











Entitäts-Beziehungs-Diagramme (ERDs) dienen als Bauplan für die Datenbankarchitektur. Sie definieren, wie Daten innerhalb eines Systems strukturiert, gespeichert und abgerufen werden. Wenn diese Diagramme fehlerhaft sind, haben die Folgen weit über die Entwicklungsphase hinaus. Fehler in Produktionsumgebungen können zu Datenkorruption, Leistungsbremsschwellen und erheblichen finanziellen Verlusten führen. Das Verständnis der häufigen Fallstricke ist entscheidend, um die Systemintegrität zu gewährleisten.
Viele Teams hetzen durch die Modellierungsphase und setzen Geschwindigkeit vor Genauigkeit. Diese Eile führt oft zu Schema-Problemen, die schwer zu beheben sind, sobald Daten fließen. Eine robuste Gestaltung erfordert sorgfältige Überlegungen zu Beziehungen, Datentypen und Einschränkungen. Im Folgenden untersuchen wir die häufigsten Gestaltungsfehler und ihre technischen Auswirkungen.
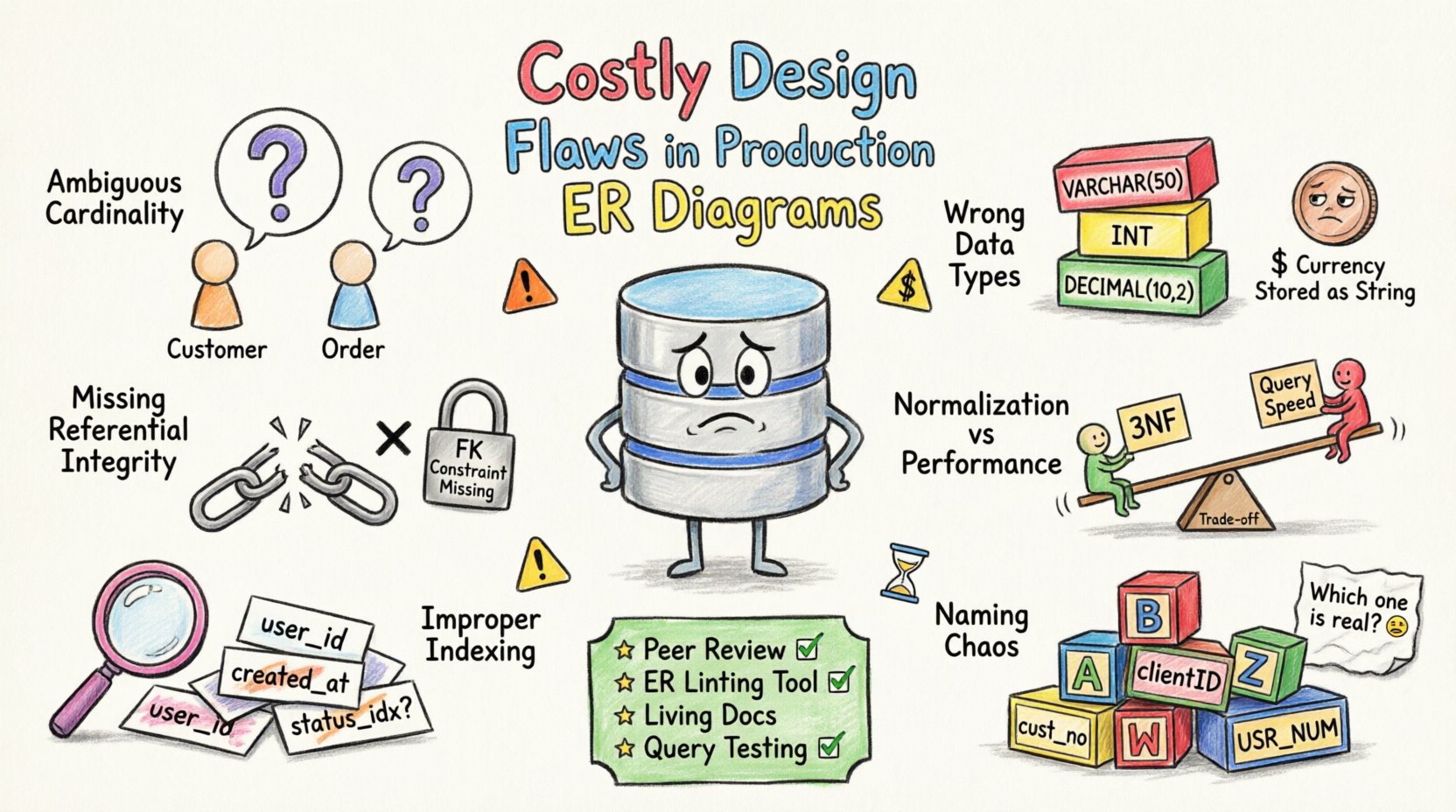
1. Mehrdeutige Kardinalität und Beziehungen 🔗
Die Kardinalität definiert die numerische Beziehung zwischen Entitäten. Falsche Kardinalität führt zu logischen Fehlern bei der Datenabruf- und Speicherung. Ein häufiger Fehler ist die Annahme einer ein-zu-eins-Beziehung, obwohl eine ein-zu-viele-Situation vorliegt.
- Auslassung von Many-to-Many-Beziehungen:Das Auslassen der Erstellung einer Verbindungstabelle für viele-zu-viele-Beziehungen zwingt zur Datenverdoppelung oder zu komplexen Join-Abfragen.
- Undefinierte Fremdschlüssel:Ohne explizite Fremdschlüssel kann die Datenbank die Referenzintegrität nicht gewährleisten und erlaubt so verwaiste Datensätze.
- Optional vs. Obligatorisch:Die Falschklassifizierung einer erforderlichen Beziehung als optionale führt zu Nullwerten an Stellen, an denen Daten erwartet werden.
Betrachten wir beispielsweise einen Kunden und eine Bestellung. Wenn das Diagramm suggeriert, dass ein Kunde ohne Bestellung existieren kann, dies aber die Anwendungslogik erfordert, speichert die Datenbank unvollständige Profile. Diese Diskrepanz führt zu Anwendungsabstürzen oder inkonsistenten Berichten.
2. Inkonsistente Auswahl von Datentypen 📊
Datentypen bestimmen, wie Informationen gespeichert und verarbeitet werden. Die falsche Auswahl verbraucht unnötigen Speicherplatz oder begrenzt den Wertebereich. Genauigkeitsprobleme entstehen häufig, wenn Gleitkommazahlen für Währungen verwendet werden.
- Integer-Überlauf:Die Verwendung kleiner Ganzzahlen für Identifikatoren kann zu Überlauffehlern führen, wenn die Datensammlung wächst.
- Textlänge:Die Verwendung von fester Länge für Zeichenfelder verschwendet Speicherplatz bei variabler Datengröße.
- Datumspräzision:Das Speichern von Daten ohne Zeitzone führt zu Synchronisationsproblemen in verteilten Systemen.
Die Wahl eines generischen Textfeldes für Telefonnummern ist ein weiterer häufiger Fehler. Dadurch können ungültige Zeichen in das System gelangen und die Validierungslogik später erschweren. Numerische Felder sollten für Berechnungen verwendet werden, Textfelder nur für alphanumerische Daten.
3. Fehlende Referenzintegritätsbeschränkungen 🔒
Die Referenzintegrität stellt sicher, dass die Beziehungen zwischen Tabellen konsistent bleiben. Ohne diese Beschränkungen verlässt sich die Datenbank auf Anwendungscode, um die Datenkorrektheit zu gewährleisten, was anfällig für menschliche Fehler ist.
- Keine Kaskadenregeln:Das Löschen eines übergeordneten Datensatzes ohne Kaskadenregeln lässt untergeordnete Datensätze im Datenbankbestand hängen.
- Fehlende Beschränkungen:Die Abhängigkeit von Validierung auf Anwendungsebene statt von Datenbankbeschränkungen ist unzureichend.
- Weiche Löschungen:Die unsachgemäße Handhabung gelöschter Datensätze erzeugt Unordnung und verlangsamt die Abfrageleistung.
Wenn Beschränkungen fehlen, hängt die Datenintegrität vollständig von den Anwendungsentwicklern ab. Wenn ein Fehler einen direkten Schreibzugriff auf die Datenbank erlaubt, werden Inkonsistenzen dauerhaft. Dies ist eine Hauptursache für Datenkorruption in langlaufenden Produktionsumgebungen.
4. Normalisierung im Vergleich zu Leistungsabwägungen ⚖️
Die Normalisierung reduziert Redundanz, kann aber die Komplexität von Abfragen erhöhen. Eine Über-Normalisierung führt zu übermäßigen Joins, während eine Unter-Normalisierung Aktualisierungsanomalien verursacht. Die richtige Balance zu finden, ist entscheidend für die Leistung.
- Dritte Normalform (3NF): Häufig ideal für transaktionale Systeme, erfordert aber möglicherweise eine De-Normalisierung bei Lese-lastigen Workloads.
- De-Normalisierung: Die Einführung von Redundanz zur Leistungssteigerung muss dokumentiert werden, um Aktualisierungskonflikte zu vermeiden.
- Abfragekomplexität: Stark normalisierte Schemata erfordern komplexe Joins, die die Datenbankengine belasten.
Teams normalisieren oft bis ins Extreme, um Datenreinheit zu gewährleisten, und ignorieren dabei die Kosten, die durch das Verknüpfen mehrerer Tabellen entstehen. In Umgebungen mit hohem Datenverkehr führt dies zu langen Antwortzeiten. Strategische De-Normalisierung kann die Leseleistung verbessern, vorausgesetzt, die Schreiboperationen werden korrekt verwaltet.
5. Falsche Indizierungsstrategie 🏷️
Indizes beschleunigen die Datenabrufung, verlangsamen aber Schreibvorgänge. Ein fehlerhaftes ERD berücksichtigt oft nicht, wie die Daten abgefragt werden. Dies führt zu vollständigen Tabellen-Scans und hoher Latenz.
- Fehlende Fremdschlüssel-Indizes: Joins auf nicht indizierten Spalten sind rechnerisch kostspielig.
- Über-Indizierung: Zu viele Indizes erhöhen die Schreiblatenz und die Speicheranforderungen.
- Reihenfolge in zusammengesetzten Indizes: Falsche Spaltenreihenfolge in zusammengesetzten Indizes macht sie unwirksam.
Ein Index auf einer häufig abgefragten Spalte ist Standardpraxis. Doch die Ignorierung der Abfrage-Muster während der Entwurfsphase führt zu ineffizienten Zugriffswegen. Regelmäßige Überprüfung der Abfrage-Ausführungspläne ist notwendig, um die Indizierungsstrategie anzupassen.
6. Chaos bei Namenskonventionen 🏷️
Konsistente Namenskonventionen sind für die Wartbarkeit entscheidend. Inkonsistente Tabellen- und Spaltennamen machen das Schema schwer verständlich und zu ändern.
- Gemischte Groß- und Kleinschreibung: Die Verwendung von camelCase an einigen Stellen und snake_case an anderen führt zu Verwirrung.
- Zweideutige Abkürzungen: Kurze Namen wie „cust“ oder „ord“ sind für neue Teammitglieder unklar.
- Reservierte Schlüsselwörter: Die Verwendung reservierter Wörter als Tabellennamen verursacht Syntaxfehler in Abfragen.
Klare Namensgebung reduziert die kognitive Belastung für Entwickler und Datenbankadministratoren. Sie erleichtert auch die automatisierte Generierung von Dokumentation und verringert die Wahrscheinlichkeit von Tippfehlern in SQL-Anweisungen.
Auswirkungsanalyse häufiger Fehler
| Designfehler | Technischer Einfluss | Geschäftskosten |
|---|---|---|
| Fehlende Fremdschlüssel | Verwaiste Datensätze, Dateninkonsistenzen | Datenverlust, Verstöße gegen Compliance-Vorgaben |
| Falsche Datentypen | Speicherverschwendung, Berechnungsfehler | Finanzielle Abweichungen, Berichterstattungsfehler |
| Über-Normalisierung | Langsame Abfrageleistung, hohe Latenz | Langsame Benutzererfahrung, verlorene Einnahmen |
| Fehlende Indizes | Vollständige Tabellen Scans, Datenbank-Sperrkonflikte | Systemausfall, schlechte Skalierbarkeit |
| Schlechte Benennung | Hoher Wartungsaufwand, hohe Fehlerquote | Verlängerte Entwicklungszeit, Fehler |
Präventionsstrategien 🛡️
Die Verhinderung dieser Fehler erfordert einen disziplinierten Ansatz bei der Datenbankgestaltung. Die folgenden Schritte helfen, Risiken vor der Bereitstellung zu minimieren.
- Peer-Reviews: Führen Sie obligatorische Schema-Reviews durch, bevor Änderungen gemergt werden.
- Automatisiertes Linting: Verwenden Sie Werkzeuge, um Einhaltung von Benennungskonventionen und strukturellen Standards zu überprüfen.
- Dokumentation: Pflegen Sie aktuelle ERD-Diagramme, die das tatsächliche Schema widerspiegeln.
- Testen: Führen Sie Schema-Validierungstests in der Staging-Umgebung vor der Produktion durch.
Die Einführung eines Versionskontrollprozesses für Datenbankschemata stellt sicher, dass Änderungen nachvollziehbar und rückgängig gemacht werden können. Dies ermöglicht es Teams, festzustellen, wann ein Fehler eingeführt wurde, und ihn gegebenenfalls rückgängig zu machen. Die Zusammenarbeit zwischen Entwicklern und Architekten ist entscheidend, um Probleme frühzeitig zu erkennen.
Langfristige Wartungsaspekte 🔄
Datenbankschemata entwickeln sich im Laufe der Zeit weiter. Ein heute funktionierendes Design mag zukünftigen Anforderungen nicht mehr entsprechen. Regelmäßige Audits helfen, technischen Schulden und veraltete Muster zu erkennen.
- Schema-Drift: Überwachen Sie die Unterschiede zwischen dem ERD und der Live-Datenbank.
- Veraltung: Planen Sie die Entfernung von nicht verwendeten Tabellen und Spalten.
- Skalierbarkeit: Gestalten Sie mit Berücksichtigung von Partitionierung und Sharding für große Datensätze.
Die Vernachlässigung der Wartung führt zu einem zerbrechlichen System, das sich Veränderungen widersetzt. Proaktive Verwaltung stellt sicher, dass die Datenbank eine zuverlässige Grundlage für die Anwendung bleibt. Die Investition von Zeit in die ursprüngliche Gestaltung zahlt sich während des gesamten Lebenszyklus der Software aus.
Abschließende Gedanken zur Schemaintegrität 📝
Produktionsdatenbankfehler sind oft das Ergebnis übersehener Details in der Entwurfsphase. Durch die Berücksichtigung von Kardinalität, Datentypen, Einschränkungen und Indizierung können Teams widerstandsfähigere Systeme aufbauen. Die Kosten zur Behebung eines Fehlers in der Produktion sind erheblich höher als die Vermeidung während des Modellierens.
Konzentrieren Sie sich auf Klarheit, Konsistenz und Validierung. Ein gut strukturierter ERD ist die Grundlage der Datenzuverlässigkeit. Setzen Sie Qualität vor Geschwindigkeit, um langfristige Stabilität zu gewährleisten. Dieser Ansatz minimiert das Risiko und maximiert den Wert der in das System gespeicherten Daten.