











Architektura bazy danych ewoluuje wraz ze złożonością aplikacji. Na wczesnym etapie rozwoju pojedyncza baza danych często wystarcza do obsługi wszystkich operacji danych. Jednak wraz z rozwojem systemu początkowy schemat często staje się wąskim gardłem. Ten stan nazywa się powszechnie schematem monolitycznym. Charakteryzuje się on silnie powiązanymi tabelami, nadmiarowymi danymi oraz sztywnymi ograniczeniami, które utrudniają skalowalność. Aby temu zaradzić, inżynierowie uciekają się do przebudowy strukturalnej. Modelowanie relacji encji (ERM) zapewnia ramy teoretyczne do wizualizacji i organizacji tych zmian w sposób skuteczny. Niniejszy przewodnik bada proces techniczny refaktoryzacji schematów monolitycznych z wykorzystaniem zasad ERM w celu osiągnięcia bardziej odpornego warstwy danych.
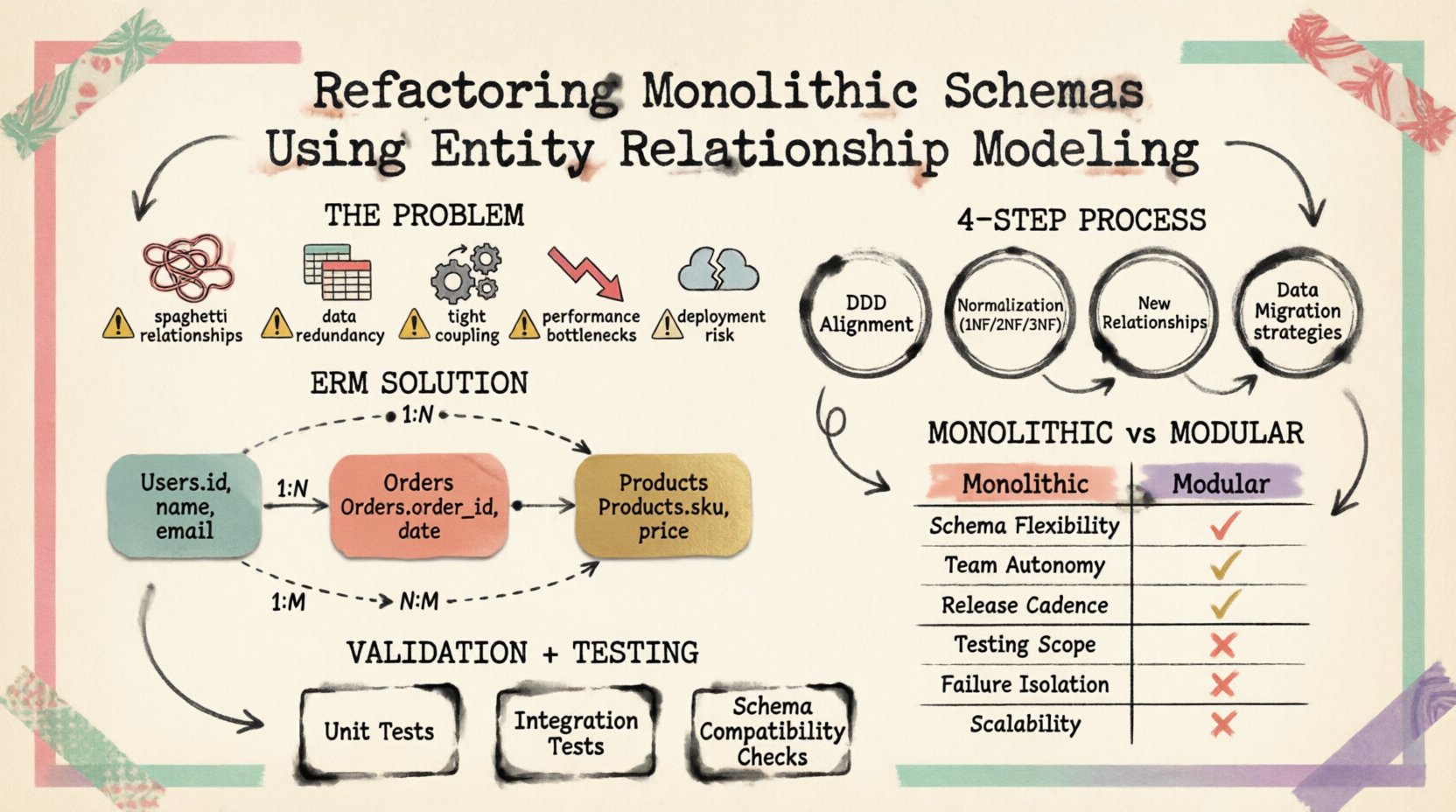
Zrozumienie problemu schematu monolitycznego 📉
Schemat monolityczny zwykle powstaje w wyniku organicznego rozwoju, a nie celowego planowania. Funkcje są dodawane, a tabele tworzone są w celu obsługi natychmiastowych potrzeb bez rozważania przyszłej separacji. Z czasem prowadzi to do kilku wskaźników długu technicznego:
- Związki spaghetti:Klucze obce łączą niepowiązane encje, tworząc zależności cykliczne.
- Nadmiarowość danych:Te same informacje są przechowywane w wielu tabelach, co prowadzi do problemów z spójnością podczas aktualizacji.
- Silne powiązanie:Logika aplikacji nie może zostać rozdzielona, ponieważ struktura bazy danych ją wymusza.
- Wąskie gardła wydajności:Duże tabele z mieszanymi typami danych wymagają skomplikowanych zapytań, które spowalniają operacje odczytu.
- Ryzyko wdrożenia:Zmiana pojedynczej tabeli często wymaga jednoczesnej modyfikacji wielu usług aplikacji.
Uznawanie tych objawów to pierwszy krok ku rozwiązaniu problemu. Celem nie jest jedynie przeorganizowanie tabel, ale dopasowanie struktury danych do logicznych obszarów działalności biznesowej.
Rola modelowania relacji encji 📐
Modelowanie relacji encji służy jako projekt budowy bazy danych. Definiuje encje (tabelki), atrybuty (kolumny) i relacje (klucze obce) w sposób wizualny i logiczny. Podczas refaktoryzacji ERM działa jako mechanizm kontroli zapewniający spójność nowej struktury.
Główne składniki ERM
- Encje: Odpowiadają osobnym obiektom lub pojęciom, takim jakUżytkownicy lubZamówienia. W schemacie stają się one tabelami.
- Atrybuty: Właściwości opisujące encję, takie jakemail lubcena. Odwzorowują się na kolumny.
- Związki: Określa, jak obiekty wzajemnie się oddziałują, na przykład jedno do jednego lub jedno do wielu.
- Moc zbioru: Określa minimalną i maksymalną liczbę wystąpień uczestniczących w związku.
Korzystanie z modelu ERM podczas refaktoryzacji pozwala zespołom symulować zmiany przed ich zastosowaniem w środowisku produkcyjnym. Pomaga w wykrywaniu danych bez rodziców, brakujących ograniczeń oraz problemów z normalizacją na wczesnym etapie procesu.
Faza oceny przed refaktoryzacją 🔍
Zanim zmieni się dowolna istniejąca tabela, wymagana jest szczegółowa audyt. Ta faza zapewnia, że żadna logika biznesowa nie zostanie utracona podczas przejścia.
- Inwentaryzacja istniejących tabel: Dokumentuj każdą tabelę, kolumnę, indeks i ograniczenie obecnie znajdujące się w systemie.
- Analiza wzorców zapytań: Zidentyfikuj, które zapytania są wykonywane najczęściej, oraz które tabele są najczęściej odczytywane.
- Mapowanie zależności danych: Śledź, jak dane przepływają od bazy danych do aplikacji i z powrotem.
- Zidentyfikuj nadmiarowe kolumny: Poszukaj kolumn, które przechowują tę samą informację w wielu tabelach.
- Przejrzyj klucze obce: Określ, czy relacje są wymuszane na poziomie bazy danych, czy zarządzane są w kodzie.
Ta ocena tworzy podstawę. Bez niej refaktoryzacja może wprowadzić subtelne błędy, które później będzie trudno wykryć.
Proces refaktoryzacji: krok po kroku 🔄
Przekształcanie schematu monolitycznego w strukturę modułową wymaga systematycznego podejścia. Poniższe kroki przedstawiają standardowy przepływ pracy refaktoryzacji schematu przy użyciu modelowania relacji między encjami.
1. Wyrównanie z projektowaniem opartym na domenie (DDD)
Zacznij grupując tabele według domen biznesowych. Czasem nazywa się to ograniczonym kontekstem. Zamiast organizować tabele według funkcji (np. wszystkie tabele do raportowania), organizuj je według możliwości (np. tabele do rozliczeń, tabele do uwierzytelniania). Ta separacja zmniejsza zależność między niepowiązanymi częściami systemu.
2. Normalizacja
Normalizacja zmniejsza nadmiarowość danych i poprawia integralność. Proces polega na rozkładaniu dużych tabel na mniejsze, logicznie powiązane.
- Pierwsza postać normalna (1NF): Upewnij się, że wartości są atomowe. Każda kolumna powinna zawierać tylko jedną wartość.
- Druga postać normalna (2NF): Usuń częściowe zależności. Wszystkie atrybuty niekluczowe muszą zależeć od całego klucza głównego.
- Trzecia postać normalna (3NF): Usuń zależności przechodnie. Atrybuty niekluczowe nie powinny zależeć od innych atrybutów niekluczowych.
Choć 3NF jest standardowym celem, pewne wymagania dotyczące wydajności mogą wymagać kontrolowanej denormalizacji. Decyzja ta musi zostać zarejestrowana.
3. Definiowanie nowych relacji
Po podzieleniu tabel relacje muszą zostać ponownie utworzone. Obejmuje to tworzenie nowych kluczy obcych oraz tabel pośrednich dla relacji wiele do wielu. Na przykład, jeśli Produkt może należeć do wielu Kategorii, to potrzebna tabela pośrednia do ich połączenia.
4. Strategia migracji danych
Przenoszenie danych z starego schematu do nowego to najbardziej ryzykowny etap. Strategie obejmują:
- Migracja zrzutu (snapshot):Zatrzymaj zapisy, eksportuj dane, przekształć je i zaimportuj do nowego schematu. Wymaga czasu przestoju.
- Zapis dwukrotny:Zapisuj do starego i nowego schematu jednocześnie w czasie przejściowym.
- Replikacja oparta na dzienniku: Zbieraj zmiany z dziennika transakcji bazy danych i stosuj je do nowej struktury.
Typowe pułapki do uniknięcia 🛑
Refaktoryzacja wprowadza złożoność. Niektóre błędy mogą naruszyć integralność systemu.
- Ignorowanie typów danych: Zmiana kolumny z Liczba całkowita na Ciąg znaków bez weryfikacji logiki w dalszych etapach może uszkodzić kod aplikacji.
- Zbyt duża normalizacja: Tworzenie zbyt wielu tabel może prowadzić do nadmiernych połączeń, pogarszając wydajność zapytań.
- Utrata ograniczeń: Przenoszenie ograniczeń z bazy danych na warstwę aplikacji może prowadzić do zanieczyszczenia danych, jeśli wiele usług zapisuje do tych samych danych.
- Ignorowanie indeksów: Nowe tabele wymagają nowych indeksów. Niezaindeksowanie nowych kluczy obcych spowolni operacje połączeń.
Strategie weryfikacji i testowania ✅
Po przebudowie schematu ważna jest weryfikacja. Testy automatyczne powinny potwierdzać, że integralność danych jest zachowana na nowych granicach.
- Sprawdzanie spójności danych:Uruchom zapytania, aby upewnić się, że integralność referencyjna jest zachowana we wszystkich nowych relacjach.
- Benchmarkowanie wydajności: Porównaj czasy wykonania zapytań przed i po przekształceniu.
- Weryfikacja liczby wierszy: Upewnij się, że całkowita liczba rekordów pozostaje stała (z wyłączeniem duplikatów utworzonych podczas migracji).
- Testy regresyjne aplikacji: Uruchom pełny zestaw testów aplikacji względem nowej struktury bazy danych.
Porównanie: Schemat monolityczny vs. modularny
Poniższa tabela przedstawia różnice między dziedziczną strukturą monolityczną a przekształconą strukturą modularną.
| Funkcja | Schemat monolityczny | Przekształcony schemat |
|---|---|---|
| Struktura tabeli | Duże tabele o różnych przeznaczeniach | Specjalizowane tabele dedykowane dla konkretnych dziedzin |
| Zmieszanie danych | Wysokie | Zminimalizowane poprzez normalizację |
| Skalowalność | Trudne do rozdzielania | Łatwiejsze dzielenie według dziedziny |
| Wdrożenie | Globalne zmiany schematu | Lokalne aktualizacje schematu |
| Złożoność zapytań | Złożone łączenia na dużych tabelach | Optymalizowane łączenia na mniejszych tabelach |
Przejście do architektury mikroserwisów 🚀
Refaktoryzacja schematu często jest wstępem do wprowadzania mikroserwisów. Czysty model relacji encji ułatwia przypisanie odpowiedzialności za konkretne dane konkretnym usługom. Gdy każda usługa zarządza własną bazą danych, schemat staje się umową między usługami, a nie zasobem współdzielonym.
Taka zmiana wymaga starannego zarządzania spójnością danych. Zamiast korzystania z transakcji między wieloma bazami danych, systemy mogą polegać na wzorcach spójności ostatecznej. Model relacji encji pomaga jasno zdefiniować te granice, zapewniając, że żadna usługa nie przyjmuje odpowiedzialności za dane, które nie zarządza.
Ostateczne rozważania dotyczące długoterminowego zdrowia 🛡️
Utrzymanie zdrowego schematu wymaga ciągłej dyscypliny. Dokumentacja musi być aktualizowana za każdym razem, gdy dodawana lub modyfikowana jest tabela. Kontrola wersji powinna być stosowana do definicji schematu, a nie tylko do kodu aplikacji. Należy planować regularne przeglądy, aby wykrywać nowe przypadki sprzężenia, gdy dodawane są nowe funkcje.
Modelowanie relacji encji to nie jednorazowe zadanie. Jest to ciągła praktyka zapewniająca, że baza danych pozostaje zgodna z potrzebami biznesowymi. Przestrzegając tych zdefiniowanych kroków, organizacje mogą ograniczyć ryzyko związane z dziedzicznymi strukturami danych i stworzyć fundament umożliwiający wspieranie przyszłego rozwoju.
Przejście od schematu monolitycznego do projektu modułowego to istotne przedsięwzięcie. Wymaga cierpliwości, szczegółowego testowania oraz głębokiego zrozumienia relacji danych. Jednak rezultatem jest system łatwiejszy w utrzymaniu, szybszy w skalowaniu i bardziej odporny na zmiany. Wkład w modelowanie przynosi zyski w postaci stabilności operacyjnej i szybszego tempa pracy programistów w długiej perspektywie.