











关系型数据库建立在表和行的基础上,这种结构专为扁平数据设计。然而,现实世界很少遵循如此简单的模式。组织、文件系统、评论线程和分类树都存在于层次结构中。在标准实体关系图(ERD)中表示这些父子关系,需要特定的设计模式,在保持数据完整性的同时实现高效检索。
当你试图将树状结构映射到扁平模式时,会遇到规范化与性能之间的经典矛盾。本指南探讨了建模层次数据的核心技术,评估每种方法的权衡,帮助你设计出稳健的系统。
🧩 扁平模式的挑战
实体关系图通常将实体表示为方框,关系表示为线条。在标准关系中,一个表通过外键链接到另一个表。这在方向固定的多对多或一对多场景中运行完美。但当一个分类可以有子分类,子分类又可以有子子分类,甚至无限延伸时,会发生什么?
标准的关系模型难以处理可变深度。扁平表无法轻松存储任意长度的路径。为了解决这个问题,我们必须调整模式,显式地存储层次结构。数据架构师通常使用以下三种主要模式来实现这一点:
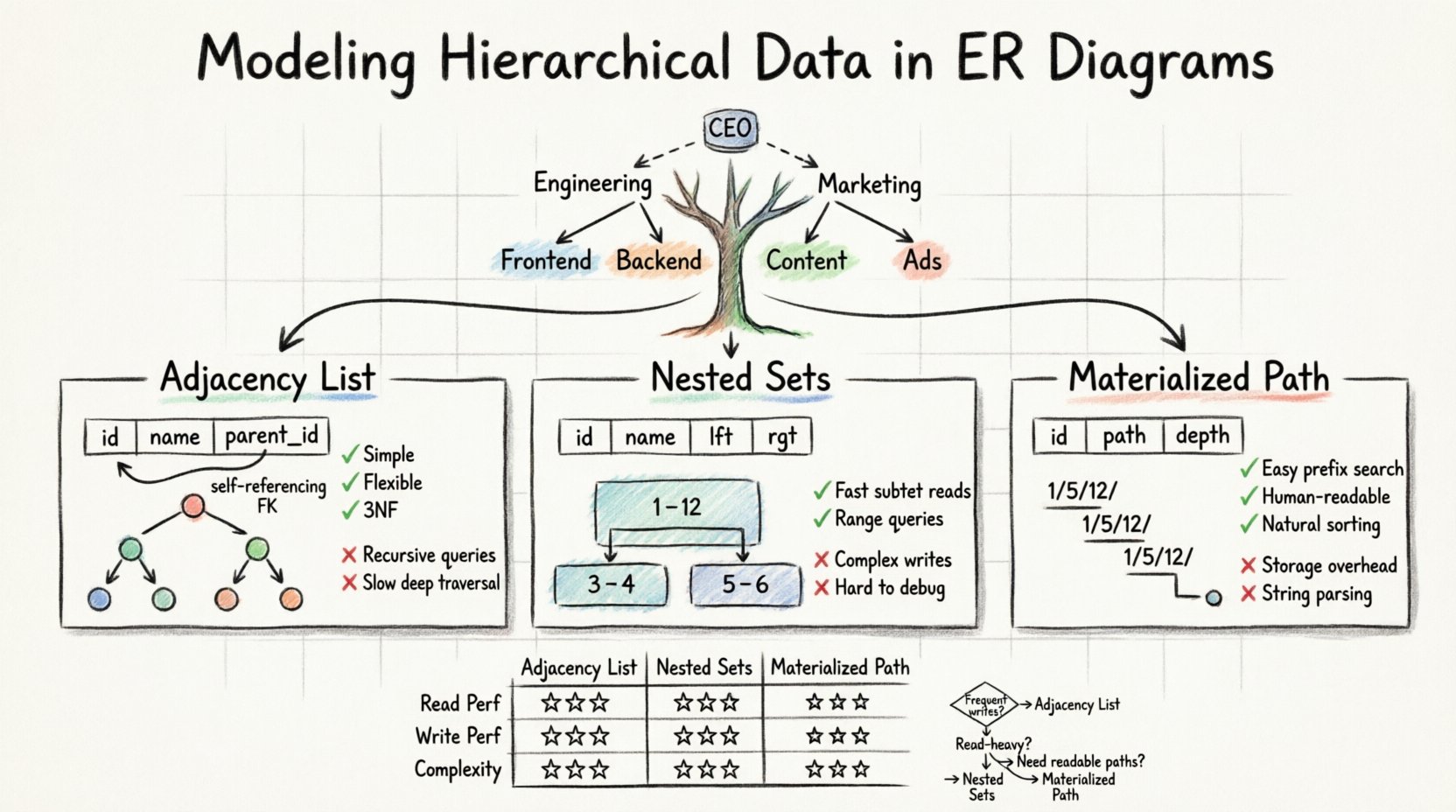
- 邻接列表: 在子记录中存储父级ID。
- 嵌套集合: 分配左值和右值以定义范围。
- 路径枚举: 存储从根节点到当前节点的完整路径。
🔗 邻接列表模型
邻接列表是标准ERD中表示层次结构最常见且最直接的方法。它依赖于自引用关系,这意味着一个表中包含一个引用其自身主键的列。
📐 模式结构
在此模型中,你创建一个单独的表来存储数据。每一行代表树中的一个节点。关键的补充是一个列,通常命名为parent_id或ancestor_id,用于存储父节点的唯一标识符。如果一个节点位于层次结构的顶端,该列将包含空值。
考虑一个用于部门:
- id: 部门的唯一主键。
- name: 部门的显示名称。
- parent_id: 上级部门的ID(顶级部门可为空)。
✅ 优势
- 简单性: 该模式的结构直观,对开发人员和数据库管理员来说易于理解。
- 灵活性: 移动子树很简单;你只需更新该子树根节点的
parent_id值。 - 规范化: 由于数据不会重复,它很好地遵循了第三范式(3NF)。
❌ 缺点
- 查询复杂性: 获取所有后代需要递归查询或应用层处理。
- 性能: 如果没有特定的索引策略或递归公用表表达式(CTEs),深层遍历可能会很慢。
- 引用完整性: 尽管外键有所帮助,但如果约束未严格实施,仍可能发生循环引用。
🌲 嵌套集模型
嵌套集模型将树结构转换为一组区间。与其追踪父指针,不如为每个节点分配两个数字:left 和 right。这些值表示节点在树的前序遍历中的位置。
📐 模式结构
想象一棵树,其根节点代表整个集合。当你遍历这棵树时,会递增一个计数器。当你进入一个节点时,将当前计数记录为left。当你完成对该节点及其所有子节点的处理后,将计数记录为right。其中right 值始终大于 左 值。
一个 分类 表看起来像这样:
- id: 唯一标识符。
- 名称: 分类名称。
- lft: 左边界值。
- rgt: 右边界值。
✅ 优点
- 快速检索: 获取子树只需使用
BETWEEN逻辑的简单范围查询。 - 高效性: 与邻接表相比,对于大型、深层的树,读取性能更优。
❌ 缺点
- 写入成本: 插入或移动节点成本较高。您必须更新
lft和rgt许多其他节点的值,以保持区间完整性。 - 复杂性: 若无专用库支持,该逻辑难以实现和调试。
🛣️ 路径枚举与物化路径
路径枚举方法将节点的继承关系以字符串或分隔列表的形式存储。这种方法通常被称为物化路径模式。它结合了邻接表的简洁性与路径的可读性。
📐 模式结构
在此模型中,每条记录都存储从根节点到该节点的完整路径。例如,在文件系统模型中,一个文件的路径字符串可能是/home/user/documents/report.txt。在数据库中,这通常作为列内的分隔字符串存储,例如1/5/12/.
该表包含:
- id: 主键。
- path: 一个表示继承关系的字符串。
- depth: 一个整数,表示该节点的深度层级。
✅ 优点
- 易于遍历: 通过匹配路径前缀,可以找到所有后代节点。
- 可读性: 数据具有可读性,便于调试。
- 排序: 按路径字符串排序通常能自然地得到正确的树形顺序。
❌ 缺点
- 存储开销: 长路径可能占用大量存储空间。
- 字符串解析: 查询通常需要字符串操作函数,其性能可能低于整数比较。
📊 对比分析
选择合适的模型在很大程度上取决于您的读写比例以及层级的深度。下表概述了每种方法的特性。
| 特性 | 邻接列表 | 嵌套集 | 物化路径 |
|---|---|---|---|
| 读取性能 | 低到中等 | 高 | 中等到高 |
| 写入性能 | 高 | 低 | 中等 |
| 实现复杂度 | 低 | 高 | 中等 |
| 支持深层树结构 | 是 | 是 | 是(有限制) |
| 查询逻辑 | 递归 | 范围扫描 | 前缀匹配 |
⚙️ 性能考虑
在建模层次结构时,必须考虑数据库引擎如何处理数据。无论选择哪种模型,索引策略都起着关键作用。
- 邻接列表: 对
parent_id列进行大量索引。这使得数据库能够快速定位特定节点的所有子节点,而无需扫描整个表。 - 嵌套集: 索引两者
lft和rgt。复合索引可以显著优化范围查询。 - 物化路径: 索引
path列。根据数据库的不同,前缀索引可能有助于过滤子树。
🛠️ 维护与更新
数据模型并非一成不变。随着组织的发展,你的层级结构将发生变化。将一个节点从一个分支移动到另一个分支是一种常见操作,但对每种模型的影响各不相同。
🔄 移动节点
在 邻接列表中,移动一个节点只需一条更新语句。你只需更改子树根节点的 parent_id 值。但必须确保不会产生循环引用。
在 嵌套集模型中,移动一个节点较为复杂。这需要重新计算目标子树中所有节点的 lft 和 rgt 值,以便为移动的节点腾出空间。这通常是一个涉及多次表更新的事务性操作。
在 物化路径模型中,你需要更新被移动节点及其所有后代的路径字符串。这要求为每个子节点更新路径,对于大型树来说,这可能是一个沉重的写操作。
🎯 数据建模的最佳实践
为了确保你的ERD保持可维护性和高性能,在实现层级结构时,请遵循以下指南。
- 使用清晰的命名规范: 避免使用像这样的通用名称
col1。使用parent_id,ancestor_id,lft,或rgt明确地使用。 - 强制约束: 使用数据库约束来防止循环引用。一个节点不能是其自身的祖先。
- 限制深度: 虽然在技术上是可行的,但极深的层级结构(例如超过10层)通常表明设计存在缺陷。如果可能,请考虑扁平化结构。
- 记录选择: 由于这些模式不是标准的SQL功能,应在模式文档中记录所使用的模式。
- 考虑混合方法: 某些系统将邻接列表与物化路径结合使用,以平衡读写性能。
🧠 选择正确的策略
并非每个场景都有唯一的“正确”答案。决策取决于您应用程序的具体需求。
- 如果: 您的数据频繁变化,且层级深度适中。这是大多数通用应用程序最安全的默认选择。
- 如果: 您的应用程序以读取为主,数据很少移动,并且需要快速检索大型子树。
- 如果: 您需要人类可读的路径(如URL),且层级深度相对较浅。
理解这些结构上的细微差别,有助于您设计可扩展的数据库。通过为实体关系图选择合适的模式,可以确保您的数据在整个系统生命周期中保持一致、可访问且高效。