











W architekturze systemów relacyjnych napięcie między integralnością danych a wydajnością jest stałe. Diagramy relacji encji (ERD) pełnią rolę projektu tej struktury, definiując sposób łączenia tabel. Choć klucze obce zapewniają, że relacje pozostają poprawne, wprowadzają narzut, który może ograniczać przepustowość. Zrozumienie sposobu dostosowania tych ograniczeń jest kluczowe dla systemów obsługujących duże objętości transakcji. Ten przewodnik bada mechanizmy optymalizacji kluczy obcych w celu zachowania spójności bez poświęcania szybkości. ⚡
Zrozumienie kosztu zapewniania integralności 🛡️
Klucze obce to nie tylko etykiety; są to aktywne zasady wymuszane przez silnik bazy danych. Każda operacja wstawiania, aktualizacji lub usuwania zawierająca klucz obcy wywołuje logikę weryfikacji. Ta logika sprawdza tabelę nadrzędna, aby upewnić się, że odwoływana wartość istnieje. W środowiskach o wysokiej przepustowości ta weryfikacja staje się istotnym kosztem.
Proces weryfikacji zwykle obejmuje:
- Operacje wyszukiwania: System musi wyszukiwać w tabeli nadrzędnej odwołujący się do ID.
- Mechanizmy blokowania: Wiersz nadrzędny często wymaga blokady, aby zapobiec jednoczesnej modyfikacji podczas sprawdzania.
- Przejście przez indeks: Bez odpowiedniego indeksowania silnik przeszukuje duże fragmenty tabeli nadrzędnej.
Gdy miliony transakcji występują na sekundę, te mikro-opóźnienia się akumulują. Celem nie jest usunięcie integralności, ale wygładzenie procesu weryfikacji. Rozważ następujące scenariusze, w których ten narzut wpływa na wydajność:
- Importy partii: Ładowanie danych historycznych często wymaga tymczasowego wyłączania ograniczeń.
- Wysokiej częstotliwości zapisy: Systemy rejestrujące zdarzenia lub dane czujników mogą priorytetowo wybierać szybkość zamiast natychmiastowej spójności.
- Operacje kaskadowe: Usunięcie rekordu nadrzędnego może wywołać aktualizacje w wielu tabelach potomnych.
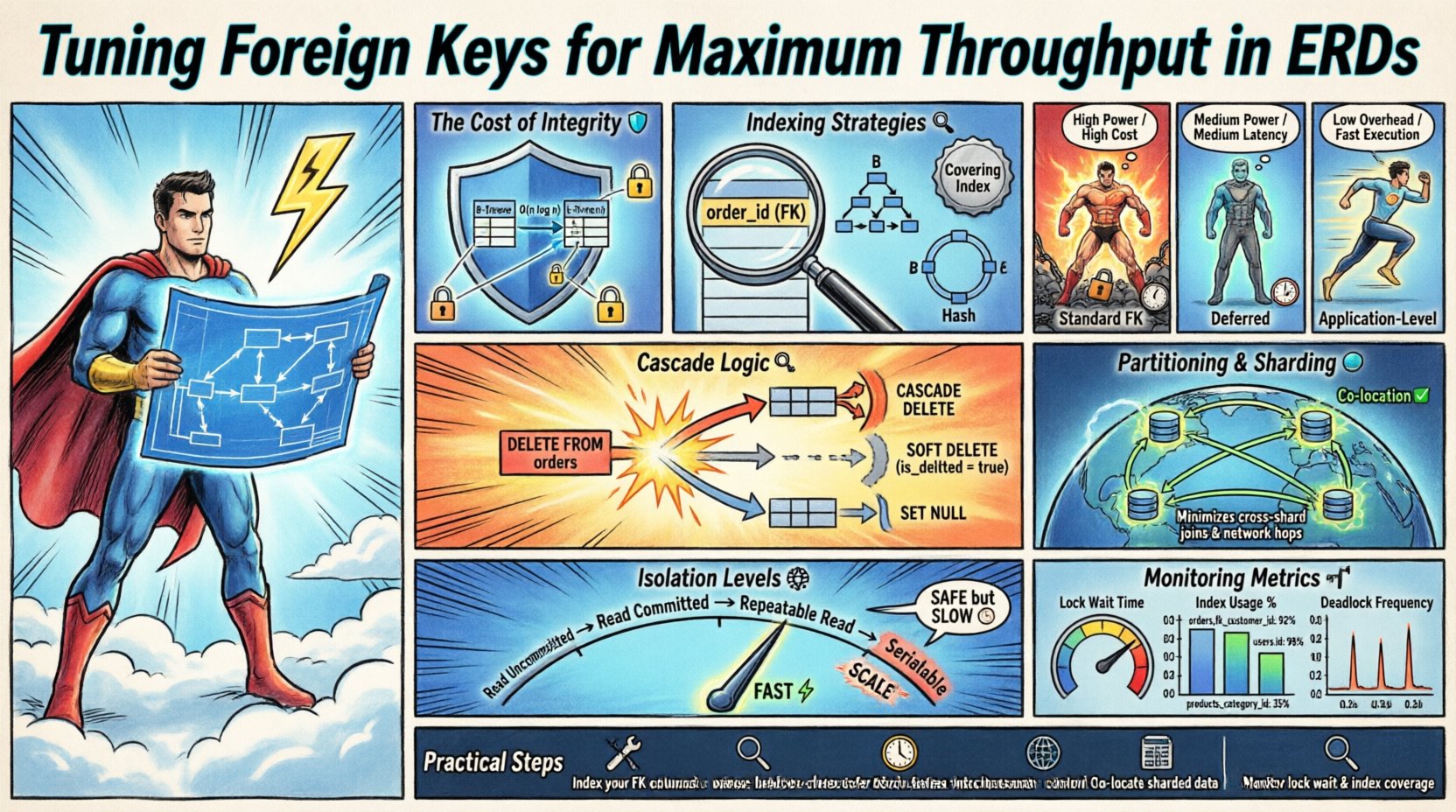
Strategie indeksowania dla kluczy obcych 🔍
Indeksowanie to najbardziej bezpośredni sposób poprawy wydajności kluczy obcych. Tabela potomna musi mieć indeks na kolumnie klucza obcego, aby uniknąć pełnego przeszukiwania tabeli podczas aktualizacji. Jeśli indeks brakuje, baza danych musi przejść całą tabelę nadrzędna, aby zweryfikować relację.
Kluczowe kwestie związane z indeksowaniem to:
- Kolejność kolumn: Jeśli klucz obcy jest częścią indeksu złożonego, jego pozycja ma znaczenie dla planowania zapytań.
- Silnik przechowywania: Różne warstwy przechowywania obsługują indeksy w różny sposób. Struktury B-Tree są powszechne, ale indeksy typu Hash mogą zapewniać szybsze wyszukiwanie podczas sprawdzania równości.
- Indeksy przykrywające: Włączenie klucza obcego do indeksu pozwala silnikowi pobrać dane bez dostępu do sterty.
Powszechnym błędem jest zakładanie, że klucz główny jest wystarczający. Jeśli kolumna klucza obcego jest często wykonywana lub aktualizowana, wymaga własnego dedykowanego indeksu. Zapewnia to, że krok weryfikacji nie stanie się przeszukiwaniem sekwencyjnym.
Typy ograniczeń i ich wpływ 📊
Nie wszystkie klucze obce zachowują się tak samo. Definicja ograniczenia określa zachowanie blokowania oraz zakres sprawdzania. Wybór odpowiedniego typu ograniczenia to kluczowe decyzje projektowe.
Porównaj następujące zachowania ograniczeń:
| Typ ograniczenia | Wpływ zapisu | Wpływ odczytu | Przypadek użycia |
|---|---|---|---|
| Standardowe FK | Wysoki (blokada rodzica) | Niski | Główna dane transakcyjne |
| Odwłokany | Średni (sprawdzenie w momencie zatwierdzenia) | Niski | Wczytywanie masowe / Zadania partii |
| Bez indeksu | Średni (skanowanie rodzica) | Średni | Jeden do wielu z rzadkimi aktualizacjami |
| Poziom aplikacji | Niski (brak blokad bazy danych) | Niski | Wysoka prędkość logowania |
Odłożone sprawdzanie ograniczeń pozwala bazie danych pominąć weryfikację podczas transakcji i wykonać ją wyłącznie w momencie zatwierdzenia. Zmniejsza to czas trwania blokad na tabeli rodzica. Jest szczególnie przydatne, gdy wiele wierszy w tabeli potomnej odnosi się do tego samego rodzica, lub gdy wiersz rodzica może zostać utworzony w ramach tej samej transakcji.
Wzmacnianie zapisu i logika kaskadowa 🔄
Operacje kaskadowe to potężne narzędzia do utrzymania porządku danych, ale powodują wzmacnianie zapisu. Gdy rekord rodzica jest usuwany, system musi znaleźć i usunąć każdy powiązany rekord potomny. Powoduje to wzrost liczby operacji wejścia/wyjścia.
Strategie zmniejszające ten efekt obejmują:
- Miękkie usuwanie: Zamiast fizycznie usuwać rekordy, oznacz je jako nieaktywne. Unika to całkowicie łańcucha kaskadowego.
- Ustaw na NULL: Jeśli relacja jest opcjonalna, ustawienie klucza obcego na NULL jest szybsze niż usuwanie wierszy potomnych.
- Ogranicz Zapobiegaj usuwaniu, jeśli istnieją dzieci. Wymusza to, aby aplikacja obsługiwała czyszczenie w kontrolowany sposób.
W systemach rozproszonych operacje usuwania kaskadowego mogą powodować szczyty opóźnień. Usunięcie pojedynczego rodzica może wyzwolić tysiące aktualizacji dzieci w różnych fragmentach. Często lepiej jest obsługiwać czyszczenie asynchronicznie przy użyciu zadań w tle.
Zagadnienia związane z partycjonowaniem i fragmentacją 🌐
Wraz ze skalowaniem danych wydajność pojedynczej tabeli się pogarsza. Partycjonowanie dzieli duże tabele na zarządzalne fragmenty. Klucze obce komplikują ten proces, ponieważ relacja musi obejmować różne partycje.
Wyzwania w środowiskach partycjonowanych obejmują:
- Bloki przekraczające partycje: Jeśli tabele rodzicielska i potomna są partycjonowane inaczej, silnik musi koordynować blokady między partycjami.
- Nadmiar routingu: Zapytania muszą określić, która partycja zawiera dane odniesione.
- Klucze fragmentacji: Kolumna klucza obcego powinna idealnie być kluczem fragmentacji, aby współlokować powiązane dane.
Jeśli klucz obcy nie jest kluczem fragmentacji, system musi kierować zapytania do odpowiedniego fragmentu w celu weryfikacji. Ta opóźnienie sieciowe się akumuluje. Współlokowanie rekordów rodzicielskich i potomnych na tym samym węźle minimalizuje ten narzut.
Poziomy izolacji transakcji i przepustowość 🧩
Poziom izolacji określa sposób, w jaki transakcje oddziałują na siebie. Wyższe poziomy izolacji zapewniają większą spójność, ale zwiększają konkurencję. Klucze obce bezpośrednio oddziałują na mechanizmy blokowania określone przez poziomy izolacji.
Typowe skutki izolacji:
- Odczyt zatwierdzony: Pozwala na odczyty brudne. Sprawdzanie kluczy obcych może widzieć niezatwierdzone dane z innych transakcji, co może prowadzić do warunków wyścigu.
- Powtarzalny odczyt: Blokuje wiersz rodzicielski na czas trwania transakcji. Zapobiega odczytom fantomów, ale zmniejsza współbieżność.
- Serializowalny: Zapewnia najwyższy poziom bezpieczeństwa. Klucze obce są ściśle wymuszane, ale przepustowość znacznie spada z powodu serializacji.
Wybieranie najniższego poziomu izolacji, który spełnia logikę biznesową, to standardowa technika optymalizacji. Jeśli aplikacja może tolerować spójność ostateczną, obniżenie poziomu izolacji może znacząco poprawić przepustowość zapisu.
Metryki monitorowania i utrzymania 📈
Optymalizacja to ciągły proces. Musisz monitorować konkretne metryki, aby wykryć węzły zatkania związane z kluczami obcymi.
Kluczowe metryki do śledzenia:
- Czas oczekiwania na blokadę: Wysokie wartości wskazują na konkurencję na tabelach rodzicielskich.
- Wykorzystanie indeksów: Nieużywane indeksy marnują pamięć i spowalniają zapisy.
- Częstotliwość zakleszczeń: Klucze obce są częstą przyczyną zakleszczeń w systemach współbieżnych.
- Czas wykonania zapytania:Wolne wstawiania często wskazują na brakujące indeksy w kolumnach kluczy obcych.
Regularne audyty ERD w stosunku do rzeczywistych wzorców zapytań zapewniają, że projekt odpowiada obciążeniu. Schemat zaprojektowany dla dostępu o wysokim obciążeniu odczytu może się różnić od schematu zaprojektowanego dla dostępu o wysokim obciążeniu zapisu.
Prawdziwe kroki wdrożenia 🛠️
Wdrożenie tych optymalizacji wymaga strukturalnego podejścia. Postępuj zgodnie z tymi krokami, aby dostosować swoje środowisko:
- Zaprofiluj bieżące obciążenia: Zidentyfikuj, które tabele generują najwięcej naruszeń kluczy obcych lub blokad.
- Analizuj plany zapytań: Upewnij się, że kolumny kluczy obcych są objęte indeksami.
- Przejrzyj zasady kaskadowe: Zdecyduj, czy konieczne są trwałe usunięcia, czy wystarczą miękkie usunięcia.
- Testuj współbieżność: Symuluj duże objętości zapisów, aby zmierzyć zawieszenie blokad.
- Udoskonal ograniczenia: Przełącz z ON DELETE CASCADE na czyszczenie na poziomie aplikacji tam, gdzie to odpowiednie.
Systematycznie rozwiązując te obszary, zmniejszasz napięcie między integralnością danych a szybkością systemu. Wynikiem jest solidna architektura zdolna do radzenia sobie z rozmiarem bez kompromitowania niezawodności.