











In modernen Datenarchitekturen bestimmt die Geschwindigkeit, mit der Informationen abgerufen werden, oft die Nutzbarkeit einer Anwendung. Während Hardware-Upgrades und Caching-Strategien eine bedeutende Rolle spielen, liegt die Grundlage der Leistungsfähigkeit in der Datenstruktur selbst. Genauer gesagt, bestimmt die Gestaltung von Entitäts-Beziehungs-Modellen (ERMs), wie effizient eine Datenbankengine Daten durchlaufen, verknüpfen und aggregieren kann. Ein optimiertes Schema organisiert Informationen nicht nur; es führt den Abfrage-Optimierer gezielt zu schnelleren Ausführungswege. 📉
Dieser Leitfaden untersucht die technischen Mechanismen hinter der Schema-Design und deren direkten Zusammenhang mit der Abfrageleistung. Wir werden analysieren, wie Normalisierungsstufen, Beziehungskardinalitäten und Indizierungsstrategien innerhalb des Abfrage-Ausführungsplans miteinander interagieren. Durch das Verständnis dieser Dynamiken können Entwickler und Datenbankarchitekten Systeme aufbauen, die skalieren, ohne Integrität oder Geschwindigkeit zu beeinträchtigen.
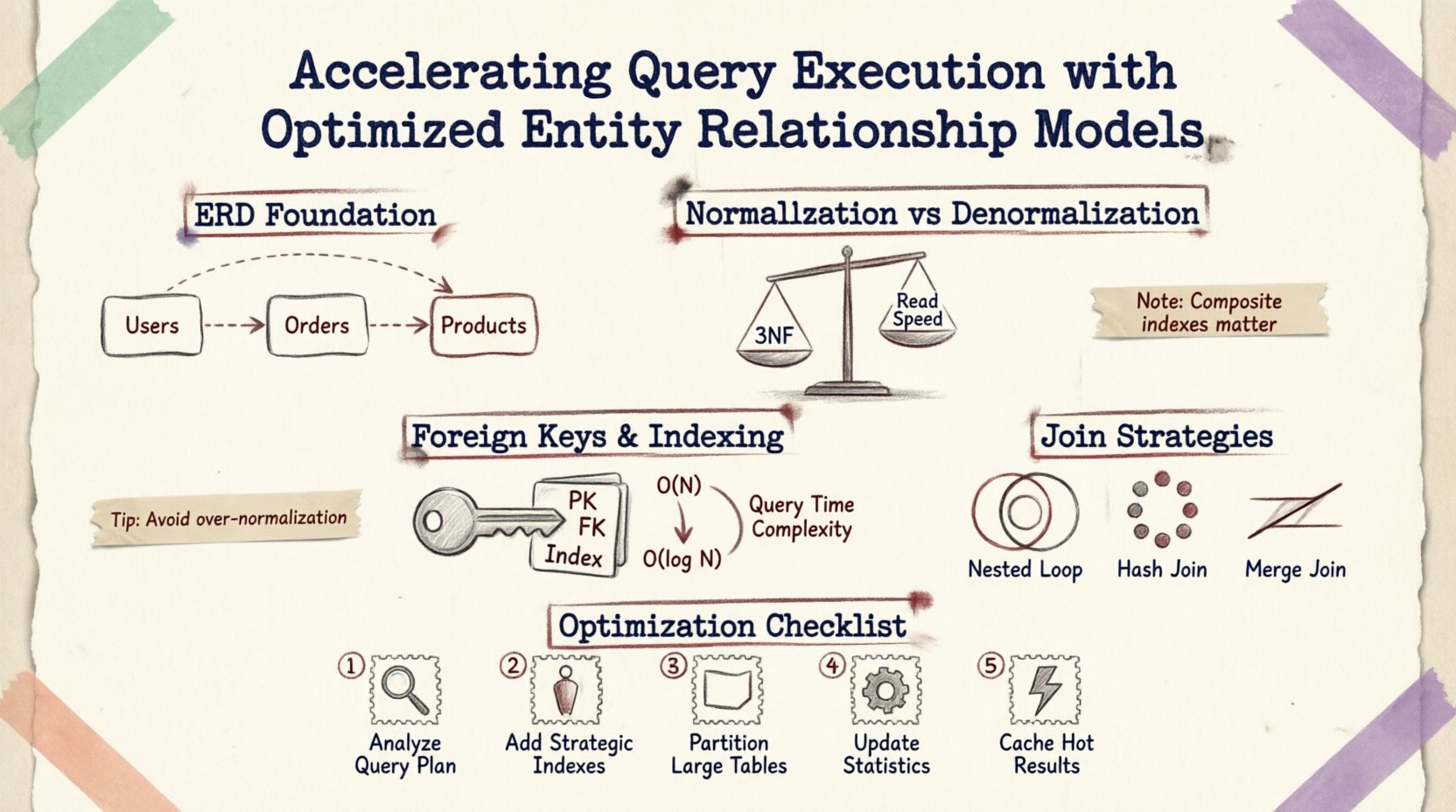
Das Fundament verstehen: ERDs und Leistungsfähigkeit 🗃️
Ein Entitäts-Beziehungs-Diagramm ist mehr als eine visuelle Hilfestellung für die Dokumentation; es ist eine Bauplanung für die physische Speicher- und Abruflogik. Jede Linie, die zwischen Tabellen gezogen wird, steht für eine Fremdschlüssel-Beschränkung, eine Join-Operation oder eine Datenintegritätsregel. Wenn eine Abfrage eingereicht wird, interpretiert die Datenbankengine diese Beziehungen, um einen Ausführungsplan zu erstellen.
Betrachten Sie eine einfache Abfrage, die Benutzerbestellungen und Produktinformationen anfordert. Die Engine muss:
- Die Tabelle
BenutzerTabelle. - Der Fremdschlüssel führt zur Tabelle
BestellungenTabelle. - Verknüpfen der Tabelle
BestellpositionenTabelle. - Erreichen der Tabelle
ProdukteTabelle über eine weitere Beziehung.
Jeder Schritt erfordert I/O-Operationen und CPU-Zyklen. Wenn die Beziehungen schlecht definiert sind, kann die Engine auf vollständige Tabellen-Scans oder verschachtelte Schleifen-Verknüpfungen zurückgreifen, die die Leistung exponentiell verschlechtern. Die Optimierung des ERDs verringert die Distanz, die Daten von der Festplatte zum Speicher zurücklegen müssen.
Normalisierung vs. Denormalisierung: Das Gleichgewicht finden ⚖️
Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Obwohl sie für Konsistenz unerlässlich ist, kann eine übermäßige Normalisierung die Daten über viele kleine Tabellen verteilen, was komplexe Verknüpfungen erfordert, die Lese-lastige Operationen verlangsamen.
Die Kosten der tiefen Normalisierung
Wenn ein Schema auf die Dritte Normalform (3NF) normalisiert ist, werden die Daten in ihrem atomarsten Zustand gespeichert. Dies minimiert den Speicherplatz und Aktualisierungsanomalien. Allerdings erfordert die Abfrage von zusammenhängenden Daten oft das Durchlaufen mehrerer Fremdschlüssel.
- Join-Aufwand: Jede zusätzliche Tabelle in einer Join-Kette erhöht die Komplexität des Abfrageplans.
- Sperrkonflikte:Der Zugriff auf mehrere Tabellen erhöht die Wahrscheinlichkeit von Zeilen-Sperrkonflikten.
- CPU-Nutzung: Die Datenbankengine muss Ergebnismengen aus unterschiedlichen Tabellen zusammenführen.
Wann man denormalisieren sollte
Die Denormalisierung führt Redundanz ein, um die Leseleistung zu optimieren. Dies ist oft in der analytischen Verarbeitung oder in Umgebungen mit hohem Datenverkehr für Berichterstattung notwendig.
- Leseintensive Workloads: Wenn Schreibvorgänge im Vergleich zu Lesevorgängen selten sind, spart die Hinzufügung einer denormalisierten Spalte Join-Operationen.
- Vorab berechnete Aggregationen: Speichern von Summen (z. B.
total_order_value) in der Benutzertabelle vermeidet die Berechnung von Summen bei jeder Anfrage. - Horizontale Partitionierung: Die Zusammenführung häufig abgerufener Daten verbessert die Cache-Lokalität.
Allerdings erfordert die Denormalisierung eine sorgfältige Verwaltung, um Dateninkonsistenzen zu vermeiden. Die Anwendungslogik muss sicherstellen, dass redundant gespeicherte Daten aktualisiert werden, sobald sich die Quelldaten ändern.
Fremdschlüssel und Indexstrategie 🔑
Fremdschlüsselbeschränkungen gewährleisten die Referenzintegrität, bringen aber eine Leistungskosten mit sich. Die Datenbank muss überprüfen, ob ein Wert in einer Tabelle auch in einer anderen Tabelle vorhanden ist, bevor ein Einfügen oder Aktualisieren erlaubt wird. Die Optimierung der Indexierung dieser Schlüssel ist entscheidend.
Indexierung von Fremdschlüsseln
Standardmäßig werden Primärschlüssel automatisch indiziert. Fremdschlüssel erfordern jedoch oft explizite Indizes, um Join-Operationen zu beschleunigen. Ohne einen Index in einer Fremdschlüsselspalte:
- Die Datenbank muss eine vollständige Tabellenabfrage der Kindtabelle durchführen, um passende Zeilen zu finden.
- Join-Operationen werden erheblich langsamer, insbesondere wenn die Tabellengrößen in Millionen von Zeilen wachsen.
- Referenzintegritätsprüfungen während der Löschung werden kostspielig.
Ein ordnungsgemäß indizierter Fremdschlüssel ermöglicht es der Datenbank, einen Index-Suchvorgang statt einer Abfrage durchzuführen, wodurch die Komplexität von O(N) auf O(log N) reduziert wird.
Komposite Indizes für Beziehungen
Wenn mehrere Spalten eine Beziehung definieren, kann ein komposites Index effektiver sein als einzelne Indizes. Zum Beispiel, wenn eine Abfrage nach user_id und created_at innerhalb einer Auftrags-Tabelle filtert, sorgt ein komposites Index auf beiden Spalten dafür, dass die Engine die Daten finden kann, ohne unzusammenhängende Datensätze zu scannen.
Join-Strategien und Ausführungspläne 🔍
Die Struktur des ERD beeinflusst, welche Join-Algorithmen der Abfrage-Optimierer wählt. Das Verständnis dieser Mechanismen hilft bei der Gestaltung von Schemata, die effiziente Join-Typen bevorzugen.
| Join-Typ | Am besten geeignet, wenn | Leistungseinfluss |
|---|---|---|
| Verschachtelter Schleifen-Join | Kleine Ergebnismengen oder sehr selektive Prädikate | Schnell bei kleinem Datenvolumen; langsam bei großen Scans |
| Hash-Join | Große Tabellen ohne Indizes | Speicherintensiv; gut für unsortierte Daten |
| Merge-Join | Sortierte Eingaben an den Verknüpfungsschlüsseln | Sehr schnell, wenn die Daten bereits sortiert sind |
Die Gestaltung des ERD, um sortierte Eingaben oder indizierte Abfragen zu unterstützen, kann den Optimierer dazu veranlassen, schnellere Join-Methoden zu wählen. Beispielsweise kann die Sicherstellung, dass Verknüpfungsschlüssel Teil eines gruppierten Indexes sind, Merge-Joins erleichtern.
Häufige Fehler bei der Schema-Design 🚫
Selbst erfahrene Architekten begehen Fehler, die die Abfragegeschwindigkeit beeinflussen. Die frühzeitige Erkennung dieser Muster verhindert kostspielige Umgestaltungen später.
- Verkettete Fremdschlüssel:Erstellen einer Kette von Beziehungen, bei der Tabelle A auf B verweist, B auf C und C auf D. Abfragen, die alle vier Tabellen verknüpfen, werden tief verschachtelt und langsam.
- Variabel lange Zeichenketten: Verwendung von
VARCHARfür Schlüssel, die immer feste Länge haben, verschwendet Speicherplatz und verlangsamt Zeilenvergleiche. - Viele-zu-Viele ohne Zwischentabellen: Versuchen, mehrere IDs in einer einzigen Spalte zu speichern (z. B. durch Kommas getrennt), verhindert eine ordnungsgemäße Indizierung und Normalisierung.
- Implizite Umwandlungen:Die Definition von Datentypen, die zwischen Eltern- und Kindtabellen nicht übereinstimmen, zwingt die Engine, Werte zur Laufzeit umzuwandeln, wodurch die Nutzung von Indizes verhindert wird.
Praktische Schritte zur Optimierung 🛠️
Um die Abfrageausführung zu verbessern, ohne das gesamte System neu zu schreiben, folgen Sie diesen strukturierten Schritten:
- Analyse von Abfragemustern: Überprüfen Sie die häufigsten Leseoperationen. Identifizieren Sie, welche Tabellen am häufigsten verknüpft werden.
- Überprüfung der Indexnutzung: Prüfen Sie auf fehlende Indizes bei Fremdschlüsseln oder häufig gefilterten Spalten.
- Verbesserung der Kardinalität: Stellen Sie sicher, dass Beziehungen korrekt modelliert sind (Eins-zu-Eins vs. Eins-zu-Viele). Falsche Kardinalität kann zu unnötigen Joins führen.
- Große Tabellen partitionieren: Wenn eine Tabelle Millionen von Zeilen überschreitet, sollten Sie eine Partitionierung nach Datum oder Region in Betracht ziehen, um die Datenmenge zu begrenzen, die pro Abfrage durchsucht wird.
- Sperrüberwachung: Verwenden Sie Überwachungstools, um lang laufende Abfragen zu identifizieren, die Sperrungen halten, die oft durch ineffizientes Durchlaufen des Schemas verursacht werden.
Speicher- und Speicherplatzüberlegungen 💾
Die physische Anordnung der Daten spielt ebenfalls eine Rolle. Datenbank-Engines speichern Daten in Seiten. Wenn verwandte Zeilen physisch nahe beieinander gespeichert sind, sind weniger Festplattenlesungen erforderlich, um ein Datenset zu laden.
- Clustering:Die Organisation der Daten nach einem gemeinsamen Schlüssel kann Bereichssuchen verbessern.
- Spalten-Speicher im Vergleich zu Zeilen-Speicher:Für analytische Abfragen kann ein spaltenbasiertes Speichermodell eine bessere Komprimierung und schnellere Aggregation bieten als herkömmliche zeilenbasierte Modelle.
- Caching:Entwerfen Sie Schemata, die eine effektive Caching von gesamten Ergebnissätzen anstelle einzelner Zeilen ermöglichen.
Abschließende Gedanken zur Schemaversionierung 🔄
Die Gestaltung eines Schemas ist keine einmalige Aufgabe. Wenn sich die Anforderungen der Anwendung ändern, muss das Datenmodell sich weiterentwickeln. Regelmäßige Überprüfungen der Datenbankstruktur stellen sicher, dass die Leistung konstant bleibt. Die Dokumentation des Entity-Relationship-Modells sollte zusammen mit dem Codebase gepflegt werden, um nachzuverfolgen, wie Änderungen die Systemleistung beeinflussen.
Indem Sie sich auf die strukturelle Integrität und die logischen Beziehungen innerhalb der Daten konzentrieren, schaffen Sie eine Grundlage, die eine Hochgeschwindigkeitsabfrageausführung unterstützt. Das Ziel ist nicht, ein statisches System zu bauen, sondern eine flexible Architektur, die sich an die Last anpasst, ohne die Geschwindigkeit zu opfern, die die Benutzer erwarten. 📊
Die Optimierung des Entity-Relationship-Modells ist eine technische Disziplin, die Datenbanktheorie mit praktischer Ingenieurkunst verbindet. Sie erfordert Geduld, Analyse und ein klares Verständnis dafür, wie der zugrundeliegende Engine Anfragen verarbeitet. Mit der richtigen Herangehensweise werden Leistungsprobleme beherrschbar, und die Datenabrufung wird nahtlos.