











По мере ускорения накопления данных архитектура вашей схемы базы данных становится критическим фактором стабильности системы. Когда приложение переходит от операций, ориентированных на чтение, к операциям, ориентированным на запись, стандартная диаграмма сущность-связь (ERD) часто требует значительной корректировки. Проектирование для высокой пропускной способности требует не просто добавления индексов, а фундаментального переосмысления того, как структурируются, связываются и хранятся данные. В этом руководстве рассматриваются необходимые архитектурные изменения, которые требуются для поддержания производительности под нагрузкой без ущерба целостности данных.
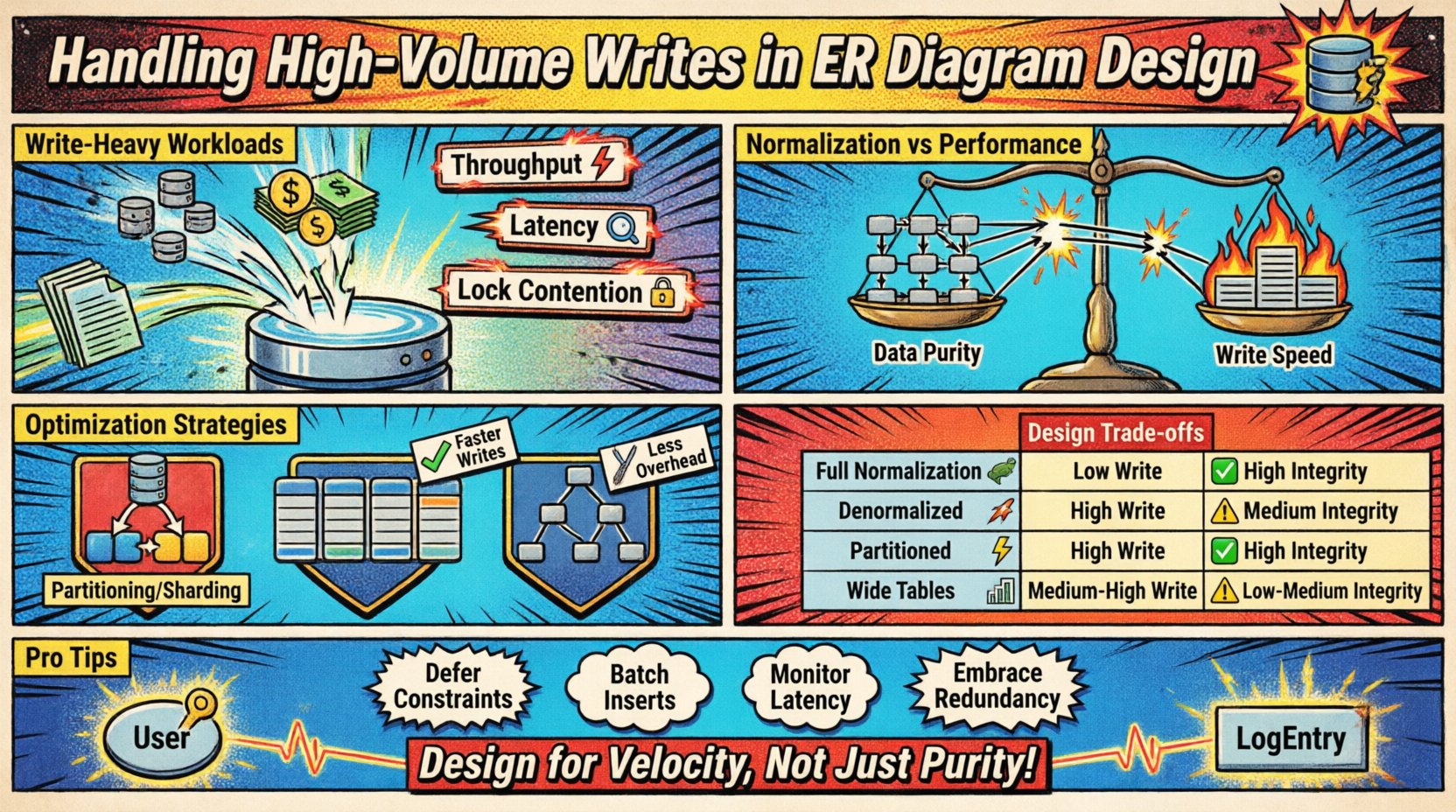
Понимание рабочих нагрузок, ориентированных на запись 📈
Сценарии с высоким объемом записей возникают, когда скорость поступления данных превышает возможности стандартных методов нормализации. Это часто происходит в системах ведения журналов, потоках данных с датчиков IoT, финансовых журналах транзакций или платформах аналитики в реальном времени. Основная проблема заключается в балансировке скорости вставки с требованиями к согласованности модели.
- Пропускная способность: Количество операций записи, обрабатываемых в секунду.
- Задержка: Время, необходимое для успешного сохранения записи.
- Конкуренция за блокировки: Конкуренция за ресурсы, когда несколько процессов пытаются изменить одни и те же данные.
Когда эти метрики ухудшаются, схема базы данных часто становится узким местом. Жесткая архитектура, оптимизированная для сложных запросов, может не выдержать постоянных обновлений. Следовательно, начальная ERD должна учитывать скорость ввода данных.
Нормализация против компромиссов производительности ⚖️
Традиционный дизайн базы данных поощряет нормализацию (1НФ, 2НФ, 3НФ) для уменьшения избыточности. Хотя это экономит место на диске и обеспечивает согласованность, при операциях записи вводит накладные расходы. Каждое отношение по внешнему ключу требует поиска и проверки соединения для поддержания целостности ссылок.
В среде с высоким объемом данных эти проверки становятся дорогостоящими. Рассмотрим последствия наличия отношения «многие ко многим» при операции записи:
- Основная таблица должна быть обновлена.
- Таблица-связка должна вставить новую строку.
- Вторая таблица должна проверить связь.
- Журналы транзакций должны зафиксировать все изменения.
Каждый шаг добавляет ввод-вывод на диск и циклы процессора. Чтобы справиться с высокой нагрузкой на запись, проектировщики часто ослабляют правила нормализации. Этот процесс предполагает принятие избыточности данных для уменьшения количества операций записи, необходимых для хранения единицы информации.
Стратегии оптимизации скорости записи ✍️
Существует несколько структурных паттернов для снижения нагрузки на запись. Эти стратегии направлены на минимизацию размера каждой транзакции и уменьшение сложности работы движка хранения.
1. Разделение и шардинг
Разделение большой таблицы на более мелкие, управляемые фрагменты позволяет базе данных распределять нагрузку на запись по нескольким физическим или логическим сегментам.
- Горизонтальное разделение: Разделение строк по ключу (например, диапазоны дат, идентификаторы пользователей).
- Вертикальное разделение: Перемещение редко используемых столбцов в отдельные таблицы.
- Шардинг: Распределение данных по нескольким экземплярам базы данных.
Этот подход уменьшает размер индексов, которые необходимо поддерживать, и ограничивает масштаб блокировок во время операции записи. Если один шард переполнится, другие останутся не затронутыми.
2. Тактики денормализации
Хранение избыточных данных позволяет системе избежать операций соединения при записи. Например, вместо того чтобы каждый раз вычислять итоговую сумму из связанных строк при поступлении новой транзакции, система может напрямую обновлять заранее вычисленный столбец итогов.
- Вычисляемые столбцы: Храните производные значения непосредственно в строке.
- Материализованные представления: Предварительно вычисляйте результаты для частых агрегаций.
- Кэшированные счётчики: Поддерживайте отдельную таблицу счётчиков для статистики.
Хотя это увеличивает требования к хранилищу, оно значительно снижает затраты ЦП при вставке.
3. Стратегия индексации
Индексы ускоряют чтение, но замедляют запись. Каждый раз при вставке строки база данных должна обновлять каждый связанный индекс. В средах с высокой нагрузкой на запись индексный «раздув» становится серьёзной проблемой.
- Минимизируйте количество индексов: Индексируйте только столбцы, используемые для фильтрации или соединения.
- Частичные индексы: Индексируйте только подмножество строк, которые часто используются.
- Избегайте чрезмерной индексации: Пропускайте индексы для столбцов, которые часто изменяются.
Сравнение подходов к проектированию 📑
В таблице ниже описано влияние различных структурных решений на производительность записи и целостность данных.
| Стратегия | Производительность записи | Целостность данных | Стоимость хранения | Лучшее применение |
|---|---|---|---|---|
| Полная нормализация | Низкая | Высокая | Низкая | Сложный отчёт, низкий объём записи |
| Денормализованная | Высокий | Средний | Высокий | Потоки в реальном времени, высокий объем записей |
| Разделенная схема | Высокий | Высокий | Средний | Данные временных рядов, большие наборы данных |
| Широкие таблицы | Средний-высокий | Средний | Средний | Паттерны NoSQL, разреженные данные |
Обработка внешних ключей и ограничений 🔗
Целостность ссылок является фундаментом реляционного проектирования, но принудительное применение ограничений при каждом вставке может замедлить высокоскоростной поток данных. Движок базы данных должен проверить наличие ссылочного родительского элемента перед принятием дочернего элемента.
В сценариях, когда целостность данных критически важна, но скорость записи имеет первостепенное значение, рассмотрите следующие настройки:
- Отложенные ограничения: Проверяйте связи в конце транзакции, а не сразу.
- Проверки на уровне приложения: Проверяйте связи в коде приложения перед отправкой данных в базу данных.
- Мягкое удаление: Отмечайте записи как неактивные, а не удаляйте их, чтобы сохранить ссылочные связи без накладных расходов на удаление.
Полное удаление ограничений опасно, но перенос логики проверки иногда может повысить пропускную способность. Решение зависит от того, насколько критична немедленная согласованность для вашей конкретной рабочей нагрузки.
Увеличение записи и движки хранения 💾
Понимание того, как движок хранения обрабатывает данные, имеет решающее значение. Многие движки используют журнал предварительной записи (WAL), чтобы обеспечить устойчивость. Это означает, что каждая запись фиксируется в журнале до применения к фактическим файлам данных.
Увеличение записи происходит, когда одна логическая операция записи приводит к нескольким физическим записям. Это распространено в движках хранения с интенсивной компактизацией. Чтобы управлять этим:
- Пакетные вставки: Объединяйте несколько строк в одну транзакцию.
- Последовательная запись:Проектируйте схемы, чтобы предпочитать последовательное генерирование ключей случайным вставкам.
- Буферизация:Позвольте временный буфер на уровне приложения для очереди записей перед их сбросом.
Согласовав проектирование ERD со сильными сторонами движка хранения, вы можете минимизировать физические усилия, необходимые для сохранения данных.
Мониторинг и итерации 🔄
Схема, разработанная для высоких объемов записей, не является статичной. По мере изменения паттернов трафика, проектирование может потребовать эволюции. Непрерывный мониторинг задержки записи и ввода-вывода на диск является обязательным.
- Отслеживайте задержку записи: Выявляйте пиковые значения, указывающие на узкие места.
- Мониторьте ожидание блокировок: Выявляйте точки конкуренции, где процессы заблокированы.
- Анализируйте использование индексов: Удаляйте индексы, которые никогда не используются, чтобы снизить накладные расходы на запись.
Регулярные аудиты ERD обеспечивают соответствие структуры текущим эксплуатационным требованиям. Если конкретная таблица постоянно испытывает трудности с пропускной способностью записи, возможно, пришло время пересмотреть стратегию партиционирования или уровень нормализации.
Краткий обзор ключевых соображений 🛠️
Проектирование ERD для высоких объемов записей требует смены мышления от чистоты данных к пропускной способности системы. Ниже приведены основные действия:
- Аудит нормализации: Убедитесь, что каждое отношение добавляет ценность, а не просто усложняет структуру.
- Планируйте партиционирование: Структурируйте ключи, чтобы обеспечить простое горизонтальное разделение.
- Ограничьте количество индексов: Держите путь записи как можно более легким.
- Принимайте избыточность: Используйте денормализацию для уменьшения зависимостей от соединений при вставке.
- Постепенно проверяйте: Переносите проверку ограничений из критического пути записи, где это безопасно.
Применяя эти принципы, вы создаете модель данных, способную поддерживать рост без ущерба для производительности. Цель не в том, чтобы устранить сложность, а в том, чтобы управлять ею таким образом, чтобы поддерживать скорость вашего приложения.