










Die Gestaltung einer robusten Datenarchitektur erfordert mehr als nur das Verbinden von Tabellen; sie erfordert einen strengen Ansatz bezüglich Struktur und Integrität. Für Datenarchitekten ist Normalisierung kein bloßes theoretisches Übungsbeispiel aus Lehrbüchern – sie ist die Grundlage für wartbare, skalierbare und zuverlässige Datenbanksysteme. Bei der Erstellung von Entitäts-Beziehungs-Diagrammen (ERD) bestimmen die Entscheidungen im Stadium der Schema-Designphase die langfristige Gesundheit der Anwendung. Eine ordnungsgemäße Normalisierung minimiert Datenredundanz und gewährleistet logische Konsistenz und verhindert kaskadenartige Fehler im weiteren Verlauf.
Dieser Leitfaden beschreibt die wesentlichen Normalisierungsregeln, die jeder Datenarchitekt anwenden muss. Wir werden die Entwicklung von grundlegender Atomarität bis hin zu komplexen Abhängigkeiten untersuchen und analysieren, wie jede Regel die Speicherung, die Abfrageleistung und die Datenqualität beeinflusst. Durch Einhaltung dieser Prinzipien bauen Sie Systeme, die der Zeit standhalten.
Warum die Struktur bei der Schema-Design wichtig ist 📐
Bevor man sich spezifischen Formen zuwendet, ist es entscheidend, das Ziel der Normalisierung zu verstehen. Das primäre Ziel besteht darin, Daten zu isolieren, sodass Änderungen, Löschungen und Einfügungen keine Anomalien verursachen. Ohne einen strukturierten Ansatz werden Datenbanken anfällig für drei spezifische Arten von Anomalien:
-
Einfügeanomalien:Unfähigkeit, Daten über eine Entität hinzuzufügen, ohne Daten über eine andere, unzusammenhängende Entität hinzuzufügen.
-
Aktualisierungsanomalien:Die Notwendigkeit, denselben Wert in mehreren Zeilen zu aktualisieren, was die Gefahr einer Inkonsistenz birgt, falls eine Zeile übersehen wird.
-
Löschanomalien:Verlust von Daten über eine Entität, wenn Daten über eine andere gelöscht werden.
Die Normalisierung behebt diese Probleme, indem Attribute basierend auf Abhängigkeitsregeln in Tabellen organisiert werden. Diese Trennung ermöglicht es der Datenbank, als einzige Quelle der Wahrheit zu fungieren. Obwohl der Prozess mühsam erscheinen mag, führt die Reduzierung des Wartungsaufwands und der Risiken von Datenkorruption zu einer entscheidenden Investition.
Die Grundlage: Erste Normalform (1NF) 🧱
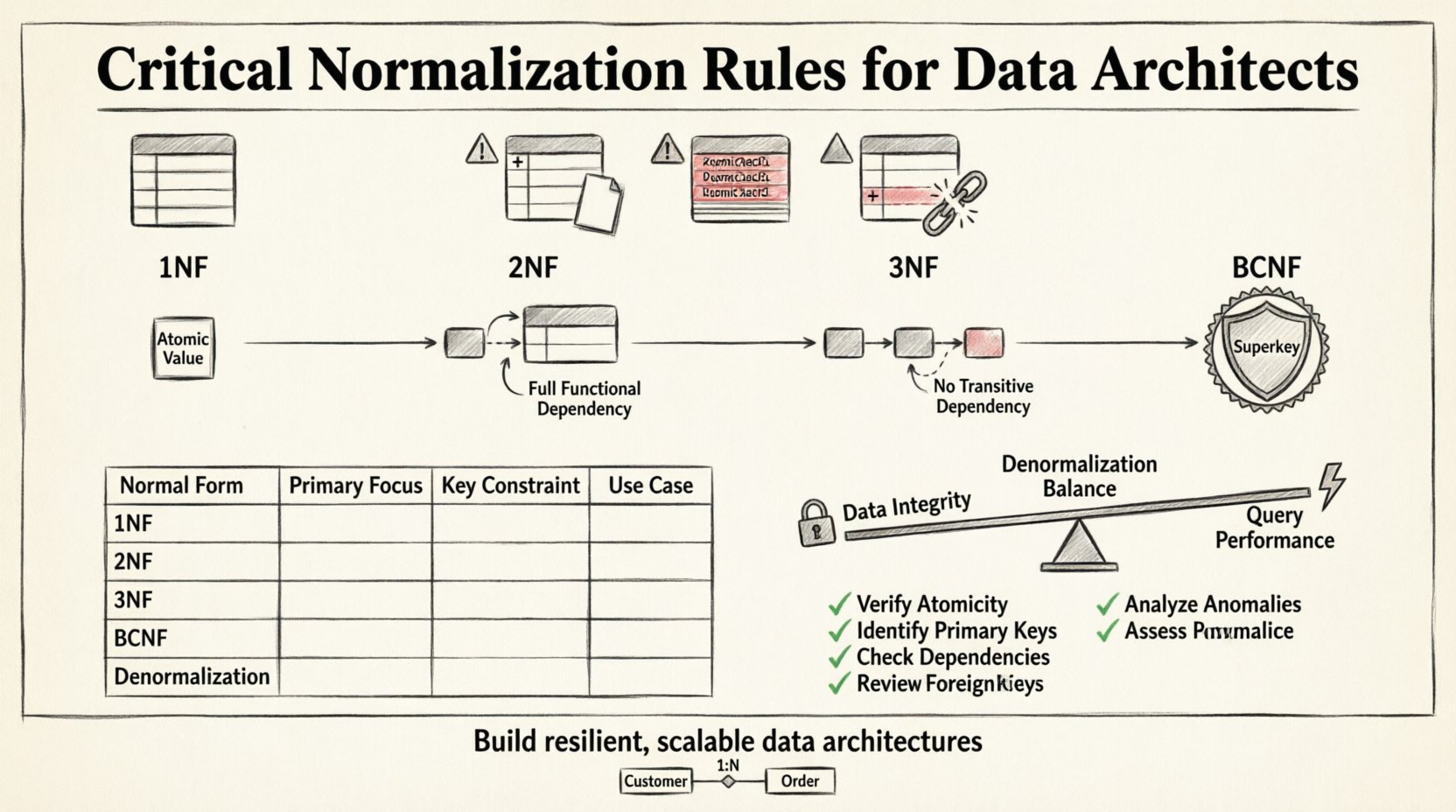
Der erste Schritt bei der Normalisierung ist die Erreichung der Ersten Normalform. Dies ist die Basisanforderung für jede relationale Datenbank. Eine Tabelle befindet sich in 1NF, wenn zwei Bedingungen erfüllt sind: Sie enthält nur atomare Werte, und jeder Spalte enthält pro Zeile nur einen einzigen Wert. Es sollten keine sich wiederholenden Gruppen oder Arrays innerhalb einer einzigen Zelle vorhanden sein.
Verstöße gegen die 1NF treten häufig auf, wenn Entwickler versuchen, Listen in einer einzigen Spalte zu speichern, beispielsweise mehrere Telefonnummern in einem Feld, getrennt durch Kommas. Dieser Ansatz erschwert Abfragen und Indizierung. Stattdessen sollte jeder Datenbestand in einer eigenen Zeile existieren.
-
Atomarität: Stellen Sie sicher, dass jede Spalte einen einzelnen, nicht weiter teilbaren Wert enthält.
-
Eindeutige Zeilen: Jede Zeile muss eindeutig sein, was oft durch einen Primärschlüssel gewährleistet wird.
-
Spaltenreihenfolge: Die Reihenfolge der Spalten sollte die Bedeutung der Daten nicht beeinflussen.
Betrachten Sie eine Kunden-Tabelle. Wenn ein Kunde drei E-Mail-Adressen hat, erstellen Sie nicht drei E-Mail-Spalten. Erstellen Sie stattdessen eine separate Tabelle „E-Mail“, die über einen Fremdschlüssel verknüpft ist. Diese Struktur stellt sicher, dass das Hinzufügen einer vierten E-Mail keine Änderung des Tabellenschemas erfordert.
Beseitigung partieller Abhängigkeiten (2NF) ⚖️
Sobald eine Tabelle in 1NF ist, ist der nächste Schritt die Überprüfung auf partielle Abhängigkeiten. Eine Tabelle befindet sich in der Zweiten Normalform, wenn sie bereits in 1NF ist und jeder Nicht-Schlüssel-Attribut vollständig vom Primärschlüssel abhängt. Diese Regel wird besonders relevant, wenn man mit zusammengesetzten Primärschlüsseln arbeitet.
Ein zusammengesetzter Primärschlüssel besteht aus zwei oder mehr Spalten. In diesem Szenario tritt eine partielle Abhängigkeit auf, wenn ein Nicht-Schlüssel-Attribut nur auf einen Teil des zusammengesetzten Schlüssels angewiesen ist. Zum Beispiel in einer Tabelle zur Verfolgung von Bestellpositionen, bei der der Primärschlüssel (Bestell-ID, Produkt-ID) ist, könnte eine Spalte für „Produktname“ nur von „Produkt-ID“ abhängen, nicht von der Kombination beider.
-
Vollständige Abhängigkeit: Stellen Sie sicher, dass jedes Nicht-Schlüssel-Feld auf den gesamten Primärschlüssel angewiesen ist.
-
Trennung der Verantwortlichkeiten: Verschieben Sie Attribute, die nur auf einen Teil des Schlüssels angewiesen sind, in eine neue Tabelle.
-
Integritätsprüfungen: Stellen Sie sicher, dass kein Attribut ohne den vollständigen Schlüssel abgeleitet werden kann.
Durch Verschieben von „ProductName“ in eine eigene Tabelle, die über „ProductID“ verknüpft ist, eliminieren Sie das Risiko, dass der Name in einer Bestellung geändert wird, aber nicht in einer anderen. Dies reduziert den Speicherbedarf und stellt die Konsistenz über alle Bestellaufzeichnungen sicher.
Beseitigung transitiver Abhängigkeiten (3NF) 🔗
Die Dritte Normalform geht die Struktur weiter, indem sie transitive Abhängigkeiten anspricht. Eine Tabelle befindet sich in 3NF, wenn sie in 2NF ist und alle Nicht-Schlüsselattribute nicht transitiv vom Primärschlüssel abhängen. Im Wesentlichen bedeutet dies, dass Nicht-Schlüsselspalten nicht von anderen Nicht-Schlüsselspalten abhängen sollten.
Stellen Sie sich eine Tabelle mit EmployeeID, EmployeeName, DepartmentID und DepartmentName vor. Wenn EmployeeName DepartmentName bestimmt, liegt eine transitive Abhängigkeit vor. Wenn ein Mitarbeiter die Abteilung wechselt, könnte der DepartmentName in der Mitarbeiter-Tabelle veraltet werden, wenn er nicht korrekt aktualisiert wird. Um dies zu beheben, sollte die Abteilungstabelle getrennt werden.
-
Nur direkte Abhängigkeiten:Attribute sollten sich direkt auf den Schlüssel beziehen, nicht auf andere Attribute.
-
Logische Gruppierung:Gruppieren Sie verwandte Attribute, die einen gemeinsamen Bestimmungsfaktor haben, in eigene Entitäten.
-
Fremdschlüssel:Verwenden Sie Fremdschlüssel, um die getrennten Tabellen miteinander zu verknüpfen.
Diese Trennung stellt sicher, dass Abteilungsinformationen nur einmal gespeichert werden. Wenn der Abteilungsname geändert wird, wird er an einer Stelle aktualisiert, und alle Mitarbeiterdatensätze spiegeln die Änderung automatisch über die Beziehung wider.
Wenn 3NF nicht ausreicht: BCNF und darüber hinaus 🚀
Während 3NF die meisten Standarddesign-Szenarien abdeckt, gibt es Randfälle, in denen die strenge 3NF unzureichend ist. Die Boyce-Codd-Normalform (BCNF) ist eine strengere Version von 3NF, die Fälle behandelt, bei denen mehrere Kandidatenschlüssel vorhanden sind. BCNF erfordert, dass für jede funktionale Abhängigkeit X → Y, X ein Superkey sein muss.
Stellen Sie sich eine Situation vor, in der ein Schüler mehrere Lehrer haben kann und ein Lehrer mehrere Fächer unterrichten kann. Wenn der Primärschlüssel (Student, Fach) ist und ein Lehrer basierend auf dem Fach zugewiesen wird, könnten Sie Situationen erleben, in denen die Abhängigkeitslogik komplex überlappend ist. BCNF stellt sicher, dass keine Spalte durch eine Menge von Spalten bestimmt wird, die kein Kandidatenschlüssel ist.
-
Superkey-Anforderung:Der Bestimmungsfaktor in jeder Abhängigkeit muss ein Superkey sein.
-
Komplexe Beziehungen:Behandeln Sie viele-zu-viele-Beziehungen mit Zwischentabellen.
-
Überhead-Berücksichtigung:Höhere Normalformen können die Komplexität von Joins erhöhen.
Die Vierte Normalform (4NF) und die Fünfte Normalform (5NF) behandeln mehrwertige Abhängigkeiten und Join-Abhängigkeiten. Diese sind in allgemeinen Geschäftsanwendungen selten, aber entscheidend bei spezialisierten Data-Warehousing- oder wissenschaftlichen Datenmodellierungen.
Die Kunst der strategischen Denormalisierung ⚡
Die Normalisierung ist nicht immer das Endziel. In einigen Hochleistungsumgebungen kann strenge Normalisierung zu übermäßigen Joins führen, die die Abfragegeschwindigkeit beeinträchtigen. Hier kommt die strategische Denormalisierung ins Spiel. Die Denormalisierung beinhaltet das Hinzufügen redundanter Daten in eine Datenbank, um die Leseleistung zu optimieren.
Dies sollte jedoch niemals willkürlich erfolgen. Es erfordert ein klares Verständnis der Abwägungen zwischen Leseleistung und Schreibkomplexität. Wenn Leseoperationen deutlich die Schreiboperationen überwiegen, könnte Redundanz gerechtfertigt sein.
-
Lese-lastige Workloads:Wenn Berichterstattung die primäre Funktion ist, kann die Denormalisierung die Abfragezeit reduzieren.
-
Caching-Ebenen:Verwenden Sie Caching auf Anwendungsebene, bevor Sie die Datenbankschema ändern.
-
Risiken für Datenkonsistenz: Beachten Sie, dass redundantes Datenmaterial aus dem Takt geraten kann.
-
Schreibkosten:Jede Schreiboperation muss alle redundanten Kopien der Daten aktualisieren.
Ein verbreiteter Ansatz besteht darin, Zusammenfassungstabellen für Berichts-Dashboards zu de-normalisieren, während die zentralen transaktionalen Daten in 3NF erhalten bleiben. Dieser hybride Ansatz stellt ein Gleichgewicht zwischen Integrität und Leistung her.
Vergleich der Normalformen
|
Normalform |
Primäres Ziel |
Schlüsselbeschränkung |
Typischer Anwendungsfall |
|---|---|---|---|
|
1NF |
Atomare Werte |
Keine sich wiederholenden Gruppen |
Anfängliche Schema-Design |
|
2NF |
Vollständige Abhängigkeit |
Keine teilweisen Abhängigkeiten von zusammengesetzten Schlüsseln |
Komplexe Schlüssel |
|
3NF |
Transitive Abhängigkeit |
Nicht-Schlüssel-Attribute hängen nur vom Schlüssel ab |
Allgemeine Geschäftslogik |
|
BCNF |
Super-Schlüssel |
Der Determinant muss ein Super-Schlüssel sein |
Komplexe Kandidatenschlüssel |
Eine praktische Prüfliste für Datenarchitekten ✅
Um sicherzustellen, dass Ihr ERD den Branchenstandards entspricht, durchlaufen Sie diese Prüfliste während der Entwurfsphase. Dieser Prozess hilft, potenzielle Probleme zu erkennen, bevor Code geschrieben wird.
-
Überprüfen der Atomarität: Stellen Sie sicher, dass keine Spalte mehrere unterschiedliche Werte enthält.
-
Identifizieren Sie Primärschlüssel: Stellen Sie sicher, dass jede Tabelle einen eindeutigen Bezeichner hat.
-
Abhängigkeiten prüfen: Zeichnen Sie auf, wie sich jede Spalte auf den Primärschlüssel bezieht.
-
Fremdschlüssel überprüfen: Stellen Sie sicher, dass Beziehungen explizit definiert sind.
-
Anomalien analysieren: Simulieren Sie Einfüge-, Aktualisierungs- und Löschvorgänge im Geiste.
-
Leistung bewerten: Bestimmen Sie, ob 3NF ausreichend ist oder ob eine De-Normalisierung erforderlich ist.
-
Einschränkungen dokumentieren: Definieren Sie Regeln für die Dateneingabe und Validierung klar.
-
Für Wachstum planen: Berücksichtigen Sie, wie das Schema mit steigendem Datenvolumen umgehen wird.
Durch die Einhaltung dieser Schritte erstellen Sie ein Schema, das widerstandsfähig gegenüber Veränderungen ist. Die Datenarchitektur ist nicht statisch; sie entwickelt sich mit den geschäftlichen Anforderungen. Eine gut normalisierte Grundlage erleichtert diese Entwicklung, da Änderungen an einem Teil des Systems nicht unvorhersehbar durch den Rest des Systems wirken.
Denken Sie daran, dass Normalisierung ein Werkzeug ist, kein Gesetz. Während 3NF der Standard für transaktionale Systeme ist, könnten die spezifischen Anforderungen Ihrer Anwendung Abweichungen erfordern. Das Ziel ist immer die Datenintegrität und die Systemeffizienz. Balancieren Sie diese beiden Faktoren sorgfältig, und Ihr ERD wird als solide Grundlage für das gesamte Anwendungssystem dienen.
Durch die Übernahme dieser kritischen Normalisierungsregeln können Sie Systeme entwickeln, die nicht nur heute funktionsfähig sind, sondern auch für die Zukunft anpassungsfähig. Konzentrieren Sie sich auf die Beziehungen zwischen Datenpunkten, und die Struktur ergibt sich von selbst.