Typen: Sicherstellen, dass eine Spalte für das Alter nur ganze Zahlen, nicht Text, speichert.
- Prüfbeschränkungen: Überprüfen, ob ein Wert innerhalb eines bestimmten Bereichs liegt, wie beispielsweise ein Prozentsatz zwischen 0 und 100.
- Standardwerte: Bereitstellen eines Rückfallwerts, falls kein Wert beim Einfügen angegeben wird.
3. Referenzielle Integrität
Dies stellt sicher, dass die Beziehungen zwischen Tabellen konsistent bleiben. Wenn ein Datensatz in einer Tabelle auf einen anderen verweist, muss der Ziel-Datensatz existieren. Dadurch werden verwaiste Datensätze verhindert, die auf nicht existierende Daten verweisen.
- Fremdschlüssel: Eine Spalte, die mit dem Primärschlüssel einer anderen Tabelle verknüpft ist.
- Kaskadierungsregeln: Festlegen von Aktionen (Löschen oder Aktualisieren), wenn der übergeordnete Datensatz geändert wird.
- Behandlung von Nullwerten: Entscheiden, ob eine Beziehung optional (null) oder obligatorisch ist.
4. Benutzerdefinierte Integrität
Dies sind geschäftsbezogene Regeln, die nicht zu standardmäßigen Kategorien passen. Sie erfordern oft benutzerdefinierte Logik innerhalb der Entwurfs- oder Anwendungsschicht.
- Benutzerdefinierte Validierung:Sicherstellen, dass ein Datum nicht in der Zukunft liegt.
- Bedingte Logik: Wenn ein Status „Storniert“ ist, dürfen keine anderen Zahlungsdatensätze vorhanden sein.
Kern-ERD-Beschränkungen und ihre Auswirkungen 🧱
Das ERD visualisiert diese Beschränkungen und macht sie für Entwickler und Stakeholder sichtbar. Die folgende Tabelle beschreibt gängige Beschränkungen, ihren Zweck und ihre Auswirkungen auf die Datenkonsistenz.
| Beschränkungstyp | Funktion | Durchsetzungsstelle |
|---|---|---|
| Primärschlüssel | Identifiziert Zeilen eindeutig | Tabellendefinition |
| Fremdschlüssel | Verbindet Tabellen miteinander | Beziehungsline |
| Einzigartig | Verhindert doppelte Werte in einer Spalte | Spaltendefinition |
| Nicht null | Erfordert einen Wert für das Feld | Spaltendefinition |
| Prüfung | Prüft den Wert anhand einer Bedingung | Spalten- oder Tabellendefinition |
Wenn diese Beschränkungen im Entwurf korrekt definiert sind, setzt der zugrundeliegende Datenbank-Engine sie automatisch durch. Dadurch wird die Validierung aus dem Anwendungscode entlastet und das Risiko von Fehlern und Sicherheitslücken verringert.
Beziehungskardinalität und Integrität 🔄
Die Linien, die Entitäten in einem ERD verbinden, stellen Beziehungen dar. Die Kardinalität dieser Beziehungen bestimmt die Strenge der erforderlichen Integritätsregeln.
Ein-zu-eins-Beziehungen
Dies tritt auf, wenn ein Datensatz in Tabelle A genau einem Datensatz in Tabelle B entspricht. Dies ist üblich, um große Tabellen aus Sicherheits- oder Leistungsgründen zu teilen.
- Beschränkung: Beide Seiten erzwingen typischerweise die Eindeutigkeit des Fremdschlüssels.
- Beispiel: Eine Person und ihren Reisepass. Eine Person hat einen Reisepass; ein Reisepass gehört einer Person.
Ein-zu-Viele-Beziehungen
Der häufigste Beziehungstyp. Ein Datensatz in Tabelle A kann mit mehreren Datensätzen in Tabelle B verknüpft sein.
- Beschränkung: Der Fremdschlüssel befindet sich in der Tabelle der „Viele“-Seite.
- Integrität: Der Fremdschlüssel muss auf einen vorhandenen Primärschlüssel in der Tabelle der „Eins“-Seite verweisen.
- Beispiel: Ein Kunde und seine Bestellungen. Ein Kunde hat viele Bestellungen; eine Bestellung gehört einem Kunden.
Viele-zu-Viele-Beziehungen
Dazu ist eine Verbindungstabelle erforderlich, um die Beziehung in zwei Ein-zu-Viele-Verbindungen aufzulösen.
- Beschränkung: Die Verbindungstabelle enthält zusammengesetzte Primärschlüssel oder eindeutige Beschränkungen, um doppelte Verbindungen zu verhindern.
- Integrität: Verhindert zirkuläre Daten oder überflüssige Einträge in der Verbindungstabelle.
- Beispiel: Studierende und Kurse. Ein Studierender besucht viele Kurse; ein Kurs hat viele Studierende.
Normalisierung und Datenkonsistenz 📐
Die Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Obwohl sie oft als Leistungs-Optimierung betrachtet wird, ist sie vor allem eine Strategie zur Datenintegrität.
Erste Normalform (1NF)
Stellt sicher, dass jede Spalte atomare Werte enthält. Keine Listen oder Arrays innerhalb einer einzigen Zelle.
- Vorteil: Vereinfacht die Abfrage und stellt konsistente Datentypen sicher.
- Verletzungsrisiko:Die Speicherung mehrerer Telefonnummern in einem Feld macht das Aktualisieren einer einzelnen Nummer schwierig.
Zweite Normalform (2NF)
Erfordert, dass die Tabelle in 1NF ist und alle nicht-schlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen.
- Vorteil: Beseitigt partielle Abhängigkeiten.
- Verletzungsrisiko: Die Speicherung von Kundenadressdaten in einer Bestellungstabelle führt zu Redundanz, wenn der Kunde umzieht.
Dritte Normalform (3NF)
Erfordert, dass die Tabelle in 2NF ist und keine transitiven Abhängigkeiten aufweist.
- Vorteil: Stellt sicher, dass Attribute nur vom Schlüssel abhängen.
- Verletzungsrisiko: Die Speicherung eines Stadtnamens in einer Kundentabelle, wenn diese Stadt durch eine Postleitzahl bestimmt wird (die wiederum die Stadt bestimmt), führt zu Aktualisierungsanomalien.
Implementierungsstrategien für eine robuste Gestaltung 🛠️
Die Anwendung dieser Konzepte erfordert einen disziplinierten Ansatz während der Modellierungsphase. Die folgenden Strategien helfen, hohe Integritätsstandards zu gewährleisten.
- Explizite Namenskonventionen: Verwenden Sie klare Namen für Fremdschlüssel (z. B.
benutzer_idanstelle vonfk1) um Beziehungen während der Code-Reviews offensichtlich zu machen. - Dokumentation: Dokumentieren Sie das ERD mit Geschäftsregeln. Eine Einschränkung ohne Kontext ist schwer zu pflegen.
- Validierung vor der Erstellung: Überprüfen Sie das Design auf mögliche verwaiste Datensätze vor der Schema-Migration.
- Deaktivieren Sie Einschränkungen vorübergehend: Deaktivieren Sie Integritätsprüfungen nur während Massen-Datenladevorgänge und aktivieren Sie sie unmittelbar danach erneut, um die Datenqualität zu überprüfen.
- Audit-Protokolle: Protokollieren Sie Änderungen an kritischen Integritätsfeldern, um nachzuverfolgen, wer die Daten geändert hat und wann.
Häufige Fehler bei der Verwaltung von Einschränkungen ⚠️
Selbst mit einem soliden Plan treten Fehler auf. Die Erkennung häufiger Fehler hilft, sie zu vermeiden.
1. Zirkuläre Abhängigkeiten
Erzeugt eine Situation, in der Tabelle A von Tabelle B abhängt und Tabelle B von Tabelle A abhängt. Dies führt zu einer Blockade während der Tabellen-Erstellung.
- Lösung:Erstellen Sie Tabellen zunächst ohne die Fremdschlüsselbeschränkung, und fügen Sie die Beschränkung erst hinzu, wenn beide Tabellen existieren.
2. Überzogene Durchsetzung
Anwendung strenger Beschränkungen dort, wo Flexibilität erforderlich ist. Dies kann legitime Geschäftsvorgänge behindern.
- Lösung:Verwenden Sie nullable Fremdschlüssel für optionale Beziehungen, und führen Sie die Validierung in der Anwendungsschicht durch, falls komplexes Logik erforderlich ist.
3. Ignorieren von Weichen Löschungen
Die Verwendung einer DELETEBefehl löscht Daten dauerhaft und bricht die Referenzintegrität für historische Aufzeichnungen.
- Lösung:Implementieren Sie eine
is_deletedboolesche Kennzeichnung anstelle einer physischen Löschung für kritische historische Daten.
4. Leistungs- vs. Integritäts-Kompromisse
Übermäßige Beschränkungen können Schreibvorgänge verlangsamen. Jeder Einfügevorgang muss jede Regel überprüfen.
- Lösung:Indizieren Sie Fremdschlüssel, um Abfragen zu beschleunigen. Finden Sie ein Gleichgewicht zwischen der Notwendigkeit einer Echtzeit-Validierung und den Anforderungen an die Systemdurchsatzleistung.
Aufrechterhaltung der Integrität im Laufe der Zeit 🔄
Datenintegrität ist kein einmaliger Aufbau. Wenn sich die Geschäftsanforderungen entwickeln, muss das Schema sich anpassen, ohne bestehende Daten zu gefährden.
- Schema-Versionierung:Behandeln Sie Datenbankänderungen wie Code. Versionskontrolle ermöglicht eine Rückgängigmachung, falls eine Beschränkung das System stört.
- Migrations-Tests:Führen Sie Migrations-Skripte in einer Staging-Umgebung aus, die die Datenmengen der Produktion nachahmt.
- Regelmäßige Audits:Führen Sie Abfragen aus, um verwaiste Datensätze zu finden, die aufgrund von Fehlern oder direktem Zugriff möglicherweise durchgekommen sind.
- Sicherungsstrategien:Regelmäßige Sicherungen stellen sicher, dass im Falle einer Integritätsverletzung ein sauberer Zustand für die Wiederherstellung zur Verfügung steht.
Abschließende Gedanken zur strukturellen Strenge 🎯
Ein System mit starker Datenintegrität aufzubauen, erfordert Weitsicht und Disziplin. Das ERD dient als primäres Werkzeug, um diese Regeln an das gesamte Entwicklerteam zu kommunizieren. Durch die Durchsetzung von Beschränkungen auf Datenbankebene verringern Organisationen die Komplexität der Anwendungslogik und erhöhen das Vertrauen in ihre Daten.
Jeder hinzugefügte Constraint ist eine Schutzmaßnahme. Sie verhindern, dass das System von der richtigen Bahn abkommt. Während sie während der Entwurfsphase möglicherweise einschränkend wirken, bieten sie die notwendige Stabilität für ein langfristiges Wachstum. Die Priorisierung dieser Regeln stellt sicher, dass die Daten eine zuverlässige Ressource bleiben und keine Verpflichtung darstellen.
Die Einführung dieser Praktiken schafft eine widerstandsfähige Architektur, die in der Lage ist, den Komplexitäten der modernen Datenverarbeitung standzuhalten. Das Ergebnis ist ein System, in dem Genauigkeit inhärent ist, nicht nachträglich hinzugefügt wird.