











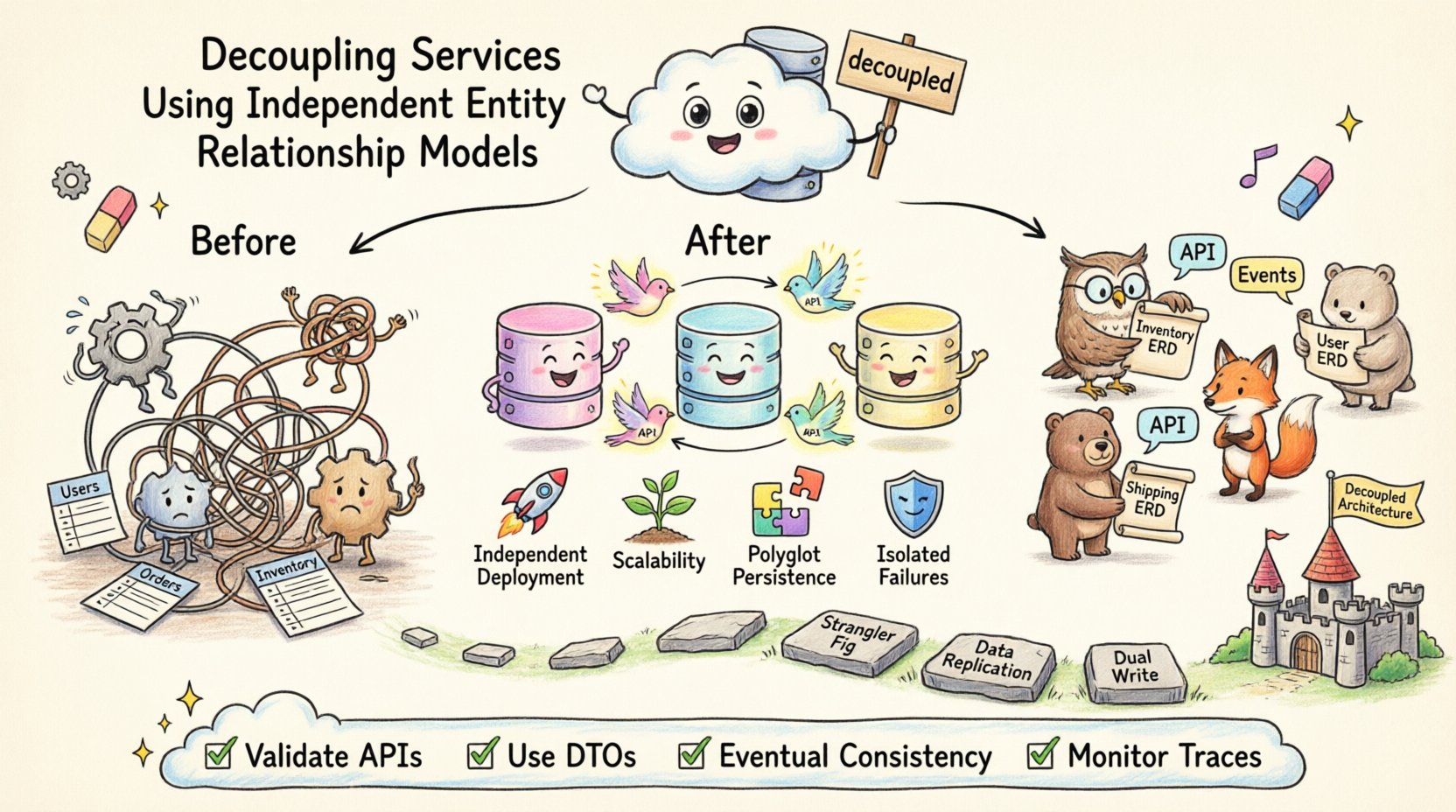
In der modernen Softwarearchitektur erstreckt sich die Trennung der Verantwortlichkeiten über die Code-Logik hinaus auf die Datenbesitzverhältnisse. Wenn Dienste ein einziges Datenbank-Schema teilen, werden sie zwangsläufig voneinander abhängig, was ihre internen Implementierungen betrifft. Diese enge Kopplung führt zu Fragilität, behindert die Bereitstellungsgeschwindigkeit und erschwert das Skalieren. Um echte Modularität zu erreichen, müssen Teams unabhängige Entitäts-Beziehungs-Modelle für jede Dienstgrenze übernehmen. Dieser Ansatz stellt sicher, dass Datenstrukturen privat für den Dienst bleiben, der sie besitzt, und fördert so Resilienz und Autonomie.
🤔 Die Herausforderung gemeinsam genutzter Daten
Veraltete Systeme stützen sich oft auf eine monolithische Datenbank, in der mehrere Anwendungsmodul die gleichen Tabellen abfragen. Obwohl dies die ursprüngliche Entwicklung vereinfacht, führt dies bei wachsenden Systemen zu erheblichen Risiken. Eine Änderung der Datenanforderungen eines Moduls kann die Funktionalität eines anderen Moduls beeinträchtigen, das auf die gleiche Tabellenstruktur angewiesen ist. Dieses Phänomen wird als das gemeinsame-Datenbank-Antipattern.
Stellen Sie sich eine Situation vor, in der der Benutzerdienst ein neues Feld in der Profiltabelle hinzufügen muss. Wenn der Bestellungs-Dienst diese Tabelle direkt zur Abfrage von Benutzernamen nutzt, könnte die Aktualisierung eine koordinierte Bereitstellung oder eine Datenbank-Migration erfordern, die beide Teams gleichzeitig betrifft. Diese Koordinationskosten verlangsamen die Innovation und erhöhen das Risiko von Produktionsstörungen.
-
Bereitstellungsabhängigkeiten:Dienste können nicht unabhängig bereitgestellt werden, wenn sie Schema-Definitionen teilen.
-
Skalierbarkeitsgrenzen:Eine einzelne Datenbank wird oft zu einem Engpass, wenn bestimmte Dienste mehr Ressourcen benötigen als andere.
-
Sicherheitsrisiken:Der direkte Tabellenzugriff umgeht die Dienstschicht und könnte vertrauliche Datenlogik preisgeben.
🗺️ Definition unabhängiger Entitäts-Beziehungs-Modelle
Ein unabhängiges Entitäts-Beziehungs-Modell (ERD) weist einem einzelnen Dienst ein spezifisches Daten-Schema zu. Das bedeutet, dass der Dienst seine eigene Datenbank, seine eigenen Tabellen und seine eigenen Beziehungen kontrolliert. Andere Dienste haben keinen direkten Zugriff auf diese Tabellen. Stattdessen interagieren sie über definierte Schnittstellen, wie APIs oder Nachrichtenwarteschlangen.
Dieser architektonische Stil wird oft alsDatenbank pro Dienst. Er verbindet die Datenbesitzverhältnisse mit den Geschäftsfähigkeiten. Zum Beispiel verwaltet ein Bestandsdienst Lagerbestände, während ein Versanddienst Lieferadressen verwaltet. Keiner der beiden Dienste sollte eine Fremdschlüssel-Referenz auf die internen Tabellen des anderen halten.
Der Prozess umfasst:
-
Identifizierung von Grenzen:Bestimmen, welche Daten zu welcher Geschäftsfähigkeit gehören.
-
Entwicklung lokaler Schemata:ERDs erstellen, die nur die spezifischen Anforderungen dieses Dienstes unterstützen.
-
Definition von Schnittstellen:Etablieren, wie Daten zwischen Diensten ausgetauscht werden, ohne interne Strukturen preiszugeben.
📈 Wichtige Vorteile der Schematisierung
Die Einführung unabhängiger ERDs verändert, wie Teams die Komplexität verwalten. Es verlagert den Fokus von zentraler Kontrolle hin zu dezentraler Autonomie. Jedes Team kann seine Daten-Speicherstrategie optimieren, ohne sich um globale Auswirkungen kümmern zu müssen.
|
Aspekt |
Modell mit gemeinsamer Datenbank |
Unabhängiges ERD-Modell |
|---|---|---|
|
Bereitstellung |
Koordiniert, riskant |
Unabhängig, häufig |
|
Skalierbarkeit |
Nur horizontal (Cluster) |
Vertikal pro Dienst |
|
Technologie |
Einzelne DB-Art |
Polyglotte Persistenz |
|
Ausfallbereich |
Einzelner Ausfallpunkt |
Isolierte Ausfälle |
🔗 Gestaltung für lose Kopplung
Wenn Dienste nicht direkt über ihre Datenbanken miteinander kommunizieren können, müssen sie über APIs kommunizieren. Dies erfordert eine sorgfältige Gestaltung des Vertrags zwischen den Diensten. Die API wird zum einzigen gemeinsamen Vertrag. Wenn der API-Vertrag stabil bleibt, kann das zugrundeliegende Datenmodell geändert werden, ohne die Verbraucher zu beeinflussen.
API-Versionierung: Da Datenmodelle sich weiterentwickeln, müssen APIs die Versionierung unterstützen. Dadurch können alte Clients weiterhin funktionieren, während neue Clients aktualisierte Strukturen übernehmen.
Datenübertragungsobjekte (DTOs): Exponiere Entitätsobjekte nicht direkt. Erstelle spezifische DTOs, die nur die für den Verbraucher notwendigen Daten enthalten. Dadurch verhindert man, dass interne Änderungen nach außen dringen.
-
Validierung: Validiere Eingaben am API-Rand, nicht allein auf Datenbankebene.
-
Idempotenz: Stelle sicher, dass Operationen sicher wiederholt werden können, ohne doppelte Datensätze zu verursachen.
-
Dokumentation: Pflege klare Dokumentation für alle Datenaustauschformate.
⚖️ Behandlung von Transaktionen und Konsistenz
Eine der größten Herausforderungen bei der Entkopplung ist die Aufrechterhaltung der Datenintegrität. In einer gemeinsam genutzten Datenbank kann eine Transaktion problemlos mehrere Tabellen umfassen. In einem verteilten System kann eine einzelne logische Transaktion mehrere Dienste umfassen. Dies wird als dieProblem der verteilten Transaktion.
Um dies zu lösen, übernehmen Teams oft dieErfolgsorientierte Konsistenz Muster. Anstatt sicherzustellen, dass die Daten sofort überall identisch sind, stellt das System sicher, dass sie im Laufe der Zeit konsistent werden. Dies wird durch asynchrone Nachrichtenübertragung erreicht.
Saga-Muster: Eine Saga ist eine Folge lokaler Transaktionen. Jede Transaktion aktualisiert die Datenbank und veröffentlicht ein Ereignis, um die nächste Transaktion auszulösen. Wenn ein Schritt fehlschlägt, werden kompensierende Transaktionen ausgeführt, um vorherige Änderungen rückgängig zu machen.
-
Outbox-Muster: Schreibe Ereignisse in eine lokale Tabelle neben der Hauptdatenänderung. Ein Hintergrundprozess veröffentlicht diese Ereignisse und stellt sicher, dass keine Daten verloren gehen.
-
Idempotente Verbraucher: Nachrichtenhandler müssen doppelte Nachrichten reibungslos verarbeiten können.
-
Kompensierende Aktionen: Definiere klare Rückgängigmachungslogik für jede Vorwärtsaktion.
🚚 Migrationsstrategien
Der Wechsel von einer gemeinsam genutzten Datenbank zu unabhängigen ERDs ist eine erhebliche Aufgabe. Dazu ist ein schrittweiser Ansatz erforderlich, um das Risiko zu minimieren. Eile bei der Migration kann zu Datenverlust oder Dienstausfällen führen.
Strangler-Fig-Muster: Bewege die Funktionalität schrittweise zu neuen Diensten. Beginne mit einer bestimmten Funktion, beispielsweise Benutzerbenachrichtigungen. Erstelle einen neuen Dienst mit eigenem ERD für diese Funktion. Leite den Datenverkehr an den neuen Dienst weiter, während das veraltete System weiterläuft.
Datenreplikation: Während der Übergangsphase müssen Sie möglicherweise sicherstellen, dass die Daten zwischen der alten und der neuen Datenbank synchronisiert bleiben. Dadurch kann der neue Dienst vorübergehend Daten aus dem alten System lesen, während er seine eigene Datenbasis auffüllt.
Doppeltes Schreiben: Schreibe während des Migrationsfensters gleichzeitig in die alte und die neue Datenbank. Stelle sicher, dass der neue Dienst korrekt funktioniert, bevor du das Schreiben in die alte Datenbank deaktivierst.
🔍 Überwachung und Wartung
Bei unabhängigen Datenspeichern wird die Überwachung komplexer. Du siehst nicht mehr nur ein einziges Dashboard zur Datenbankgesundheit. Du musst Protokolle und Metriken aus mehreren Quellen zusammenführen.
Verteilte Tracing: Implementiere Tracing, um eine Anfrage zu verfolgen, während sie durch verschiedene Dienste fließt. Dies hilft dabei, festzustellen, welcher Dienst Verzögerungen oder Fehler verursacht.
Schema-Registrierung: Pflege eine Registrierung von API-Verträgen. Dadurch wird sichergestellt, dass jede Änderung am Datenmodell vor der Bereitstellung überprüft und genehmigt wird.
-
Benachrichtigungen: Stelle Warnungen für Replikationsverzögerungen und Nachrichtenwarteschlangen-Backlogs ein.
-
Kapazitätsplanung: Überwache das Speicherwachstum pro Dienst, um unerwartete Kosten zu vermeiden.
-
Sicherungsstrategien: Stelle sicher, dass jeder Dienst über einen eigenen Sicherungs- und Wiederherstellungsplan verfügt.
🛠️ Häufige Fallen, die zu vermeiden sind
Selbst mit einem soliden Plan stolpern Teams oft bei der Umsetzung. Das Verständnis dieser häufigen Fehler kann erhebliche Zeit und Mühe sparen.
-
Verborgene Kopplung:Vermeiden Sie das Verwenden von Datenbankansichten oder gemeinsam genutzten Tabellen, selbst wenn sie in getrennten Schemas liegen. Der direkte Zugriff auf die Datenbank sollte verboten sein.
-
Überfragmentierung:Erstellen Sie nicht für jede kleine Funktion eine neue Datenbank. Gruppieren Sie verwandte Entitäten in logische Dienste.
-
Ignorieren der Latenz:Netzwerkaufrufe sind langsamer als lokale Abfragen. Gestalten Sie APIs so, dass die Anzahl der Rundreisen minimiert wird.
-
Komplexe Abfragen:Vermeiden Sie Joins über Dienste hinweg. Wenn Sie Daten aus mehreren Diensten benötigen, rufen Sie sie getrennt ab und führen die Ergebnisse auf der Anwendungsebene zusammen.
🧱 Abschließende Gedanken
Die Entkopplung von Diensten mithilfe unabhängiger Entitätsbeziehungsmodelle ist eine strategische Entscheidung, die sich langfristig auszahlt. Sie erfordert Disziplin im Design und die Bereitschaft, verteilte Komplexität zu managen. Doch das Ergebnis ist ein System, das einfacher zu skalieren ist, widerstandsfähiger gegenüber Ausfällen und schneller zu evolutionären Änderungen. Indem Dienste ihre Daten kontrollieren, erlangen sie die Autonomie, die sie benötigen, um ohne ständige Abstimmung zu innovieren.
Beginnen Sie damit, die wichtigsten Grenzen in Ihrem System zu identifizieren. Isolieren Sie zunächst die Daten für diese Dienste. Verbessern Sie Ihre API-Verträge und Nachrichtenmuster im Laufe der Zeit. Dieser schrittweise Ansatz gewährleistet Stabilität, während Sie sich einer vollständig entkoppelten Architektur nähern.