











Диаграммы сущностей и связей (ERD) служат чертежом архитектуры базы данных. Они определяют, как данные структурируются, хранятся и извлекаются в системе. Когда эти диаграммы содержат недостатки, последствия выходят далеко за рамки этапа разработки. Ошибки в производственной среде могут привести к повреждению данных, узким местам производительности и значительным финансовым потерям. Понимание распространённых ошибок необходимо для поддержания целостности системы.
Многие команды спешат с этапом моделирования, ставя скорость выше точности. Такая спешка часто приводит к проблемам со схемой, которые трудно устранить после начала потока данных. Надёжный дизайн требует тщательного рассмотрения отношений, типов данных и ограничений. Ниже мы рассмотрим наиболее распространённые недостатки проектирования и их технические последствия.
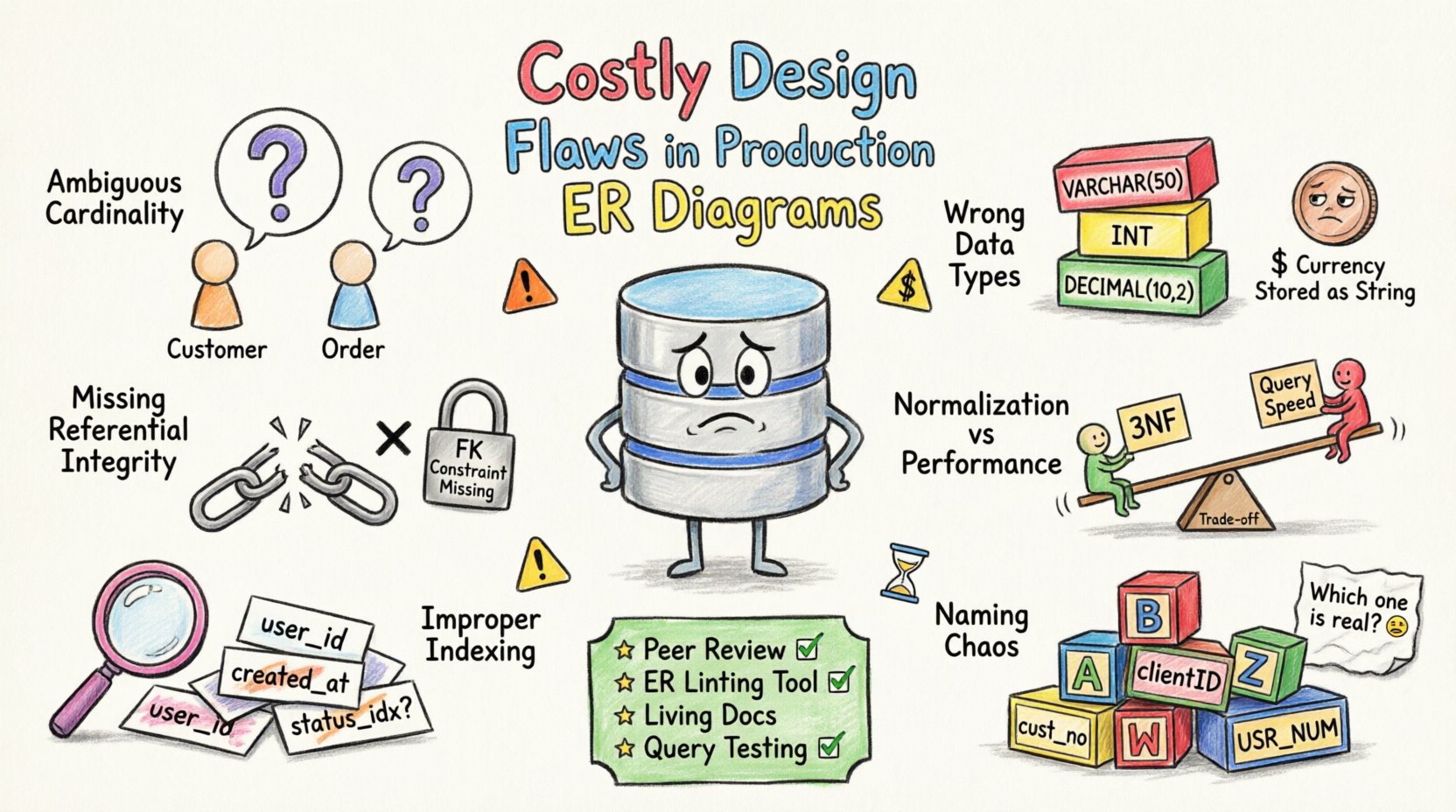
1. Неоднозначная кардинальность и отношения 🔗
Кардинальность определяет числовое отношение между сущностями. Неправильная кардинальность приводит к логическим ошибкам при извлечении и хранении данных. Распространённая ошибка — предположение, что существует отношение один к одному, хотя на самом деле оно одно ко многим.
- Пропуск отношений многие ко многим:Отсутствие создания промежуточной таблицы для отношений многие ко многим вынуждает к дублированию данных или сложным запросам объединения.
- Неопределённые внешние ключи:Без явных внешних ключей база данных не может обеспечить целостность ссылок, что позволяет существовать «сиротским» записям.
- Опциональные vs. Обязательные:Неправильная классификация обязательного отношения как опционального приводит к появлению значений null в тех местах, где ожидается наличие данных.
Например, рассмотрим клиента и заказ. Если диаграмма предполагает, что клиент может существовать без заказа, но логика приложения требует его наличия, база данных будет хранить неполные профили. Такое расхождение приводит к сбоям приложения или несогласованной отчётности.
2. Несогласованный выбор типов данных 📊
Типы данных определяют, как информация хранится и обрабатывается. Неправильный выбор типа приводит к неоправданному потреблению хранилища или ограничению диапазона значений. Проблемы с точностью часто возникают при использовании чисел с плавающей точкой для хранения денежных сумм.
- Переполнение целых чисел:Использование малых целых чисел для идентификаторов может привести к ошибкам переполнения по мере роста объёма данных.
- Длина текста:Использование полей фиксированной длины для текста приводит к потере места при хранении данных переменной длины.
- Точность даты:Хранение дат без часовых поясов создаёт проблемы синхронизации в распределённых системах.
Выбор универсального текстового поля для номеров телефонов — ещё одна распространённая ошибка. Это позволяет вводить недопустимые символы в систему, усложняя логику проверки позже. Числовые поля следует использовать для расчётов, а текстовые — только для буквенно-цифровых данных.
3. Отсутствие ограничений целостности ссылок 🔒
Целостность ссылок обеспечивает, чтобы отношения между таблицами оставались согласованными. Без этих ограничений база данных полагается на код приложения для поддержания точности данных, что подвержено человеческим ошибкам.
- Отсутствие правил каскадного удаления:Удаление родительской записи без правил каскадного удаления оставляет дочерние записи висящими в базе данных.
- Отсутствующие ограничения:Зависимость от проверки на уровне приложения вместо ограничений базы данных недостаточна.
- Мягкое удаление:Неправильная обработка удалённых записей создаёт беспорядок и замедляет производительность запросов.
Когда ограничения отсутствуют, целостность данных полностью зависит от разработчиков приложения. Если ошибка позволяет прямую запись в базу данных, несогласованность становится постоянной. Это одна из основных причин повреждения данных в долгосрочных производственных системах.
4. Нормализация против компромиссов производительности ⚖️
Нормализация уменьшает избыточность, но может увеличить сложность запросов. Избыточная нормализация приводит к чрезмерному количеству соединений, а недостаточная нормализация вызывает аномалии обновления. Нахождение баланса имеет решающее значение для производительности.
- Третья нормальная форма (3NF): Часто идеально подходит для транзакционных систем, но может потребовать денормализации при высокой нагрузке на чтение.
- Денормализация: Введение избыточности ради производительности должно быть документировано, чтобы избежать конфликтов обновления.
- Сложность запросов: Глубоко нормализованные схемы требуют сложных соединений, которые нагружают движок базы данных.
Команды часто нормализуют до крайности, чтобы обеспечить чистоту данных, игнорируя стоимость соединения нескольких таблиц. В условиях высокой нагрузки это приводит к медленным временам отклика. Стратегическая денормализация может улучшить производительность чтения, при условии правильного управления операциями записи.
5. Неправильная стратегия индексации 🏷️
Индексы ускоряют извлечение данных, но замедляют операции записи. Некорректная ERD часто не учитывает, как будут запрашиваться данные. Это приводит к полным сканированиям таблиц и высокой задержке.
- Отсутствующие индексы внешних ключей: Соединения по неиндексированным столбцам являются вычислительно затратными.
- Чрезмерная индексация: Слишком много индексов увеличивает задержку записи и требования к хранилищу.
- Порядок столбцов в составном индексе: Неправильный порядок столбцов в составных индексах делает их неэффективными.
Индекс на часто запрашиваемом столбце — стандартная практика. Однако игнорирование паттернов запросов на этапе проектирования приводит к неэффективным путям доступа. Регулярный анализ планов выполнения запросов необходим для корректировки стратегий индексации.
6. Хаос в соглашениях об именовании 🏷️
Последовательные соглашения об именовании имеют решающее значение для поддержки. Несогласованные имена таблиц и столбцов делают схему трудной для понимания и модификации.
- Смешанный регистр: Использование camelCase в одних местах и snake_case в других вызывает путаницу.
- Неоднозначные сокращения: Короткие имена, такие как «cust» или «ord», неясны для новых членов команды.
- Зарезервированные ключевые слова: Использование зарезервированных слов в качестве имён таблиц вызывает синтаксические ошибки в запросах.
Четкое именование снижает когнитивную нагрузку на разработчиков и администраторов баз данных. Это также способствует автоматической генерации документации и снижает вероятность опечаток в SQL-запросах.
Анализ последствий распространённых недостатков
| Недостаток в проектировании | Техническое воздействие | Стоимость бизнеса |
|---|---|---|
| Отсутствующие внешние ключи | Оставленные записи, несогласованность данных | Потеря данных, нарушения соответствия |
| Неправильные типы данных | Бесполезное использование хранилища, ошибки вычислений | Финансовые расхождения, ошибки отчетности |
| Избыточная нормализация | Медленная производительность запросов, высокая задержка | Медленный пользовательский опыт, потеря доходов |
| Отсутствующие индексы | Полные сканирования таблиц, конкуренция за блокировки базы данных | Простой системы, плохая масштабируемость |
| Плохое наименование | Высокая нагрузка на обслуживание, высокая частота ошибок | Увеличение времени разработки, ошибки |
Стратегии предотвращения 🛡️
Предотвращение этих недостатков требует дисциплиниров подход к проектированию базы данных. Следующие шаги помогают снизить риски до развертывания.
- Рецензирование коллегами: Внедрите обязательную проверку схемы перед слиянием любых изменений.
- Автоматизированная проверка стиля: Используйте инструменты для проверки соблюдения правил именования и структурных стандартов.
- Документация: Поддерживайте актуальные диаграммы ERD, отражающие фактическую схему.
- Тестирование: Запускайте тесты валидации схемы в среде тестирования перед производственным развертыванием.
Принятие процесса контроля версий для схем баз данных гарантирует, что изменения отслеживаются и могут быть отменены. Это позволяет командам определить, когда был введен недостаток, и откатиться, если необходимо. Сотрудничество между разработчиками и архитекторами необходимо для раннего выявления проблем.
Рассмотрение долгосрочного обслуживания 🔄
Схемы баз данных со временем эволюционируют. Проект, который работает сегодня, может не соответствовать будущим требованиям. Регулярные аудиты помогают выявить технический долг и устаревшие паттерны.
- Отклонение схемы: Отслеживайте различия между ERD и рабочей базой данных.
- Устаревание: Планируйте удаление неиспользуемых таблиц и столбцов.
- Масштабируемость: Проектируйте с учётом разделения и шардинга для больших наборов данных.
Пренебрежение обслуживанием приводит к хрупкой системе, сопротивляющейся изменениям. Прогнозируемое управление гарантирует, что база данных останется надёжной основой для приложения. Вложение времени в начальную разработку окупается на протяжении всего жизненного цикла программного обеспечения.
Заключительные мысли о целостности схемы 📝
Ошибки в рабочей базе данных часто являются результатом упущенных деталей на этапе проектирования. Учитывая кардинальность, типы данных, ограничения и индексацию, команды могут создавать более устойчивые системы. Стоимость исправления ошибки в рабочей среде значительно выше, чем предотвращение её на этапе моделирования.
Сосредоточьтесь на ясности, согласованности и проверке. Хорошо структурированный ERD — основа надёжности данных. Отдавайте предпочтение качеству, а не скорости, чтобы обеспечить долгосрочную стабильность. Такой подход минимизирует риски и максимизирует ценность данных, хранящихся в системе.