











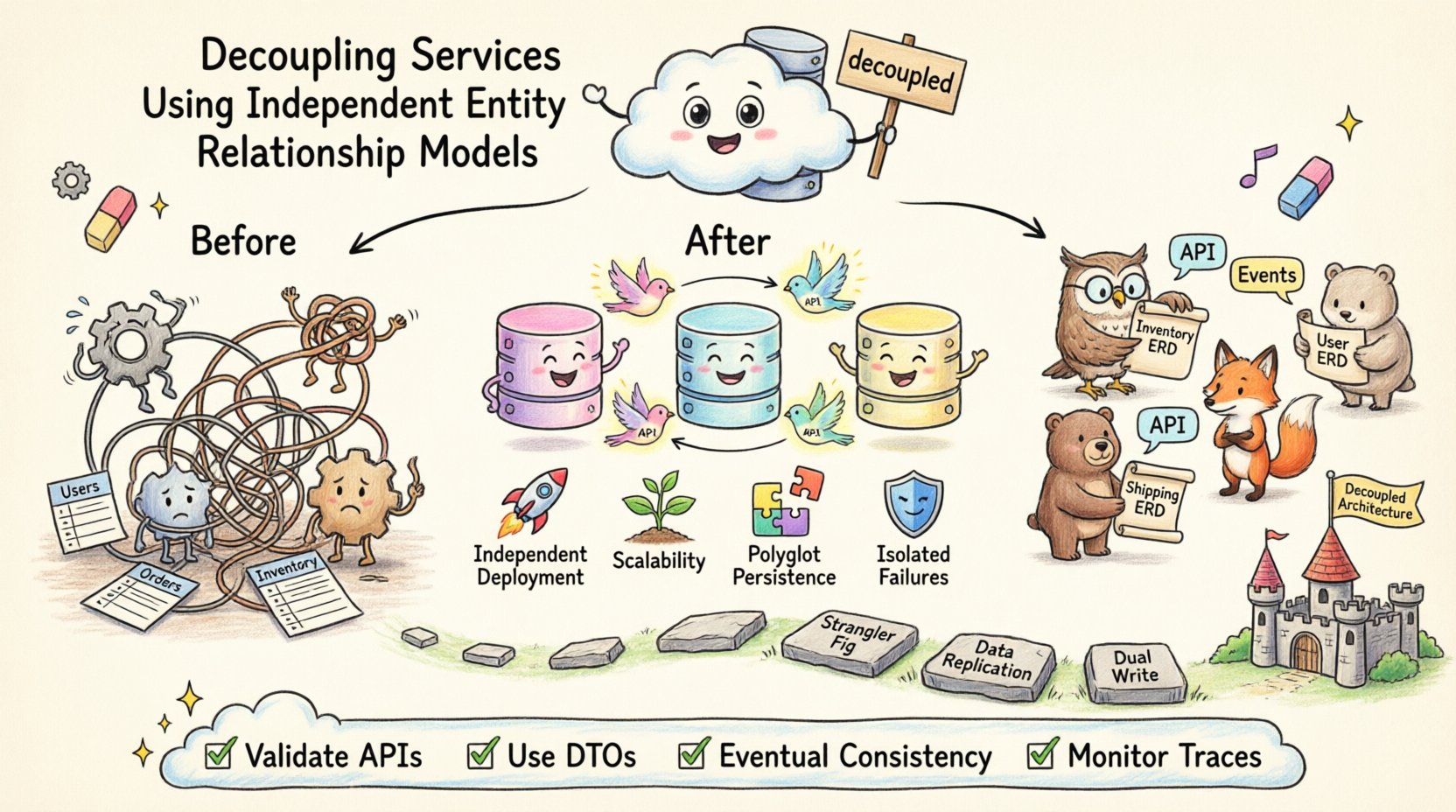
В современной архитектуре программного обеспечения разделение ответственности распространяется не только на логику кода, но и на владение данными. Когда службы используют одну и ту же схему базы данных, они неизбежно становятся зависимыми от внутренних реализаций друг друга. Такая тесная связь создает уязвимость, замедляет скорость развертывания и усложняет масштабирование. Чтобы достичь настоящей модульности, команды должны использовать независимые модели сущностей и отношений для каждого границы службы. Этот подход гарантирует, что структуры данных остаются частными для службы, которая их владеет, способствуя устойчивости и автономии.
🤔 Проблема совместного использования данных
Устаревшие системы часто полагаются на монолитную базу данных, где несколько модулей приложения обращаются к одним и тем же таблицам. Хотя это упрощает начальную разработку, по мере роста системы это вводит серьезные риски. Изменение требований к данным в одном модуле может нарушить функциональность другого модуля, который зависит от той же структуры таблицы. Это явление известно как антишаблон совместного использования базы данных.
Рассмотрим ситуацию, когда Сервис пользователей должен добавить новое поле в таблицу профиля. Если Сервис заказов напрямую обращается к этой таблице для получения имен пользователей, обновление может потребовать согласованного развертывания или миграции базы данных, которая одновременно затрагивает обе команды. Такая необходимость координации замедляет инновации и увеличивает риск возникновения инцидентов в продакшене.
-
Зависимости развертывания:Службы не могут развертываться независимо, если они используют общие определения схем.
-
Ограничения масштабируемости:Одна база данных часто становится узким местом, когда определенные службы требуют больше ресурсов, чем другие.
-
Риски безопасности:Прямой доступ к таблицам обходит уровень службы, потенциально подвергая утечке логику чувствительных данных.
🗺️ Определение независимых моделей сущностей и отношений
Независимая модель сущностей и отношений (ERD) назначает конкретную схему данных одной службе. Это означает, что служба контролирует свою собственную базу данных, свои собственные таблицы и свои собственные отношения. Другие службы не имеют прямого доступа к этим таблицам. Вместо этого они взаимодействуют через определенные интерфейсы, такие как API или очереди сообщений.
Этот архитектурный стиль часто называютБаза данных на службу. Он согласует владение данными с бизнес-возможностями. Например, Сервис инвентаря управляет уровнями запасов, а Сервис доставки — адресами доставки. Ни одна из служб не должна содержать внешние ключи, ссылающиеся на внутренние таблицы другой службы.
Процесс включает:
-
Определение границ:Определите, какие данные относятся к какой бизнес-возможности.
-
Проектирование локальных схем:Создайте ERD, которые поддерживают только конкретные потребности этой службы.
-
Определение интерфейсов:Установите, как данные обмениваются между службами, не раскрывая внутренние структуры.
📈 Ключевые преимущества изоляции схем
Принятие независимых ERD трансформирует способ, которым команды управляют сложностью. Это смещает фокус с централизованного контроля на распределенную автономию. Каждая команда может оптимизировать свою стратегию хранения данных, не беспокоясь о глобальных последствиях.
|
Аспект |
Модель совместного использования базы данных |
Модель независимых ERD |
|---|---|---|
|
Развертывание |
Скоординированные, рискованные |
Независимые, частые |
|
Масштабируемость |
Только горизонтальное масштабирование (кластер) |
Вертикальное масштабирование на сервис |
|
Технология |
Одна тип базы данных |
Многоязычная постоянность |
|
Область отказов |
Единственная точка отказа |
Изолированные сбои |
🔗 Проектирование с ослабленной связностью
Когда сервисы не могут напрямую общаться с базами данных друг друга, они должны взаимодействовать через API. Это требует тщательного проектирования контракта между сервисами. API становится единственным общим контрактом. Если контракт API остается стабильным, лежащая в основе модель данных может изменяться без влияния на потребителей.
Версионирование API: Поскольку модели данных эволюционируют, API должны поддерживать версионирование. Это позволяет старым клиентам работать, в то время как новые клиенты используют обновленные структуры.
Объекты передачи данных (DTO): Не экспонируйте объекты сущностей напрямую. Создавайте специфические DTO, содержащие только данные, необходимые для потребителя. Это предотвращает утечку внутренних изменений наружу.
-
Валидация: Проверяйте входные данные на границе API, а не только на уровне базы данных.
-
Идемпотентность: Обеспечьте, чтобы операции можно было повторять безопасно без создания дублирующих записей.
-
Документация: Поддерживайте четкую документацию для всех форматов обмена данными.
⚖️ Обработка транзакций и согласованности
Одной из наиболее значимых проблем при разъединении является поддержание целостности данных. В общей базе данных транзакция может легко охватывать несколько таблиц. В распределенной системе одна логическая транзакция может охватывать несколько сервисов. Это известно какПроблема распределенной транзакции.
Чтобы решить эту проблему, команды часто используютПотенциальная согласованность паттерн. Вместо того чтобы обеспечить идентичность данных везде сразу, система гарантирует, что данные станут согласованными со временем. Это достигается с помощью асинхронной передачи сообщений.
Паттерн Саги: Сага — это последовательность локальных транзакций. Каждая транзакция обновляет базу данных и публикует событие для запуска следующей транзакции. Если шаг завершается неудачно, выполняются компенсирующие транзакции для отмены предыдущих изменений.
-
Паттерн «Выходная корзина»: Записывайте события в локальную таблицу вместе с основным изменением данных. Процесс в фоновом режиме публикует эти события, что гарантирует отсутствие потери данных.
-
Идемпотентные потребители: Обработчики сообщений должны корректно обрабатывать дублирующие сообщения.
-
Компенсирующие действия: Определите чёткую логику отката для каждого действия вперёд.
🚚 Стратегии миграции
Переход от общей базы данных к независимым ERD — это серьёзное мероприятие. Требуется поэтапный подход для минимизации рисков. Спешка при миграции может привести к потере данных или простою сервисов.
Паттерн «Дерево-разрушитель»: Постепенно переносите функциональность на новые сервисы. Начните с конкретной функции, например, уведомлений пользователей. Создайте новый сервис с собственной ERD для этой функции. Перенаправляйте трафик на новый сервис, оставляя при этом старую систему работающей.
Репликация данных: В процессе перехода вам может потребоваться поддерживать синхронизацию данных между старой и новой базами данных. Это позволяет новому сервису временно читать данные из старой системы, пока он не заполнит собственные данные.
Двойная запись: Записывайте в старую и новую базы данных одновременно в течение окна миграции. Убедитесь, что новый сервис работает корректно, прежде чем отключить запись в старую базу.
🔍 Мониторинг и обслуживание
При независимых хранилищах данных мониторинг становится более сложным. Вы больше не смотрите на единый панель мониторинга состояния базы данных. Вам необходимо агрегировать журналы и метрики из нескольких источников.
Распределённое трассирование: Реализуйте трассирование, чтобы отслеживать запрос при его прохождении через различные сервисы. Это помогает определить, какой сервис вызывает задержки или ошибки.
Реестр схем: Поддерживайте реестр контрактов API. Это гарантирует, что любые изменения в модели данных будут рассмотрены и одобрены до развертывания.
-
Оповещения: Настройте оповещения о задержке репликации и накоплении сообщений в очереди.
-
Планирование ёмкости: Мониторьте рост хранилища для каждого сервиса, чтобы избежать неожиданных расходов.
-
Стратегии резервного копирования: Убедитесь, что каждый сервис имеет собственный план резервного копирования и восстановления.
🛠️ Распространённые ошибки, которые следует избегать
Даже при наличии надежного плана команды часто сталкиваются с трудностями при реализации. Понимание этих распространенных ошибок может сэкономить значительное время и усилия.
-
Скрытая связь: Избегайте использования представлений базы данных или общих таблиц, даже если они находятся в отдельных схемах. Прямой доступ к базе данных должен быть запрещен.
-
Избыточная фрагментация: Не создавайте новую базу данных для каждой небольшой функции. Объединяйте связанные сущности в логические службы.
-
Пренебрежение задержками: Вызовы сети медленнее, чем локальные запросы. Проектируйте API так, чтобы минимизировать количество往返.
-
Сложные запросы: Избегайте соединений между службами. Если вам нужны данные из нескольких служб, запрашивайте их отдельно и объединяйте результаты на уровне приложения.
🧱 Заключительные мысли
Разделение служб с использованием независимых моделей отношений между сущностями — это стратегическое решение, которое окупается в долгосрочной перспективе. Это требует дисциплины в проектировании и готовности управлять распределенной сложностью. Однако результатом является система, которая легче масштабируется, более устойчива к сбоям и быстрее развивается. Обладая собственными данными, службы получают автономию, необходимую для инноваций без постоянной координации.
Начните с определения наиболее критичных границ в вашей системе. Сначала изолируйте данные для этих служб. Постепенно уточняйте контракты API и шаблоны обмена сообщениями. Такой поэтапный подход обеспечивает стабильность при переходе к полностью разобщенной архитектуре.