











Проектирование надежной базы данных начинается задолго до первого выполнения запроса. Все начинается с эскиза: диаграммы сущность-связь (ERD). 📐 Хотя многие разработчики сосредоточены на создании таблиц и типах столбцов, настоящий двигатель производительности заключается в том, как индексы согласуются с вашей моделью данных. Индексация — это не просто настройка конфигурации; это физическое воплощение ваших логических связей.
Когда вы структурируете свою ERD, вы определяете кардинальность и связность ваших данных. Эти структурные решения определяют наиболее эффективные стратегии индексации. Один к одному требует другого подхода, чем связь многие ко многим. Пренебрежение этими нюансами часто приводит к медленным соединениям, чрезмерному вводу-выводу и фрагментации хранилища. В этом руководстве рассматривается, как преобразовать вашу ERD в высокопроизводительные шаблоны индексации без использования специфических инструментов производителя.
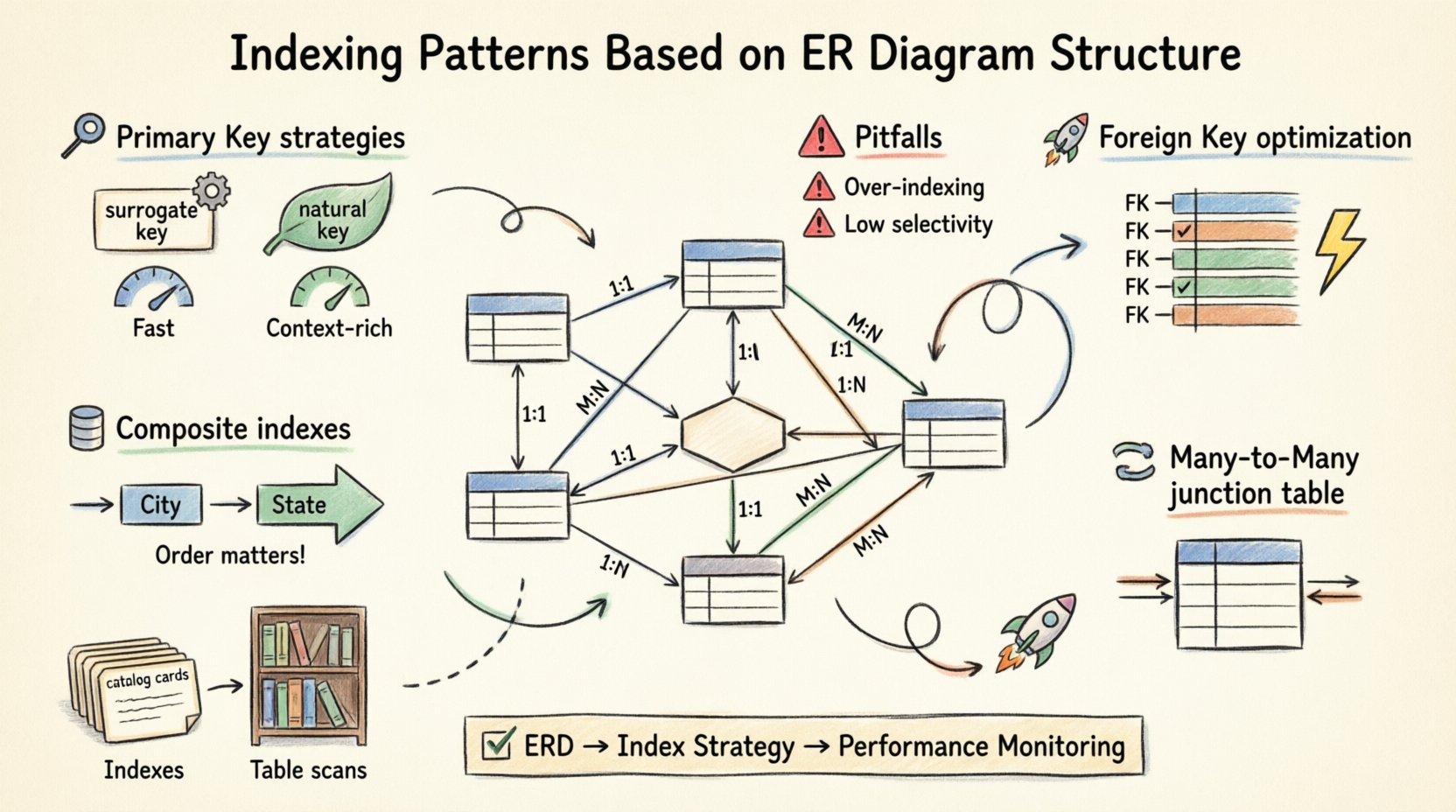
🔑 Понимание основ: ERD и индексация
ERD — это больше, чем визуальная подсказка; это контракт между логикой вашего приложения и движком хранения. Каждая линия, проведенная между сущностями, представляет собой ограничение, которое база данных должна соблюдать. Индексы служат для ускорения соблюдения этих ограничений и извлечения данных через них.
Представьте слой хранения данных как библиотеку. Без индекса поиск книги требует просмотра каждой полки (полное сканирование таблицы). Индекс — это карточка каталога. Однако неправильное размещение карточек — например, по жанру вместо автора, когда авторы являются основным ключом поиска — делает систему неэффективной. Ваша ERD показывает, кто является авторами и жанрами, и какие связи наиболее важны.
Ключевые моменты включают:
- Кардинальность: Столбцы с высокой кардинальностью (уникальные значения) наиболее выгодно индексировать.
- Частота соединений: Таблицы, которые часто соединяются, требуют специальной индексации по внешним ключам.
- Объем записей: Каждый индекс добавляет накладные расходы на операции вставки и обновления.
- Шаблоны запросов: Как вы фильтруете? Как вы сортируете? ERD намекает на ответ.
🏗️ Стратегии индексации первичного ключа
Первичный ключ (PK) — это основа каждой таблицы. Он гарантирует уникальность и обеспечивает механизм кластеризации для хранения данных во многих системах. Согласование вашей индексации с определением первичного ключа — это первый шаг.
1. Суррогатные ключи против естественных ключей
Выбор между суррогатным ключом (автоинкрементный ID) и естественным ключом (например, электронная почта или номер социального страхования) значительно влияет на производительность индексации.
- Суррогатные ключи: Они идеально подходят для кластеризации. Они короткие, монотонно возрастающие и последовательные. Это минимизирует разделение страниц и фрагментацию при записи. 📈
- Естественные ключи: Хотя они семантически значимы, они могут быть длинными, переменной длины или подвержены изменениям. Индексация таких ключей может привести к увеличению размера индекса и замедлению поиска по сравнению с целочисленными ключами.
2. Последствия кластеризованного индекса
В большинстве архитектур первичный ключ определяет кластеризованный индекс. Это означает, что фактические строки данных физически хранятся в порядке ключа. Если ваша ERD указывает, что запросы часто фильтруются по определенному естественному атрибуту, вам может потребоваться пересмотреть определение первичного ключа или принять, что кластеризованный индекс будет оптимизирован под один тип запросов, а вторичные индексы будут обрабатывать остальные.
🔗 Оптимизация внешнего ключа
Внешние ключи (FK) определяют отношения между таблицами. Они являются наиболее распространенным источником производительностных узких мест, если не индексированы. При соединении двух таблиц движок базы данных должен сопоставлять строки на основе столбца внешнего ключа. Без индекса эта операция сводится к вложенному циклу, что является вычислительно затратным для больших наборов данных.
1. Индексация столбца внешнего ключа
Всегда создавайте индекс на столбце внешнего ключа в дочерней таблице. Это позволяет движку быстро находить связанные строки, не сканируя всю таблицу.
| Сценарий | Требование индексации | Влияние на производительность |
|---|---|---|
| Один ко многим (дочерняя таблица) | Индекс внешнего ключа в дочерней таблице | Позволяет быстро выполнять поиск данных родительской таблицы |
| Многие к одному (родительская таблица) | Индекс первичного ключа в родительской таблице (обычно по умолчанию) | Стандартное поведение первичного ключа |
| Каскадное удаление | Индекс внешнего ключа + первичного ключа родителя | Предотвращает блокировку всей таблицы при удалении |
2. Составные внешние ключи
Иногда связь зависит от нескольких столбцов (например, составной ключ из родительской таблицы). В этом случае необходимо создать составной индекс в дочерней таблице, соответствующий порядку и столбцам родительского ключа. Несоответствие порядка столбцов в индексе может сделать его бесполезным для операций соединения.
🔀 Обработка отношений «многие ко многим»
Отношения «многие ко многим» (M:N) разрешаются с помощью промежуточной таблицы. Эта таблица содержит внешние ключи, указывающие на обе родительские таблицы. Стратегия индексации здесь критически важна для производительности.
Рассмотрим ситуацию, когдаСтуденты записываются на Курсы. Промежуточная таблица связывает их. Чтобы найти все курсы для студента, необходимо эффективно запросить промежуточную таблицу.
- Индексация в обоих направлениях: Вы должны индексировать оба столбца внешнего ключа независимо. Это позволяет выполнять запросы по отношению с любого из двух направлений (Студент → Курсы или Курс → Студенты) без полного сканирования.
- Составная индексация: Если ваши запросы всегда извлекают курсы конкретного студента, составной индекс на (Student_ID, Course_ID) будет более эффективным, чем два отдельных индекса. Он охватывает критерии поиска за один запрос.
📊 Составные и покрывающие индексы
Не все запросы фильтруют по одному столбцу. Сложные запросы часто включают несколько условий. Именно здесь проявляется преимущество составных индексов. Составной индекс — это один индекс, созданный на нескольких столбцах.
1. Порядок столбцов имеет значение
Порядок столбцов в составном индексе не произволен. Движок базы данных может использовать индекс только до точки, где заканчиваются условия равенства. Например, если вы индексируете (Город, Штат), запрос, фильтрующий по Городу, будет использовать индекс. Запрос, фильтрующий только по Штату, вероятно, его проигнорирует.
2. Покрывающие индексы
Покрывающий индекс включает все столбцы, необходимые для выполнения запроса, включая список SELECT. Это позволяет базе данных получать данные непосредственно из дерева индекса, не обращаясь к основной таблице (куче). Это огромный выигрыш по производительности для операций, интенсивно читающих данные.
⚠️ Распространенные ошибки и лучшие практики
Даже при идеальном ERD ошибки реализации могут снижать производительность. Ниже перечислены распространенные ловушки, которые следует избегать при преобразовании структуры в хранилище.
- Чрезмерное индексирование: Каждый индекс потребляет место на диске и замедляет операции записи. Индексируйте только те столбцы, которые часто запрашиваются или используются для ограничений.
- Низкая выборочность: Индексирование столбца с низкой кардинальностью (например, булевского флага «is_active») часто неэффективно. Оптимизатор может решить, что полное сканирование таблицы быстрее, чем переход к индексу.
- Пренебрежение NULL: Индексы обрабатывают значения NULL по-разному в зависимости от движка. Убедитесь, что ваша логика запросов учитывает, как NULL-значения индексируются в вашей конкретной конфигурации.
- Фрагментация: Со временем индексы становятся фрагментированными. Для поддержания оптимальной производительности требуется регулярное обслуживание.
🛠️ Мониторинг производительности и обслуживание
Как только ваша стратегия индексации будет реализована, мониторинг становится обязательным. Вы не можете оптимизировать то, что не измеряете. Регулярно анализируйте планы выполнения запросов, чтобы убедиться, что ваши индексы используются эффективно.
1. Анализируйте планы выполнения
Обращайте внимание на операции, такие как «сканирование индекса» против «поиска по индексу». Поиск по индексу эффективен, сканирование — нет. Если вы видите полные сканирования таблиц на больших таблицах, пересмотрите свою стратегию индексации на основе реальных шаблонов запросов.
2. Отслеживайте использование индексов
Иногда индексы создаются, но никогда не используются. Это бесполезная нагрузка. Регулярно проверяйте статистику использования индексов, чтобы выявить неиспользуемые индексы, которые можно удалить для улучшения производительности записи.
3. Учет роста данных
По мере роста ваших данных возрастает стоимость обслуживания. Индекс, который работает нормально при 10 000 строках, может стать узким местом при 10 миллионах строк. Пересмотрите свои паттерны индексации, выведенные из ERD, по мере масштабирования набора данных. Вместе с индексацией могут потребоваться также стратегии партиционирования.
🔄 Обобщение согласованности
Согласование вашей стратегии индексации с архитектурой ERD — это непрерывный процесс. Требуется понимание связей между данными, определенных в вашем проекте, и их преобразование в оптимизации физического хранения.
- Первичные ключи: Используйте для кластеризации и обеспечения уникальности.
- Внешние ключи: Индексируйте для повышения производительности соединений.
- Таблицы-связки:Двустороннее индексирование для отношений М:Н.
- Шаблоны запросов:Настройте составные индексы под конкретные порядки фильтрации.
Соблюдая структурную целостность вашего ERD, вы создаете базу данных, которая масштабируется плавно. Вы избегаете распространенных ошибок случайной индексации и обеспечиваете доступность и производительность данных по мере развития вашего приложения. Такой дисциплинированный подход гарантирует, что база данных поддерживает вашу бизнес-логику, не становясь узким местом. 🚀