











Designing a robust data model requires more than just defining relationships between tables. It involves anticipating how data evolves over time and ensuring that every modification is traceable. An audit trail within an Entity Relationship Diagram (ERD) serves as the backbone for accountability and data lineage. By explicitly modeling tracking mechanisms directly into the schema, organizations can maintain integrity without relying solely on external logging systems.
Why Track Data Changes? 📊
Implementing audit capabilities is not merely a technical preference; it is often a regulatory requirement. Industries handling sensitive information must demonstrate who accessed what data and when. Beyond compliance, audit trails provide critical debugging information during system failures. When a discrepancy appears in the data, historical records allow engineers to reconstruct the state of the database at any given point.
- Compliance: Regulations often mandate retention of change logs for specific periods.
- Security: Identifying unauthorized modifications or data breaches.
- Debugging: Tracing the source of data corruption or logic errors.
- Accountability: Knowing exactly which user or process initiated a record update.
Core Components of an Audit Schema 🏗️
When integrating audit trails into your ERD, specific columns must be present to capture the necessary metadata. These fields should be standardized across entities to ensure consistency in reporting and querying.
Essential Metadata Fields
Every auditable entity should include a set of foundational attributes. These fields record the lifecycle of the record.
- Record Identifier: A unique key to distinguish the specific record version.
- Created Timestamp: The exact date and time the record was inserted.
- Updated Timestamp: The last time the record was modified.
- Created By: The user ID or system process responsible for insertion.
- Updated By: The user ID or system process responsible for the last change.
- Operation Type: Indicates if the action was an insert, update, or delete.
Implementation Strategies 🛠️
There are several architectural approaches to modeling these changes. Each strategy offers different trade-offs regarding storage, query performance, and complexity. The choice depends on the specific needs of the application and the volume of data.
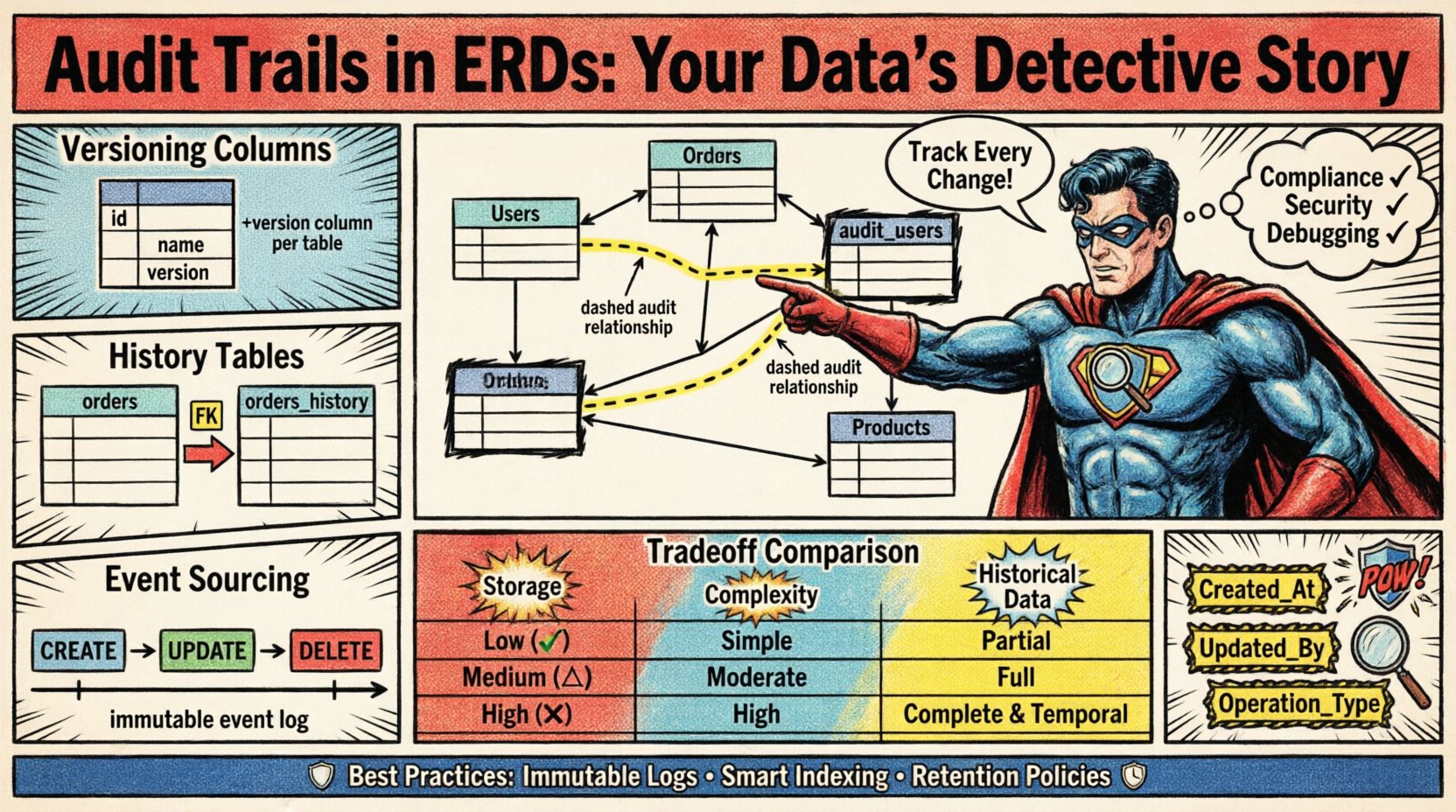
1. Versioning Columns (Soft Updates)
This approach involves adding audit columns directly to the main entity table. It is the simplest method to implement.
- Pros: Minimal schema changes; easy to query current state with history.
- Cons: Does not preserve historical snapshots; only shows the most recent change metadata.
2. Parallel History Tables
Instead of modifying the main table, changes are logged into a separate table linked by a foreign key. This allows for a complete history of every change.
- Pros: Clean separation of current data and history; full snapshot capability.
- Cons: Increased storage requirements; more complex queries requiring joins.
3. Event Sourcing
The entire state of the entity is reconstructed from a log of events. The database stores only the changes, not the current state.
- Pros: Complete auditability; immutable data source.
- Cons: High complexity in reconstruction logic; performance overhead during state calculation.
Designing the Relationships 🔗
The ERD must visually represent how the audit data relates to the business entities. A clear visual distinction helps developers understand the schema without reading documentation.
- One-to-Many: A single entity record can have many audit log entries.
- Foreign Keys: The audit table should reference the primary key of the source entity.
- Indexing: Foreign keys in the audit table must be indexed to speed up lookups.
When drawing the diagram, use dashed lines to indicate audit relationships. This distinguishes them from standard business logic relationships, such as customer orders or product inventories.
Comparative Analysis of Methods 📋
Selecting the right pattern requires understanding the operational context. The table below outlines the characteristics of common approaches.
| Feature | Versioning Columns | History Tables | Event Sourcing |
|---|---|---|---|
| Storage Overhead | Low | Medium | High |
| Query Complexity | Simple | Moderate | Complex |
| Historical Data | Metadata Only | Full Snapshots | Full Event Stream |
| Implementation Effort | Low | Medium | High |
Performance Considerations ⚡
Audit trails add write overhead to every transaction. As the volume of data grows, the impact on system performance becomes significant. Proper indexing and partitioning are necessary to mitigate latency.
- Indexing Strategy: Create indexes on the updated_by and updated_at columns. This facilitates rapid reporting on user activity.
- Partitioning: For high-volume systems, partition audit tables by date. This keeps active data in hot storage while moving older records to cold storage.
- Batch Processing: Instead of logging every micro-change, consider batching updates if real-time tracking is not strictly required.
Data Integrity and Security 🔒
Security is paramount when designing audit mechanisms. The audit trail itself must be protected from tampering. If an attacker can modify the logs, the system loses its credibility.
- Immutable Logs: Ensure that audit records cannot be deleted or altered by standard users.
- Access Control: Restrict write access to the audit tables to system processes or privileged accounts only.
- Validation: Ensure that user IDs referenced in audit logs actually exist in the user directory.
Maintenance and Lifecycle 🔄
Data retention policies dictate how long audit information must be kept. Storing this data indefinitely is inefficient and costly. A defined lifecycle management plan is essential.
- Archiving: Move records older than a specific threshold to a separate archive database.
- Purging: Automatically delete records that have exceeded legal retention requirements.
- Monitoring: Set up alerts for audit table growth rates to prevent storage exhaustion.
Best Practices for Schema Naming 📝
Consistent naming conventions reduce confusion during development and maintenance. Adhering to a standard naming pattern ensures that audit columns are easily identifiable across the entire system.
- Prefixes: Use prefixes like
audit_or_logfor table names. - Timestamps: Use
_atsuffixes for time columns (e.g.,created_at). - Identifiers: Use
_bysuffixes for user references (e.g.,updated_by). - Foreign Keys: Name keys explicitly (e.g.,
source_entity_id) to clarify the relationship.
By integrating these practices into the Entity Relationship Diagram, developers create a system that is transparent and resilient. The diagram becomes a living document that guides not just data storage, but the governance of that data throughout its existence.
Conclusion 📌
Building an audit trail into the data model is a foundational step for modern data architecture. It transforms a static diagram into a dynamic tool for governance. Whether using versioning columns or dedicated history tables, the goal remains the same: to ensure that every action within the system is recorded and retrievable. Careful planning of relationships, indexing, and retention policies ensures that the audit capability supports the business without hindering performance.