










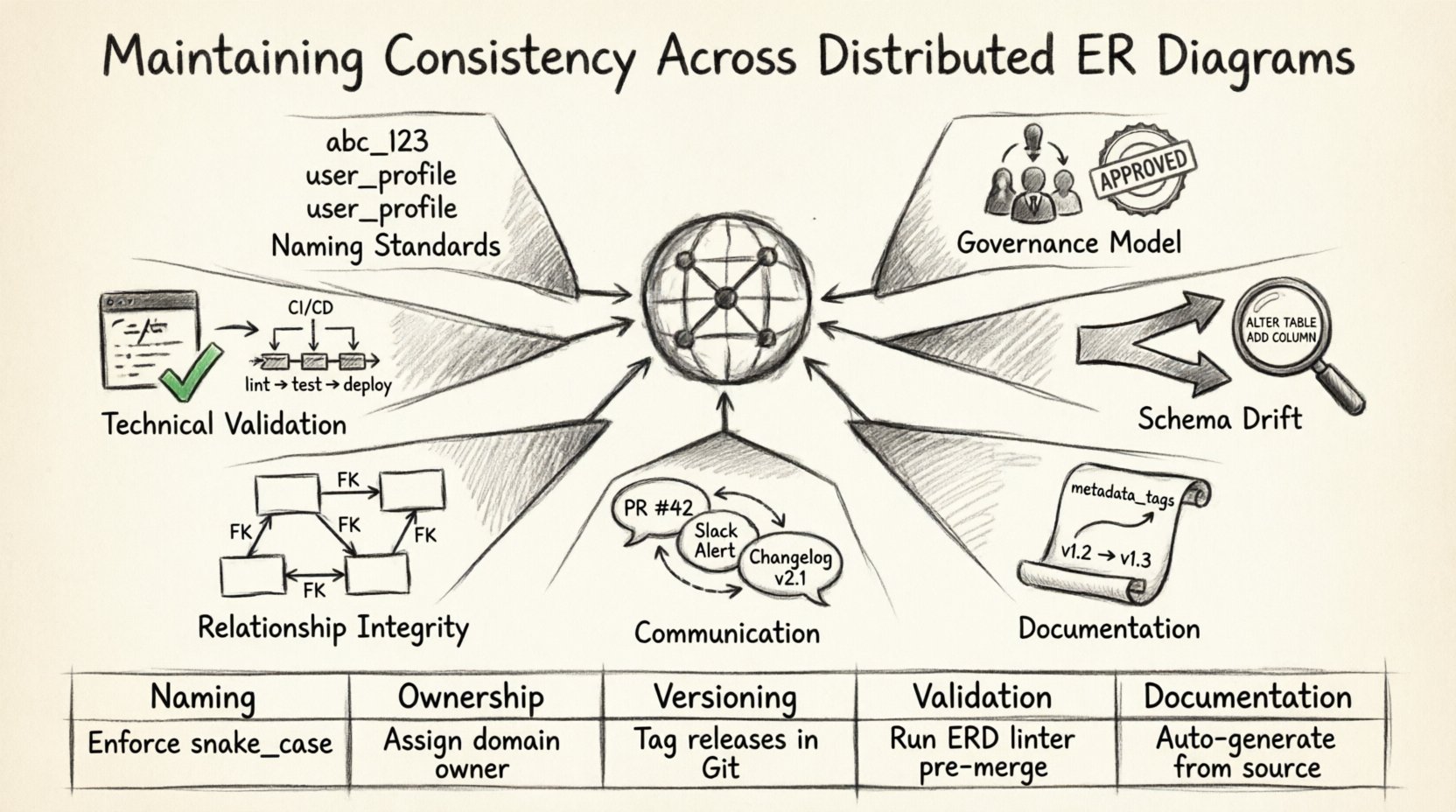
In der modernen Unternehmensarchitektur befindet sich Daten selten in einem einzigen Silo. Teams erstrecken sich über Kontinente, Systeme entwickeln sich unabhängig, und Datenbank-Schemata müssen reibungslos ausgerichtet sein. Diese Realität schafft eine spezifische Herausforderung: die Aufrechterhaltung der Konsistenz über verteilte Entity-Relationship-Diagramme (ERD) hinweg. Wenn mehrere Gruppen Datenmodelle für dasselbe logische Domäne entwerfen, ist eine Divergenz ohne strenge Governance unvermeidlich.
Inkonsistente Schemata führen zu Integrationsfehlern, mehrdeutigen Datendefinitionen und erheblichem technischem Schulden. In diesem Artikel werden strukturelle und prozedurale Methoden untersucht, die erforderlich sind, um verteilte Datenmodelle synchronisiert zu halten. Wir konzentrieren uns auf Standards, Arbeitsabläufe und Validierungstechniken, die sicherstellen, dass Ihre Datenarchitektur unabhängig davon, wo das Modellieren stattfindet, robust bleibt.
🔍 Warum Konsistenz in verteilten Umgebungen wichtig ist
Datenkonsistenz geht nicht nur um die visuelle Ausrichtung in einem Diagramm. Es geht um semantische Integrität. Wenn zwei Teams eine „Kunde“-Entität unterschiedlich definieren, leiden nachgelagerte Anwendungen darunter. Eine könnte sie als eine einzelne Tabelle behandeln, während eine andere sie in „Profil“ und „Abrechnung“ aufteilt. Diese Fragmentierung erschwert Joins, Berichterstattung und die Entwicklung von APIs.
Die Vorteile eines einheitlichen Ansatzes umfassen:
- Datenintegrität: Fremdschlüssel-Beziehungen bleiben über Dienste hinweg gültig.
- Abfrageleistung: Optimierte Join-Pfade beruhen auf vorhersehbaren Schemastrukturen.
- Effizienz bei der Einarbeitung: Neue Ingenieure verstehen das System schneller, wenn Standards klar sind.
- Sicherheit beim Refactoring: Änderungen werden logisch propagiert, anstatt abhängige Systeme zu beschädigen.
📏 Festlegung von Namenskonventionen
Die erste Verteidigungslinie gegen Inkonsistenzen ist eine strenge Namenskonvention. Ohne diese könnte eine Gruppe in einer Region eine Tabelle benennenBenutzer, während eine andereBenutzerkonten. Im Laufe der Zeit führen diese Unterschiede zu Verwirrung und Duplikation.
Regeln für die Namensgebung von Entitäten
- Pluralisierung: Entscheiden Sie früh, ob Tabellen im Plural (z. B.
Bestellungen) oder im Singular (z. B.Bestellung). Halten Sie sich an eine einzige Stilrichtung über alle Diagramme hinweg. - Unterstriche versus CamelCase:SQL-Standards bevorzugen oft snake_case für Tabellennamen, während objektorientierte Schichten möglicherweise camelCase bevorzugen. Stellen Sie sicher, dass das ERD die Speicher-Ebene widerspiegelt.
- Präfixierte Domänen: Verwenden Sie Präfixe, um Geschäftsbereiche zu kennzeichnen (z. B.
fin_bestellungen,hr_mitarbeiter) um Kollisionen in gemeinsam genutzten Schema-Räumen zu vermeiden.
Benennungsregeln für Attribute
- Zeitstempel: Verwenden Sie Standard-Suffixes wie
_erstellt_amund_aktualisiert_amfür Auditspuren. - Fremdschlüssel: Benennen Sie Spalten basierend auf der referenzierten Tabelle (z. B.
kunde_id), nicht den Beziehungsnamen. - Boolesche Flags: Präfixen Sie boolesche Spalten mit
ist_oderhat_zur Klarheit (z. B.ist_aktiv).
🛡️ Governance-Modelle für verteilte Teams
Wer besitzt das Schema? In einer verteilten Umgebung ist Zentralisierung oft unmöglich, aber völlige Dezentralisierung führt zu Chaos. Ein hybrides Governance-Modell funktioniert meist am besten.
Zentraler Standardsausschuss
Eine kleine Gruppe definiert die Regeln. Sie erstellen nicht jedes Diagramm, aber sie genehmigen die Standards. Diese Gruppe pflegt die Dokumentation und behandelt Streitigkeiten bezüglich Namensgebung oder Struktur.
Föderierte Eigentümerschaft
Teams besitzen ihre Bereiche, halten sich aber an den gemeinsamen Vertrag. Zum Beispiel besitzt das Finanzteam die Zahlungen Schema, aber sie müssen das benutzer_id Standard, der vom Core-Team definiert wurde.
Überprüfungszyklen
Regelmäßige Überprüfungen verhindern Abweichungen. Planen Sie monatliche Sitzungen, in denen Schemaänderungen vorgestellt werden. Dadurch wird sichergestellt, dass eine neue Entität keine bestehenden Beziehungseinschränkungen verletzt.
🔄 Schema-Drift verwalten
Schema-Drift tritt auf, wenn die physische Datenbank von der dokumentierten ERD abweicht. Dies ist bei verteilten Systemen üblich, bei denen Bereitstellungen asynchron erfolgen.
Erkennungsmechanismen
- Automatisiertes Abgleichen: Vergleichen Sie die aktuelle Datenbankstruktur mit dem kanonischen ERD-Modell.
- Migrations-Skripte: Behandeln Sie Schemaänderungen wie Code. Jede Änderung muss versioniert und nachvollziehbar sein.
- Metadaten-Tags: Fügen Sie Versionsinformationen in die Datenbank-Metadaten oder Tabellenkommentare ein.
Beseitigungsstrategien
Wenn Abweichungen erkannt werden, dürfen sie nicht ignoriert werden. Erstellen Sie ein Ticket, um die Differenz auszugleichen. Idealerweise sollte die ERD aktualisiert werden, um dem Produktionszustand zu entsprechen, falls die Änderung beabsichtigt war, oder die Datenbank sollte zurückgesetzt werden, falls die Änderung nicht autorisiert war.
| Art der Abweichung | Risikostufe | Empfohlene Maßnahme |
|---|---|---|
| Fehlender Index | Mittel | Im Änderungsprotokoll dokumentieren; Optimierung planen. |
| Geänderter Datentyp | Hoch | Sofortige Untersuchung; potenzielles Risiko von Datenverlust. |
| Entfernte Spalte | Kritisch | Rückgängigmachen der Bereitstellung; Daten wiederherstellen, falls möglich. |
| Hinzugefügte Spalte | Niedrig | Aktualisieren Sie die ERD-Dokumentation, um die Änderung widerzuspiegeln. |
📄 Dokumentation und Metadaten
Diagramme sind visuelle Darstellungen, aber Metadaten liefern den Kontext. Ein gut gepflegtes ERD enthält mehr als nur Linien und Felder.
- Geschäftsdefinitionen: Definieren Sie, was ein bestimmtes Feld im geschäftlichen Sinne bedeutet. Ist
Status„aktiv“ oder „abgeschlossen“? - Beschränkungsregeln: Dokumentieren Sie eindeutige Beschränkungen, Prüfbeschränkungen und Standardwerte direkt im Diagramm oder in der begleitenden Wiki.
- Verantwortlichkeit: Geben Sie klar an, welches Team für die Pflege bestimmter Tabellen verantwortlich ist.
- Versionsverlauf: Verfolgen Sie, wann Entitäten erstellt, geändert oder veraltet wurden.
Ohne diese Metadaten ist das Diagramm nur ein Bild. Mit ihnen wird das Diagramm zu einem Vertrag.
🔗 Beziehungsintegrität
In verteilten Systemen sind Beziehungen oft der empfindlichste Teil des Modells. Fremdschlüssel sind der Kleber, können aber zu Engpässen oder Ausfallpunkten werden.
Referenzielle Integrität
- Auf Datenbankebene durchsetzen: Verwenden Sie Fremdschlüsselbeschränkungen, wo immer möglich, um verwaiste Datensätze zu verhindern.
- Überprüfungen auf Anwendungsebene: Bei Mikrodiensten setzen Sie Logik in der Anwendungsschicht durch, wenn Datenbankebene-Beschränkungen nicht durchführbar sind.
Kardinalitätskonsistenz
Stellen Sie sicher, dass die Kardinalität (eins-zu-eins, eins-zu-viele), die im ERD definiert ist, mit der tatsächlichen Datennutzung übereinstimmt. Eine eins-zu-viele-Beziehung, die im Diagramm gezeichnet ist, darf nicht im Code als eins-zu-eins implementiert werden.
🚧 Häufige Fallen und wie man sie vermeidet
Auch bei Standards machen Teams Fehler. Das Erkennen dieser Muster hilft, zukünftige Fehler zu vermeiden.
1. Das ‚Golden-Table‘-Syndrom
Vermeiden Sie eine einzelne Tabelle, die Daten für jedes Domäne enthält. Dies erzeugt einen Engpass bei Schreibvorgängen und macht das Schema monolithisch. Stattdessen normalisieren Sie die Daten in verwandte Entitäten.
2. Implizite Beziehungen
Verlassen Sie sich nicht allein auf die Spaltenbenennung, um Beziehungen zu definieren. Wenn eine Tabelle eine benutzer_id, muss explizit mit der benutzer Tabelle im ERD verknüpft werden.
3. Festgelegte Werte
Integrieren Sie keine Geschäftslogik in das Schema. Eine Spalte mit dem Namen ist_leiter ist besser als eine Spalte mit dem Namen rolle_id wenn die Rolle festgelegt ist. Flexible Rollen sollten jedoch eine separate Abfrage-Tabelle verwenden.
🛠️ Technische Umsetzung und Validierung
Standards müssen technisch durchgesetzt werden, nicht nur verbal. Automatisierung reduziert menschliche Fehler.
- Lint-Tools: Verwenden Sie Datenbankschema-Linter, die anhand von Namenskonventionen prüfen.
- CI/CD-Sperren: Sperrt Bereitstellungen, wenn der Schema-Unterschied nicht dem genehmigten Migrationsplan entspricht.
- Schema-Registrierung: Pflegen Sie eine zentrale Registrierung aller genehmigten Entitäten und ihrer Versionen.
🤝 Kommunikationsprotokolle
Technologie ist nur die Hälfte des Kampfes. Menschen müssen Änderungen effektiv kommunizieren.
- Änderungsprotokolle: Jede Schema-Änderung muss einen verknüpften Eintrag im Änderungsprotokoll haben.
- Auswirkungsanalyse: Bevor eine Tabelle geändert wird, dokumentieren Sie, welche Dienste davon abhängen.
- Benachrichtigungskanäle: Verwenden Sie spezielle Kanäle für Schema-Warnungen, damit Teams wissen, wann sie ihre lokalen Modelle aktualisieren müssen.
Durch die Kombination strenger Standards mit offener Kommunikation können verteilte Teams eine einheitliche Sicht auf die Datenlandschaft erreichen. Das Ziel ist nicht, jede Entscheidung zu kontrollieren, sondern sicherzustellen, dass jede Entscheidung mit der übergeordneten architektonischen Vision übereinstimmt.
📊 Zusammenfassung der Best Practices
| Bereich | Wichtiger Schritt |
|---|---|
| Benennung | Setzen Sie Regeln für snake_case und Pluralisierung durch. |
| Eigentum | Weisen Sie klarer Domänen-Eigentum Teams zu. |
| Versionsverwaltung | Verfolgen Sie alle Schemaänderungen als Code. |
| Validierung | Automatisieren Sie die Erkennung von Abweichungen und die Berichterstattung. |
| Dokumentation | Halten Sie Metadaten zusammen mit dem Code aktuell. |
Konsistenz über verteilte ER-Diagramme hinweg ist ein fortlaufender Prozess. Er erfordert Disziplin, regelmäßige Audits und ein Engagement für gemeinsame Standards. Wenn korrekt umgesetzt, verwandelt er ein fragmentiertes Datenumfeld in ein kohärentes, zuverlässiges Asset.