











In der Architektur relationaler Systeme besteht ständig Spannung zwischen Datenintegrität und Leistung. Entitäts-Beziehungs-Diagramme (ERDs) dienen als Bauplan für diese Struktur und definieren, wie Tabellen miteinander verbunden sind. Während Fremdschlüssel sicherstellen, dass Beziehungen gültig bleiben, führen sie zu Overhead, der die Durchsatzleistung beeinträchtigen kann. Das Verständnis, wie man diese Einschränkungen optimiert, ist entscheidend für Systeme, die mit hohen Transaktionsvolumina arbeiten. Dieser Leitfaden untersucht die Mechanismen zur Optimierung von Fremdschlüsseln, um Konsistenz zu gewährleisten, ohne Geschwindigkeit einzubüßen. ⚡
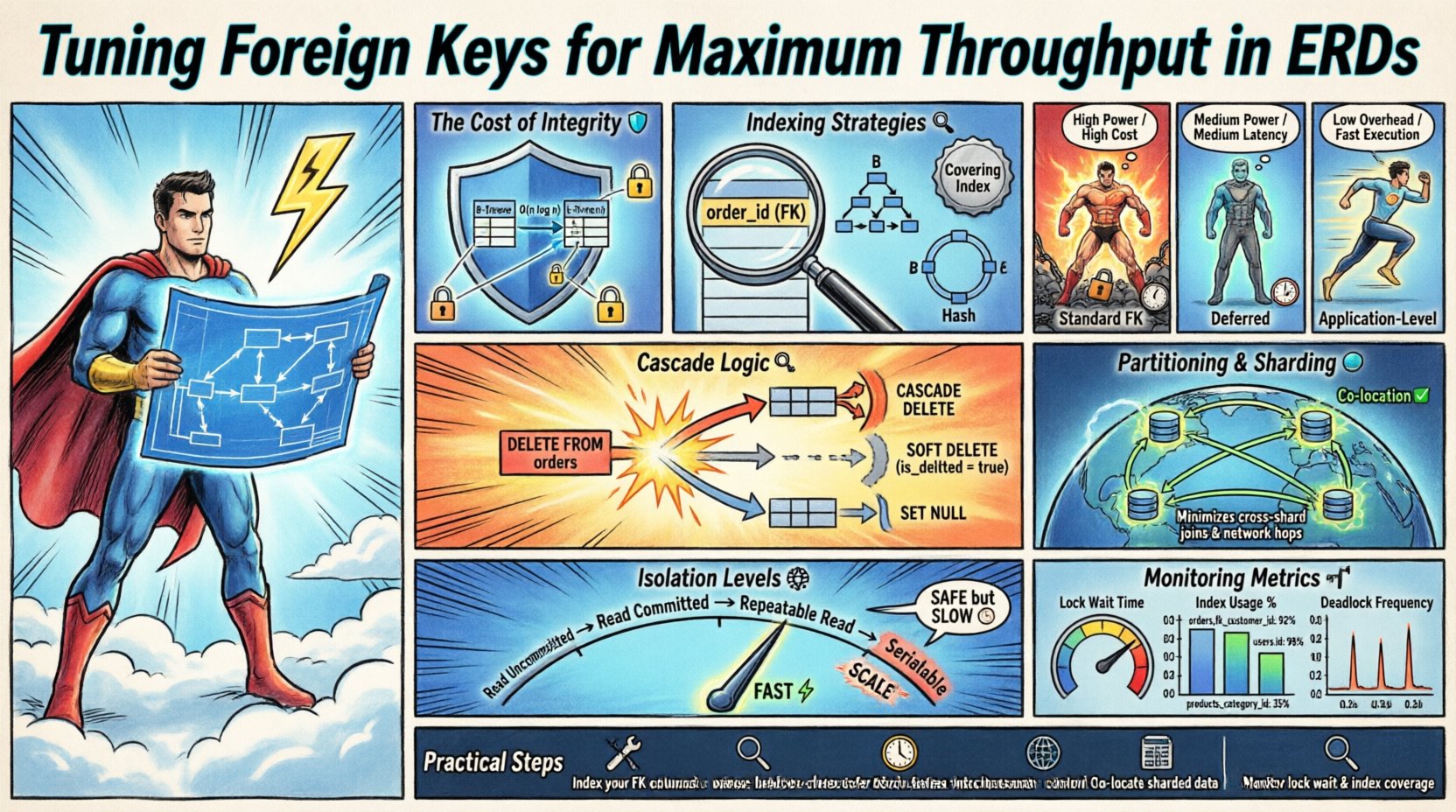
Verständnis der Kosten der Integritätsprüfung 🛡️
Fremdschlüssel sind nicht bloß Bezeichnungen; sie sind aktive Regeln, die von der Datenbankengine durchgesetzt werden. Jede Einfüge-, Aktualisierungs- oder Löschoperation, die einen Fremdschlüssel betrifft, löst Validierungslogik aus. Diese Logik prüft die übergeordnete Tabelle, um sicherzustellen, dass der referenzierte Wert existiert. In Umgebungen mit hoher Durchsatzleistung wird diese Prüfung zu einer erheblichen Kostenstelle.
Der Validierungsprozess umfasst typischerweise:
- Suchvorgänge:Das System muss in der übergeordneten Tabelle nach der referenzierten ID suchen.
- Sperrmechanismen:Die übergeordnete Zeile erfordert oft eine Sperrung, um gleichzeitige Änderungen während der Prüfung zu verhindern.
- Indexdurchlauf:Ohne geeignete Indizierung durchsucht die Engine große Teile der übergeordneten Tabelle.
Wenn Millionen von Transaktionen pro Sekunde stattfinden, addieren sich diese Mikroverzögerungen. Das Ziel ist nicht, die Integrität zu entfernen, sondern den Überprüfungsprozess zu optimieren. Berücksichtigen Sie die folgenden Szenarien, in denen dieser Overhead die Leistung beeinträchtigt:
- Stapelimporte:Das Laden historischer Daten erfordert oft temporäre Deaktivierung von Einschränkungen.
- Hochfrequente Schreibvorgänge:Systeme, die Ereignisse oder Sensordaten protokollieren, können Geschwindigkeit gegenüber sofortiger Konsistenz bevorzugen.
- Kaskadenoperationen:Das Löschen einer übergeordneten Zeile kann Aktualisierungen über mehrere untergeordnete Tabellen auslösen.
Indizierungsstrategien für Fremdschlüssel 🔍
Indizierung ist der direkteste Hebel zur Verbesserung der Fremdschlüsselleistung. Die Kindtabelle muss einen Index auf der Fremdschlüsselspalte haben, um vollständige Tabellenscans während Aktualisierungen zu vermeiden. Fehlt der Index, muss die Datenbank die gesamte übergeordnete Tabelle durchlaufen, um die Beziehung zu validieren.
Wichtige Überlegungen bei der Indizierung umfassen:
- Spaltenreihenfolge:Wenn der Fremdschlüssel Teil eines zusammengesetzten Indexes ist, ist seine Position für die Abfrageplanung von Bedeutung.
- Speicher-Engine:Verschiedene Speicherlagen behandeln Indizes unterschiedlich. B-Baum-Strukturen sind verbreitet, aber Hash-Indizes können schnellere Abfragen für Gleichheitsprüfungen bieten.
- Deckende Indizes:Die Aufnahme des Fremdschlüssels im Index ermöglicht es der Engine, Daten abzurufen, ohne auf den Heap zuzugreifen.
Ein häufiger Fehler ist die Annahme, dass der Primärschlüssel ausreicht. Wenn die Fremdschlüsselspalte häufig abgefragt oder aktualisiert wird, benötigt sie ihren eigenen dedizierten Index. Dadurch wird sichergestellt, dass der Validierungsschritt nicht zu einer sequenziellen Suche wird.
Einschränkungstypen und ihre Auswirkungen 📊
Nicht alle Fremdschlüssel verhalten sich gleich. Die Definition der Einschränkung bestimmt das Sperrverhalten und den Umfang der Prüfung. Die Auswahl des richtigen Einschränkungstyps ist eine entscheidende Gestaltungsentscheidung.
Vergleichen Sie das folgende Verhalten von Einschränkungen:
| Einschränkungstyp | Schreibauswirkung | Leseauswirkung | Verwendungszweck |
|---|---|---|---|
| Standard-FK | Hoch (Sperrt Eltern) | Niedrig | Kerntransaktionsdaten |
| Verzögert | Mittel (Prüfung beim Commit) | Niedrig | Massenladevorgänge / Stapeljobs |
| Ohne Index | Mittel (Durchsucht Eltern) | Mittel | Ein-zu-Viele mit seltenen Aktualisierungen |
| Anwendungsebene | Niedrig (Keine DB-Sperrungen) | Niedrig | Hochgeschwindigkeitsprotokollierung |
Die verzögerte Prüfung von Einschränkungen ermöglicht es der Datenbank, die Überprüfung während der Transaktion zu überspringen und sie erst zum Zeitpunkt des Commits durchzuführen. Dadurch wird die Dauer der auf der Elterntabelle gehaltenen Sperrungen reduziert. Dies ist besonders nützlich, wenn mehrere Zeilen in der Kindtabelle auf dieselbe Elternzeile verweisen oder wenn die Elternzeile innerhalb derselben Transaktion erstellt werden könnte.
Schreibverstärkung und Kaskadenlogik 🔄
Kaskadenoperationen sind leistungsstarke Werkzeuge zur Aufrechterhaltung der Datenhygiene, führen aber zu einer Schreibverstärkung. Wenn eine Elternzeile gelöscht wird, muss das System jede zugehörige Kindzeile finden und löschen. Dies vervielfacht die erforderlichen I/O-Operationen.
Strategien zur Minderung dieses Effekts umfassen:
- Weiche Löschungen: Anstatt Datensätze physisch zu entfernen, markieren Sie sie als inaktiv. Dadurch wird die Kaskadenkette vollständig vermieden.
- Auf NULL setzen: Wenn die Beziehung optional ist, ist das Setzen des Fremdschlüssels auf NULL schneller als das Löschen von Kindzeilen.
- Beschränken Verhindere die Löschung, wenn Kinder existieren. Dies zwingt die Anwendung, die Bereinigung auf kontrollierte Weise zu behandeln.
In verteilten Systemen können kaskadenartige Löschvorgänge Latenzspitzen verursachen. Eine einzelne Löschung eines übergeordneten Elements könnte Tausende von Aktualisierungen von untergeordneten Elementen über verschiedene Shards auslösen. Es ist oft besser, die Bereinigung asynchron mithilfe von Hintergrundaufgaben zu behandeln.
Überlegungen zu Partitionierung und Sharding 🌐
Wenn die Daten skaliert werden, verschlechtert sich die Leistung einer einzelnen Tabelle. Die Partitionierung teilt große Tabellen in handhabbare Teile auf. Fremdschlüssel erschweren diesen Prozess, da die Beziehung sich über Partitionen erstrecken muss.
Herausforderungen in partitionierten Umgebungen umfassen:
- Sperrungen über Partitionen hinweg: Wenn die übergeordnete und die untergeordnete Tabelle unterschiedlich partitioniert sind, muss die Engine die Sperrungen über die Partitionen hinweg koordinieren.
- Routing-Aufwand: Abfragen müssen bestimmen, welche Partition die referenzierten Daten enthält.
- Sharding-Schlüssel: Die Fremdschlüsselspalte sollte idealerweise der Sharding-Schlüssel sein, um verwandte Daten zusammenzuführen.
Wenn der Fremdschlüssel nicht der Sharding-Schlüssel ist, muss das System Abfragen an die richtige Shard zur Validierung weiterleiten. Diese Netzwerklatenz addiert sich. Die Zusammenführung von übergeordneten und untergeordneten Datensätzen auf demselben Knoten minimiert diesen Aufwand.
Transaktionsisolationsebenen und Durchsatz 🧩
Die Isolationsebene definiert, wie Transaktionen miteinander interagieren. Höhere Isolationsebenen bieten eine stärkere Konsistenz, erhöhen aber den Konkurrenzdruck. Fremdschlüssel interagieren direkt mit den Sperrmechanismen, die durch die Isolationsebenen definiert sind.
Häufige Auswirkungen der Isolation:
- Lesen Kommt: Erlaubt unreine Lesevorgänge. Fremdschlüsselprüfungen könnten nicht abgeschlossene Daten aus anderen Transaktionen sehen, was potenziell zu Rennbedingungen führen kann.
- Wiederholbare Lesevorgänge: Sperrt die übergeordnete Zeile für die Dauer der Transaktion. Dies verhindert Phantom-Lesevorgänge, reduziert aber die Konkurrenzfähigkeit.
- Serialisierbar: Bietet die höchste Sicherheit. Fremdschlüssel werden streng durchgesetzt, aber der Durchsatz sinkt aufgrund der Serialisierung erheblich.
Die Auswahl der niedrigsten Isolationsebene, die Ihren Geschäftslogiken entspricht, ist eine Standardoptimierungstechnik. Wenn Ihre Anwendung eine spätere Konsistenz tolerieren kann, kann die Senkung der Isolationsebene die Schreibdurchsatzleistung erheblich verbessern.
Überwachungs- und Wartungsmetriken 📈
Die Optimierung ist ein fortlaufender Prozess. Sie müssen spezifische Metriken überwachen, um Engpässe im Zusammenhang mit Fremdschlüsseln zu identifizieren.
Wichtige Metriken zur Überwachung:
- Wartezeit auf Sperrung:Hohe Werte deuten auf Konkurrenz auf übergeordneten Tabellen hin.
- Indexnutzung:Nicht verwendete Indizes verschwenden Speicherplatz und verlangsamen Schreibvorgänge.
- Häufigkeit von Deadlocks: Fremdschlüssel sind eine häufige Ursache für Verklemmungen in gleichzeitigen Systemen.
- Ausführungszeit der Abfrage:Langsame Einfügungen deuten oft auf fehlende Indizes in Fremdschlüsselspalten hin.
Regelmäßige Prüfungen des ERDs anhand tatsächlicher Abfragemuster stellen sicher, dass die Gestaltung der Last entspricht. Ein Schema, das für Lese-lastige Zugriffe konzipiert ist, kann sich von einem unterscheiden, das für Schreib-lastige Zugriffe ausgelegt ist.
Praktische Umsetzungsschritte 🛠️
Die Umsetzung dieser Optimierungen erfordert einen strukturierten Ansatz. Befolgen Sie diese Schritte, um Ihre Umgebung abzustimmen:
- Aktuelle Arbeitslasten profilieren: Identifizieren Sie, welche Tabellen die meisten Fremdschlüsselverstöße oder Sperrungen erzeugen.
- Abfragepläne analysieren: Stellen Sie sicher, dass Fremdschlüsselspalten durch Indizes abgedeckt sind.
- Kaskadenregeln überprüfen: Ermitteln Sie, ob harte Löschungen notwendig sind oder ob weiche Löschungen ausreichen.
- Kongruenz testen: Hochvolumige Schreibvorgänge simulieren, um die Sperrkonkurrenz zu messen.
- Einschränkungen verfeinern: Wechseln von ON DELETE CASCADE auf die Anwendungsebene für die Bereinigung, wo angemessen.
Durch systematische Bearbeitung dieser Bereiche verringern Sie die Reibung zwischen Datenintegrität und Systemgeschwindigkeit. Das Ergebnis ist eine robuste Architektur, die Skalierung bewältigen kann, ohne die Zuverlässigkeit zu beeinträchtigen.