











Die Gestaltung einer robusten Datenarchitektur erfordert mehr als nur das Zeichnen von Kästchen und Linien. Es erfordert ein tiefes Verständnis dafür, wie Daten fließen, wachsen und im Laufe der Zeit interagieren. Wenn ein System skaliert, dient das Entitäts-Beziehungs-Modell (ERD) als Bauplan für logische Konsistenz, während Partitionierungsstrategien physische Leistung adressieren. Die Abstimmung dieser beiden Aspekte ist entscheidend, um Abfragegeschwindigkeit, Datenintegrität und betriebliche Effizienz zu gewährleisten. Dieser Leitfaden untersucht, wie Sie Partitionierungstechniken mit Ihren bestehenden Datenmodellen harmonisieren können, ohne unnötige Komplexität oder Risiken einzuführen.
🧩 Die Grundlage: ERD als Bauplan
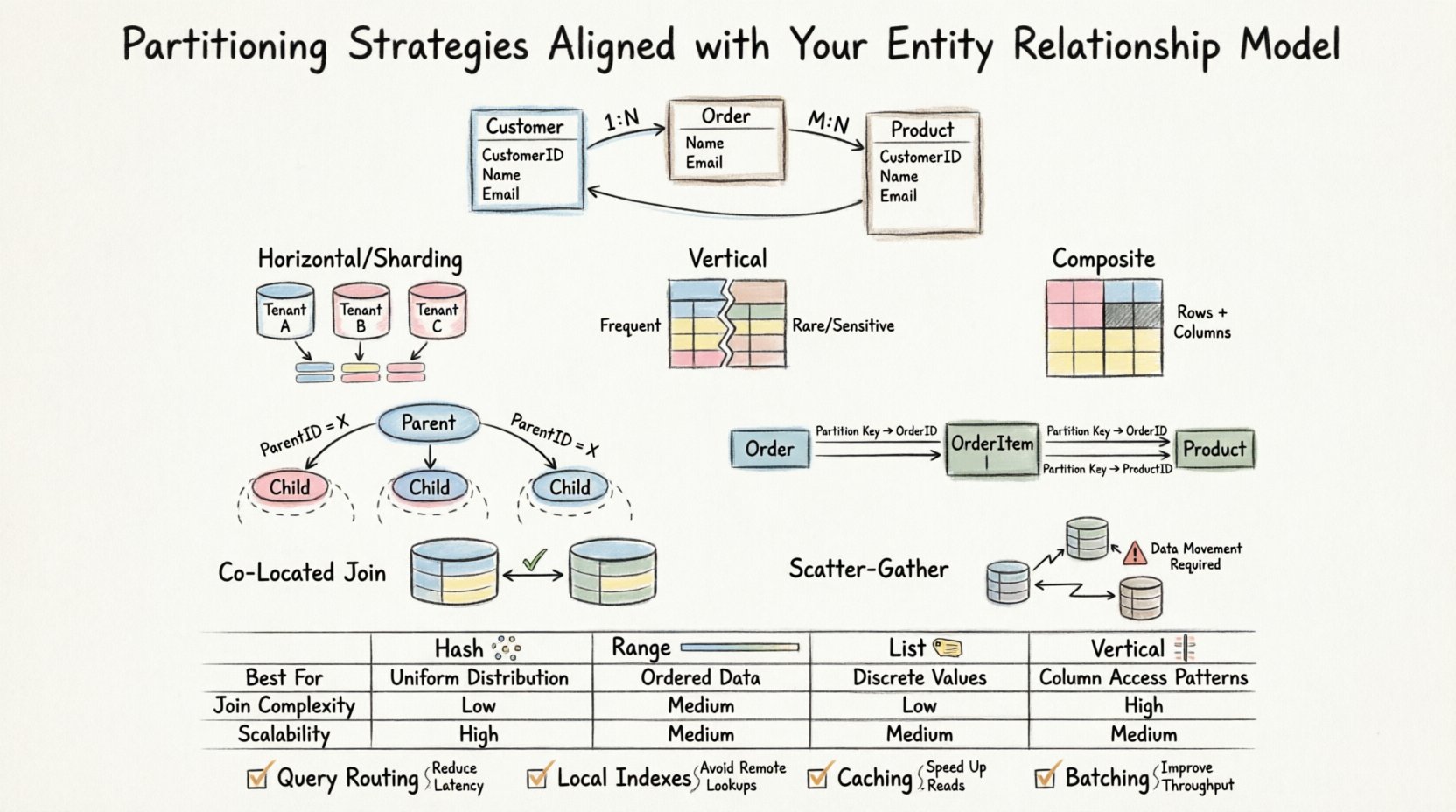
Bevor man darüber nachdenkt, wie man Daten aufteilt, muss man die Beziehungen verstehen, die sie verbinden. Ein ERD definiert Entitäten, Attribute und die Kardinalität zwischen ihnen. Diese Beziehungen bestimmen, wie Daten abgerufen und verbunden werden. Wenn man Partitionierung einführt, verteilt man im Wesentlichen diese logischen Beziehungen über physische Speicher-Grenzen hinweg.
Berücksichtigen Sie die folgenden Auswirkungen der Partitionierung auf Ihr Schema:
- Primärschlüssel:Müssen sorgfältig ausgewählt werden, um eine gleichmäßige Verteilung über die Partitionen zu gewährleisten.
- Fremdschlüssel:Das Verknüpfen von Tabellen in verschiedenen Partitionen kann erhebliche Overhead-Kosten verursachen.
- Indizes:Globale Indizes können zu Engpässen werden, wenn sie nicht mit dem Partitionierungsschlüssel im Blick behalten werden.
- Datenlokalität:Verwandte Daten sollten idealerweise auf demselben Knoten verbleiben, um die Netzwerklatenz zu minimieren.
Wenn man diese Faktoren ignoriert, kann es zu einer Situation kommen, in der das logische Modell in der Gestaltung perfekt funktioniert, die physische Implementierung jedoch unter Last leidet. Das Ziel ist es, verwandte Daten eng zusammenzuhalten, während gleichzeitig unabhängiges Wachstum ermöglicht wird.
🔄 Partitionierungstypen und Passgenauigkeit zum Schema
Verschiedene Partitionierungsmethoden eignen sich für unterschiedliche Datenzugriffsmuster. Die Auswahl der richtigen Methode hängt stark davon ab, wie Ihr ERD die Beziehungen definiert und welche Abfragemuster erwartet werden. Nachfolgend finden Sie eine Übersicht über gängige Strategien und deren Wechselwirkung mit relationalen Strukturen.
Horizontale Partitionierung (Sharding)
Die horizontale Partitionierung teilt Zeilen einer Tabelle in verschiedene Gruppen auf. Dies wird oft verwendet, wenn Tabellen zu groß werden, um sie in einer einzelnen Instanz zu verwalten. Im Kontext eines ERD funktioniert diese Strategie am besten, wenn der Partitionierungsschlüssel mit dem natürlichen Zugriffsmuster korreliert.
- Anwendungsfall:Große transaktionale Tabellen mit deutlich getrennten Nutzer- oder Mandanten-Gruppen.
- Auswirkung auf das ERD:Fremdschlüssel, die auf eine übergeordnete Tabelle verweisen, müssen sorgfältig verwaltet werden. Wenn auch die übergeordnete Tabelle partitioniert ist, müssen die Schlüssel ausgerichtet sein.
- Vorteil:Ermöglicht eine massive Skalierung durch Hinzufügen weiterer Knoten.
- Herausforderung:Komplexe Abfragen, die mehrere Partitionen umfassen, erfordern Aggregationslogik.
Vertikale Partitionierung
Die vertikale Partitionierung teilt Spalten einer Tabelle in verschiedene Gruppen auf. Dies ist nützlich, wenn bestimmte Spalten selten gemeinsam abgerufen werden oder wenn sensible Daten isoliert werden müssen.
- Anwendungsfall:Tabellen mit breiten Zeilen, bei denen nur eine Teilmenge der Spalten häufig abgefragt wird.
- ERD-Einfluss: Der Primärschlüssel muss auf allen vertikalen Partitionen vorhanden sein, um die Rekonstruktion der vollständigen Zeile zu ermöglichen.
- Vorteil: Verringert die I/O, indem nur die erforderlichen Spalten in den Speicher geladen werden.
- Herausforderung: Joins sind erforderlich, um die vollständige Entität wiederherzustellen, was die Abfragekomplexität erhöht.
Komposite Partitionierung
Dieser Ansatz kombiniert horizontale und vertikale Strategien. Er ist oft für Hochleistungssysteme erforderlich, bei denen sowohl das Zeilenvolumen als auch die Spaltenbreite bedeutende Einschränkungen darstellen.
- Anwendungsfall: Datenlagerung oder Hochfrequenz-Handelsprotokolle.
- ERD-Einfluss: Erfordert eine starre Schema-Definition vor der Implementierung.
🔑 Schlüssel mit Beziehungen ausrichten
Der wichtigste Schritt in diesem Prozess ist die Auswahl des Partitionsschlüssels. Dieser Schlüssel bestimmt, welche Zeile in welche physische Speichereinheit gelangt. Im relationalen Kontext sollte der Partitionsschlüssel idealerweise mit den Fremdschlüsselbeziehungen übereinstimmen.
Eltern-Kind-Beziehungen
Bei ein-zu-viele-Beziehungen wächst die Kindtabelle oft viel schneller als die Elterntabelle. Wenn Sie die Kindtabelle nach der Eltern-ID partitionieren, befinden sich alle zugehörigen Kinddatensätze auf demselben Knoten.
- Vorteil: Abfragen, die Eltern- und alle Kinddatensätze abrufen, erfordern keine Kommunikation über Knoten hinweg.
- Vorteil: Löschen erfolgt effizient innerhalb einer einzigen Partition.
- Warnung: Wenn ein Elternteil deutlich mehr Kinder hat als andere, kann Datenverzerrung auftreten.
Mehrzeilige-zu-mehrzeilige-Beziehungen
Mehrzeilige-zu-mehrzeilige-Beziehungen beinhalten typischerweise eine Verbindungstabelle. Diese Tabelle kann zu einer Leistungsengpassstelle werden, wenn sie nicht korrekt partitioniert ist.
- Strategie: Partitionieren Sie nach einem der beteiligten Fremdschlüssel.
- Strategie: Stellen Sie sicher, dass Abfragen immer nach dem Partitionsschlüssel filtern, um vollständige TabellenScans zu vermeiden.
- Strategie: Vermeiden Sie das Verknüpfen von Verbindungstabellen über mehrere Partitionen hinweg, es sei denn, es ist unbedingt notwendig.
⚖️ Behandlung von Join-Operationen
Joins sind das Lebensblut relationaler Datenbanken, werden aber teuer, wenn die Daten aufgeteilt sind. Das Verständnis dafür, wie Joins über Partitionen hinweg funktionieren, ist entscheidend, um die Leistung aufrechtzuerhalten.
Co-Lokalisierte Partitionen
Wenn Tabelle A und Tabelle B durch denselben Schlüssel partitioniert sind (z. B. Tenant_ID), findet ein Join zwischen ihnen lokal statt. Der Datenbank-Engine muss keine Daten zwischen Knoten bewegen.
- Anforderung: Beide Tabellen müssen denselben Partitionierungsalgorithmus und denselben Schlüssel verwenden.
- Anforderung: Das ERD muss diese Ausrichtung logisch unterstützen.
Scatter-Gather-Joins
Wenn Tabellen unterschiedlich partitioniert sind, muss das System Daten von mehreren Knoten abrufen, die Ergebnisse zusammenfassen und dann die endgültige Menge zurückgeben. Dies wird als Scatter-Gather-Operation bezeichnet.
- Leistungs-Kosten: Hoher Netzwerkoverhead.
- Leistungs-Kosten: Erhöhte Latenz.
- Empfehlung: Minimieren Sie diese Joins in der Phase der ERD-Entwicklung.
🛡️ Aufrechterhaltung der Integrität über Partitionen hinweg
Datenintegritätsbeschränkungen sind schwerer durchzusetzen, wenn die Daten verteilt sind. Das ERD definiert diese Regeln logisch, aber die Implementierung muss die physische Verteilung berücksichtigen.
- Referenzielle Integrität:Es ist komplex, sicherzustellen, dass ein Kind-Record existiert, bevor ein Eltern-Record eingefügt wird, wenn sie sich auf verschiedenen Knoten befinden.
- Einzigartige Beschränkungen:Globale Eindeutigkeit erfordert Koordination über alle Partitionen hinweg.
- Triggers:Anwendungslevel-Triggers ersetzen in verteilten Umgebungen oft Datenbanklevel-Triggers, um Sperrprobleme zu vermeiden.
- Transaktionen:Verteilte Transaktionen können die Durchsatzleistung beeinträchtigen. Halten Sie Transaktionen so weit wie möglich lokal innerhalb einer einzigen Partition.
📊 Vergleich von Partitionierungsstrategien
Die folgende Tabelle fasst zusammen, wie verschiedene Strategien mit gängigen ERD-Szenarien interagieren.
| Strategie | Am besten geeignet für ERD-Szenario | Komplexität von Joins | Skalierbarkeit beim Schreiben |
|---|---|---|---|
| Hash-Partitionierung | Gleichmäßige Verteilung erforderlich, kein spezifischer Bereich | Hoch (zufällige Verteilung) | Hoch |
| Bereichs-Partitionierung | Datumbasierte oder sequenzielle IDs | Niedrig (falls ausgerichtet) | Mittel |
| List-Partitionierung | Feste Kategorien (z. B. Region, Status) | Niedrig (falls ausgerichtet) | Hoch |
| Vertikale Partitionierung | Breite Zeilen, selten genutzte Spalten | Mittel (erfordert Rekonstruktion) | Hoch |
🔄 Evolution und Migration
Die Schema-Evolution ist unvermeidlich. Die Geschäftsanforderungen ändern sich, und neue Attribute werden hinzugefügt. Bei der Änderung eines ERDs muss die Partitionierungsstrategie überprüft werden.
- Spalten hinzufügen:Die vertikale Partitionierung erleichtert das Hinzufügen von Spalten, da sie auf einer neuen Partition platziert werden können.
- Schlüssel ändern:Die Neupartitionierung bestehender Daten ist eine aufwändige Operation. Planen Sie dies bereits bei der ursprünglichen Gestaltung.
- Archivierung:Die Partitionierung ermöglicht eine einfache Archivierung alter Datenbereiche, ohne aktive Partitionen zu beeinträchtigen.
- Überwachung:Überprüfen Sie regelmäßig die Größen der Partitionen, um sicherzustellen, dass keine einzelne Partition zu einem Hotspot wird.
🚀 Tipps zur Leistungs-Optimierung
Um sicherzustellen, dass das System weiterhin reaktionsfähig bleibt, sollten spezifische Optimierungen zusammen mit der Partitionierungsstrategie angewendet werden.
- Abfrageumleitung:Stellen Sie sicher, dass Anwendungen Abfragen basierend auf dem Partitionschlüssel an den richtigen Partitionsknoten senden.
- Indizierung:Lokale Indizes sind schneller als globale Indizes. Gestalten Sie Indizes so, dass sie zum Partitionschlüssel passen.
- Caching:Häufig verwendete Abfrage-Tabellen sollten nicht partitioniert werden, wenn sie klein genug sind, um im Speicher aller Knoten zu passen.
- Batches:Führen Sie Einfügungen und Aktualisierungen in Batches aus, um die Transaktionskosten über Partitionen hinweg zu reduzieren.
🔍 Abschließende Überlegungen
Die Entwicklung eines skalierbaren Systems erfordert ein Gleichgewicht zwischen logischer Klarheit und physischen Einschränkungen. Das Entity-Relationship-Modell legt die Regeln für Datenkonsistenz fest, während die Partitionierung die Grundlage für Wachstum bildet. Wenn diese beiden Aspekte abgestimmt sind, bleibt das System auch bei exponentiell steigenden Datenmengen leistungsstark.
Konzentrieren Sie sich auf die in Ihrem Modell definierten Beziehungen. Wenn die Daten natürlicherweise durch ein bestimmtes Attribut gruppiert sind, verwenden Sie dieses Attribut als Partitionschlüssel. Bei häufigen Joins stellen Sie sicher, dass die betreffenden Tabellen die gleiche Partitionierungslogik verwenden. Vermeiden Sie, das Schema unnötig zu komplizieren, indem Sie Partitionen einführen, die keinen klaren Leistungsbeitrag erbringen.
Durch Einhaltung dieser Prinzipien schaffen Sie eine Grundlage für langfristige Stabilität. Das Ziel ist nicht nur, Daten zu speichern, sondern sie so zu strukturieren, dass das System zukünftigen Anforderungen ohne umfassende Neugestaltung gerecht werden kann. Sorgfältige Planung in der Entwurfsphase spart erheblichen Aufwand während des Betriebs.