










Khi lượng dữ liệu tích lũy tăng nhanh, kiến trúc lược đồ cơ sở dữ liệu của bạn trở thành yếu tố then chốt quyết định sự ổn định của hệ thống. Khi một ứng dụng chuyển từ các thao tác đọc dữ liệu nặng sang các tác vụ ghi dữ liệu nặng, sơ đồ quan hệ thực thể (ERD) tiêu chuẩn thường đòi hỏi sự điều chỉnh đáng kể. Thiết kế để đạt hiệu suất cao không chỉ đơn thuần là thêm chỉ mục; nó đòi hỏi phải suy nghĩ lại căn bản về cách dữ liệu được cấu trúc, liên kết và lưu trữ. Hướng dẫn này khám phá những thay đổi kiến trúc cần thiết để duy trì hiệu suất dưới áp lực mà không làm tổn hại đến tính toàn vẹn dữ liệu.
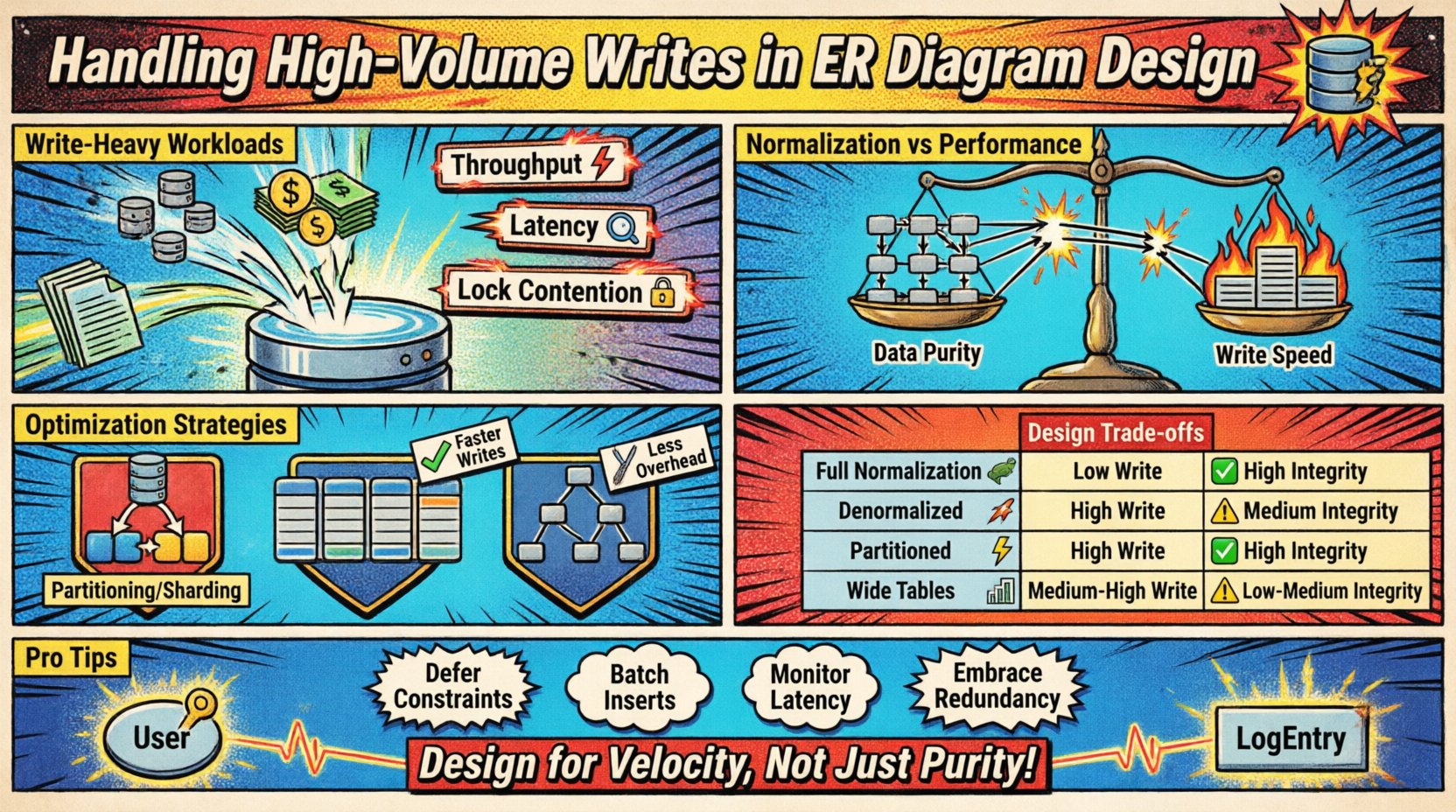
Hiểu rõ các tác vụ ghi dữ liệu nặng 📈
Các tình huống ghi dữ liệu khối lượng lớn xảy ra khi tốc độ dữ liệu đầu vào vượt quá khả năng của các kỹ thuật chuẩn hóa thông thường. Điều này thường xảy ra trong các hệ thống ghi nhật ký, luồng dữ liệu cảm biến IoT, sổ ghi chép giao dịch tài chính hoặc các nền tảng phân tích thời gian thực. Thách thức chính nằm ở việc cân bằng tốc độ chèn dữ liệu với các yêu cầu bảo toàn tính nhất quán của mô hình.
- Tốc độ xử lý: Số lượng thao tác ghi được xử lý mỗi giây.
- Độ trễ: Thời gian cần thiết để lưu trữ thành công một bản ghi.
- Cạnh tranh khóa: Cạnh tranh về tài nguyên khi nhiều tiến trình cùng cố gắng thay đổi cùng một dữ liệu.
Khi các chỉ số này suy giảm, chính lược đồ thường là điểm nghẽn. Một thiết kế cứng nhắc được tối ưu hóa cho các truy vấn phức tạp có thể sụp đổ dưới áp lực của các cập nhật liên tục. Do đó, sơ đồ ERD ban đầu phải tính đến tốc độ nhập dữ liệu.
Chuẩn hóa so với các thỏa hiệp hiệu suất ⚖️
Thiết kế cơ sở dữ liệu truyền thống khuyến khích chuẩn hóa (1NF, 2NF, 3NF) để giảm thiểu sự trùng lặp. Mặc dù điều này tiết kiệm không gian lưu trữ và đảm bảo tính nhất quán, nhưng nó lại tạo ra chi phí bổ sung trong các thao tác ghi. Mỗi mối quan hệ khóa ngoại đều yêu cầu tra cứu và kiểm tra nối để duy trì tính toàn vẹn tham chiếu.
Trong môi trường khối lượng lớn, các kiểm tra này trở nên tốn kém. Hãy xem xét hệ quả của mối quan hệ nhiều – nhiều trong một sự kiện ghi:
- Bảng chính phải được cập nhật.
- Bảng liên kết phải chèn một bản ghi mới.
- Bảng thứ hai phải xác minh mối quan hệ.
- Nhật ký giao dịch phải ghi lại tất cả các thay đổi.
Mỗi bước đều làm tăng I/O đĩa và chu kỳ CPU. Để xử lý tải ghi nặng, các nhà thiết kế thường nới lỏng các quy tắc chuẩn hóa. Quá trình này bao gồm việc chấp nhận sự trùng lặp dữ liệu nhằm giảm số lượng thao tác ghi cần thiết để lưu trữ một đơn vị thông tin.
Chiến lược tối ưu hóa tốc độ ghi ✍️
Một số mẫu cấu trúc tồn tại để giảm áp lực ghi. Các chiến lược này tập trung vào việc tối thiểu hóa kích thước mỗi giao dịch và giảm độ phức tạp công việc của bộ động cơ lưu trữ.
1. Chia tách và phân mảnh
Chia một bảng lớn thành các phần nhỏ hơn, dễ quản lý hơn cho phép cơ sở dữ liệu phân phối tải ghi trên nhiều đoạn vật lý hoặc logic khác nhau.
- Chia tách ngang: Chia các hàng dựa trên một khóa (ví dụ: khoảng thời gian ngày, ID người dùng).
- Chia tách dọc: Di chuyển các cột ít được truy cập sang các bảng riêng biệt.
- Phân mảnh: Phân phối dữ liệu trên nhiều phiên bản cơ sở dữ liệu.
Cách tiếp cận này làm giảm kích thước các chỉ mục cần được duy trì và giới hạn phạm vi khóa trong quá trình ghi. Nếu một mảnh bị quá tải, các mảnh khác vẫn không bị ảnh hưởng.
2. Chiến lược phi chuẩn hóa
Lưu trữ dữ liệu trùng lặp cho phép hệ thống tránh các thao tác nối (join) trong quá trình ghi. Ví dụ, thay vì tính tổng từ các hàng liên quan mỗi khi một giao dịch mới đến, hệ thống có thể cập nhật trực tiếp cột tổng hợp đã được tính toán trước.
- Cột tính toán: Lưu trữ các giá trị được suy ra trực tiếp trong hàng.
- Các view đã được vật chất hóa: Tính toán trước kết quả cho các phép tổng hợp thường xuyên.
- Bộ đệm bộ đếm: Duy trì một bảng đếm riêng biệt cho thống kê.
Mặc dù điều này làm tăng yêu cầu lưu trữ, nhưng nó làm giảm đáng kể chi phí CPU khi chèn dữ liệu.
3. Chiến lược chỉ mục
Chỉ mục làm tăng tốc độ đọc nhưng làm chậm thao tác ghi. Mỗi khi một hàng được chèn, cơ sở dữ liệu phải cập nhật mọi chỉ mục liên quan. Trong môi trường ghi dữ liệu cao, hiện tượng bloat chỉ mục trở thành vấn đề lớn.
- Tối thiểu hóa số lượng chỉ mục: Chỉ chỉ mục các cột được sử dụng để lọc hoặc nối.
- Chỉ mục từng phần: Chỉ chỉ mục một tập hợp con các hàng thường được truy cập.
- Tránh chỉ mục hóa quá mức: Bỏ qua việc chỉ mục các cột thay đổi thường xuyên.
So sánh các phương pháp thiết kế 📑
Bảng dưới đây nêu rõ ảnh hưởng của các lựa chọn cấu trúc khác nhau đến hiệu suất ghi và tính toàn vẹn dữ liệu.
| Chiến lược | Hiệu suất ghi | Tính toàn vẹn dữ liệu | Chi phí lưu trữ | Trường hợp sử dụng tốt nhất |
|---|---|---|---|---|
| Chuẩn hóa đầy đủ | Thấp | Cao | Thấp | Báo cáo phức tạp, khối lượng ghi thấp |
| Phi chuẩn hóa | Cao | Trung bình | Cao | Dòng dữ liệu thời gian thực, khối lượng ghi cao |
| Cấu trúc phân vùng | Cao | Cao | Trung bình | Dữ liệu chuỗi thời gian, tập dữ liệu lớn |
| Bảng rộng | Trung bình – Cao | Trung bình | Trung bình | Mô hình NoSQL, dữ liệu thưa |
Xử lý khóa ngoại và ràng buộc 🔗
Tính toàn vẹn tham chiếu là nền tảng của thiết kế quan hệ, nhưng việc áp dụng ràng buộc cho mỗi thao tác chèn có thể làm nghẽn luồng dữ liệu tốc độ cao. Động cơ cơ sở dữ liệu phải xác minh rằng hàng cha được tham chiếu tồn tại trước khi chấp nhận hàng con.
Trong các tình huống mà tính toàn vẹn dữ liệu là quan trọng nhưng tốc độ ghi là ưu tiên hàng đầu, hãy cân nhắc những điều chỉnh sau:
- Ràng buộc hoãn lại:Xác minh các mối quan hệ vào cuối giao dịch thay vì ngay lập tức.
- Kiểm tra ở cấp độ ứng dụng:Xác minh các mối quan hệ trong mã ứng dụng trước khi gửi dữ liệu đến cơ sở dữ liệu.
- Xóa mềm:Ghi chú các bản ghi là không hoạt động thay vì xóa chúng để duy trì các liên kết tham chiếu mà không cần chi phí xóa.
Loại bỏ hoàn toàn ràng buộc là rủi ro, nhưng di chuyển logic xác thực đôi khi có thể cải thiện băng thông. Quyết định phụ thuộc vào mức độ quan trọng của sự nhất quán tức thì đối với quy trình cụ thể của bạn.
Tăng cường ghi và bộ động cơ lưu trữ 💾
Hiểu cách bộ động cơ lưu trữ xử lý dữ liệu là rất quan trọng. Nhiều bộ động cơ sử dụng Nhật ký Ghi trước (WAL) để đảm bảo độ bền. Điều này có nghĩa là mỗi thao tác ghi đều được ghi lại trước khi được áp dụng vào các tệp dữ liệu thực tế.
Tăng cường ghixảy ra khi một thao tác ghi logic duy nhất dẫn đến nhiều thao tác ghi vật lý. Điều này phổ biến trong các bộ động cơ lưu trữ có nhiều thao tác hợp nhất. Để quản lý điều này:
- Chèn hàng loạt:Gom nhiều hàng vào một giao dịch duy nhất.
- Ghi tuần tự:Thiết kế các lược đồ để ưu tiên sinh khóa tuần tự thay vì chèn ngẫu nhiên.
- Đệm:Cho phép một bộ đệm tạm thời ở lớp ứng dụng để xếp hàng các thao tác ghi trước khi xả dữ liệu.
Bằng cách đồng bộ hóa thiết kế ERD với điểm mạnh của bộ động cơ lưu trữ, bạn có thể giảm thiểu nỗ lực vật lý cần thiết để duy trì dữ liệu.
Giám sát và lặp lại 🔄
Một lược đồ được thiết kế cho ghi dữ liệu ở quy mô lớn không phải là cố định. Khi mẫu lưu lượng thay đổi, thiết kế có thể cần thay đổi. Việc giám sát liên tục độ trễ ghi và I/O đĩa là thiết yếu.
- Theo dõi độ trễ ghi:Phát hiện các đỉnh tăng đột biến cho thấy các điểm nghẽn.
- Giám sát thời gian chờ khóa:Phát hiện các điểm cạnh tranh nơi các tiến trình bị chặn.
- Phân tích sử dụng chỉ mục:Loại bỏ các chỉ mục không bao giờ được sử dụng để giảm chi phí ghi dữ liệu.
Việc kiểm tra định kỳ ERD đảm bảo cấu trúc vẫn phù hợp với nhu cầu vận hành hiện tại. Nếu một bảng cụ thể liên tục gặp khó khăn với băng thông ghi, có thể đã đến lúc xem xét lại chiến lược phân vùng hoặc mức độ chuẩn hóa.
Tóm tắt các yếu tố quan trọng cần xem xét 🛠️
Thiết kế ERD cho ghi dữ liệu ở quy mô lớn đòi hỏi sự thay đổi tư duy từ sự thuần khiết dữ liệu thuần túy sang hiệu suất hệ thống. Các điểm sau tóm tắt các hành động thiết yếu:
- Kiểm tra chuẩn hóa:Đảm bảo rằng mỗi mối quan hệ mang lại giá trị thay vì chỉ tạo ra độ phức tạp.
- Lên kế hoạch cho phân vùng:Cấu trúc khóa để cho phép chia nhỏ theo chiều ngang một cách dễ dàng.
- Hạn chế chỉ mục:Giữ con đường ghi dữ liệu càng gọn nhẹ càng tốt.
- Chấp nhận sự dư thừa:Sử dụng thao tác phi chuẩn hóa để giảm phụ thuộc vào thao tác nối khi chèn dữ liệu.
- Xác thực từng bước:Chuyển kiểm tra ràng buộc ra khỏi con đường ghi quan trọng khi an toàn.
Bằng cách áp dụng các nguyên tắc này, bạn tạo ra một mô hình dữ liệu có khả năng duy trì sự phát triển mà không hy sinh hiệu suất. Mục tiêu không phải là loại bỏ độ phức tạp, mà là quản lý nó theo cách hỗ trợ tốc độ phát triển của ứng dụng của bạn.