











Projektowanie solidnej architektury danych wymaga więcej niż tylko rysowania pudełek i linii. Wymaga głębokiego zrozumienia, jak dane przepływają, rosną i oddziałują w czasie. Gdy system skaluje się, model relacji encji (ERD) pełni rolę projektu zaprojektowanego dla spójności logicznej, podczas gdy strategie partycjonowania rozwiązują problemy związane z wydajnością fizyczną. Dopasowanie tych dwóch aspektów jest kluczowe do utrzymania szybkości zapytań, integralności danych i efektywności operacyjnej. Niniejszy przewodnik omawia sposób harmonizowania technik partycjonowania z istniejącymi modelami danych bez wprowadzania nadmiarowej złożoności lub ryzyka.
🧩 Podstawa: ERD jako projekt
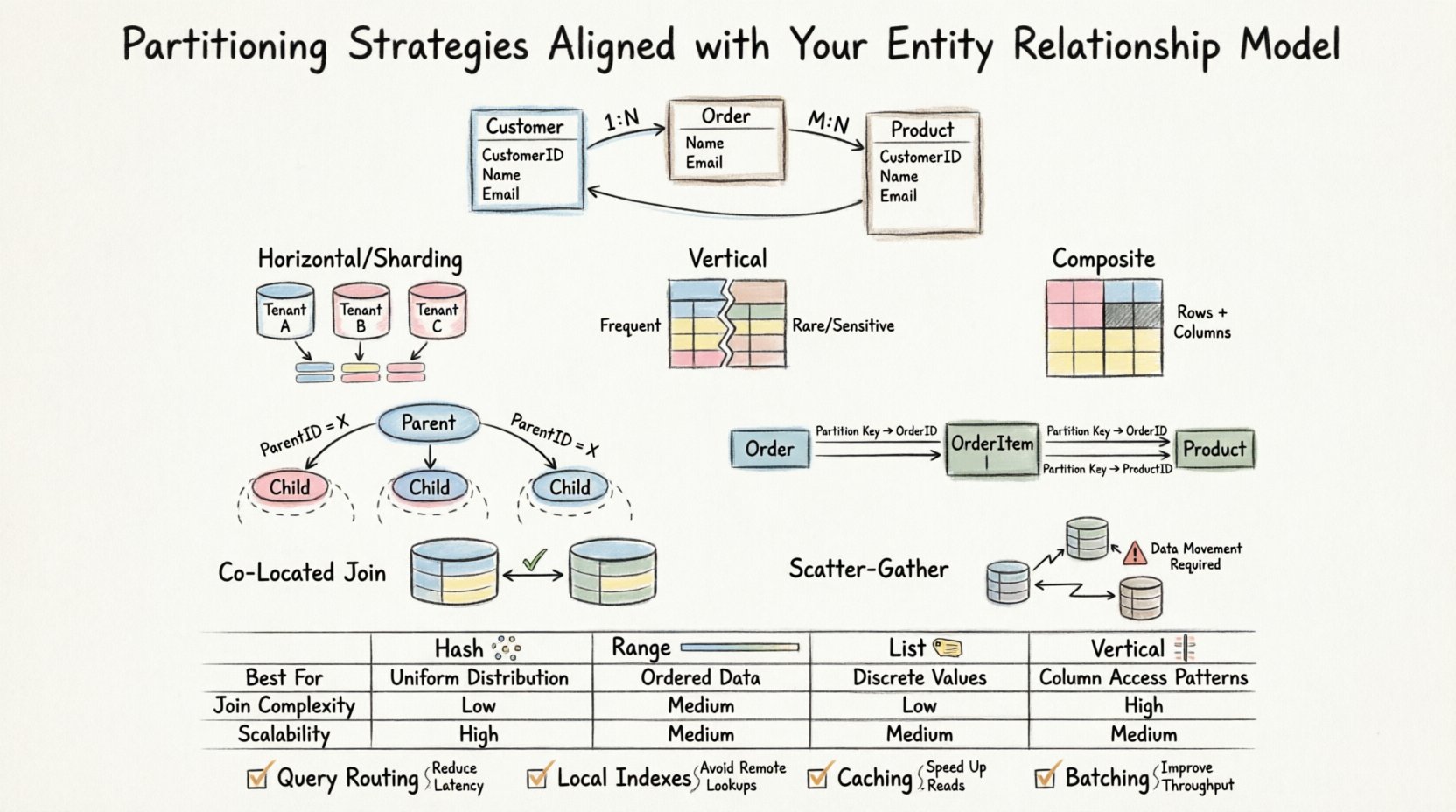
Zanim rozważysz sposób podziału danych, musisz zrozumieć relacje, które je łączą. ERD definiuje encje, atrybuty oraz liczność między nimi. Te relacje decydują o tym, jak dane są pobierane i łączone. Gdy wprowadzasz partycjonowanie, w istocie rozpraszasz te relacje logiczne na granicach fizycznych przechowywania danych.
Zastanów się nad poniższymi skutkami partycjonowania dla Twojego schematu:
- Klucze główne: Muszą być starannie wybrane, aby zapewnić równomierny podział danych między partycje.
- Klucze obce: Łączenie tabel w różnych partycjach może powodować istotne obciążenie.
- Indeksy: Globalne indeksy mogą stać się wąskimi gardłami, jeśli nie zostaną zaprojektowane z uwzględnieniem klucza partycji.
- Lokalizacja danych: Powiązane dane powinny idealnie znajdować się na tym samym węźle, aby zmniejszyć opóźnienia sieciowe.
Ignorowanie tych czynników może prowadzić do sytuacji, w której model logiczny działa idealnie w projektowaniu, ale fizyczna realizacja ma trudności pod obciążeniem. Celem jest utrzymanie powiązanych danych blisko siebie, jednocześnie pozwalając na niezależny wzrost.
🔄 Typy partycjonowania i dopasowanie do schematu
Różne metody partycjonowania pasują do różnych wzorców dostępu do danych. Wybór odpowiedniej metody zależy w dużej mierze od tego, jak Twój ERD definiuje relacje oraz jakie wzorce zapytań oczekujesz. Poniżej znajduje się analiza typowych strategii i ich interakcji z strukturami relacyjnymi.
Poziome partycjonowanie (sharding)
Poziome partycjonowanie dzieli wiersze tabeli na różne grupy. Jest często stosowane, gdy tabele stają się zbyt duże, aby można je było zarządzać w jednym egzemplarzu. W kontekście ERD ta strategia działa najlepiej, gdy klucz partycji koreluje z naturalnym wzorcem dostępu.
- Przypadek użycia: Duże tabele transakcyjne z wyraźnie zdefiniowanymi grupami użytkowników lub klientów.
- Wpływ na ERD: Klucze obce wskazujące na tabelę nadrzędna muszą być starannie zarządzane. Jeśli tabela nadrzędna również jest partycjonowana, klucze muszą być zsynchronizowane.
- Zalety: Pozwala na ogromne skalowanie poprzez dodawanie większej liczby węzłów.
- Wyzwanie: Złożone zapytania obejmujące wiele partycji wymagają logiki agregacji.
Pionowe partycjonowanie
Pionowe partycjonowanie dzieli kolumny tabeli na różne grupy. Jest użyteczne, gdy określone kolumny rzadko są dostępne jednocześnie, albo gdy dane poufne wymagają izolacji.
- Przypadek użycia: Tabele z szerokimi wierszami, gdzie tylko podzbiór kolumn jest często zapytywany.
- Wpływ ERD: Klucz główny musi istnieć we wszystkich pionowych partycjach, aby umożliwić odtworzenie pełnego wiersza.
- Zalety:Zmniejsza I/O poprzez ładowanie tylko niezbędnych kolumn do pamięci.
- Wyzwanie:Wymagane są połączenia, aby odtworzyć całą encję, co zwiększa złożoność zapytań.
Złożone partycjonowanie
Ten podejście łączy strategie poziome i pionowe. Jest często konieczne w systemach o wysokiej wydajności, gdzie zarówno objętość wierszy, jak i szerokość kolumn są istotnymi ograniczeniami.
- Przypadek użycia:Magazynowanie danych lub dzienniki handlu高频.
- Wpływ ERD: Wymaga sztywnej definicji schematu przed wdrożeniem.
🔑 Wyrównywanie kluczy z relacjami
Najważniejszym krokiem w tym procesie jest wybór klucza partycji. Ten klucz określa, do którego jednostki fizycznej przechowywania przechodzi dany wiersz. W kontekście relacyjnym klucz partycji powinien idealnie odpowiadać relacjom kluczy obcych.
Relacje rodzic-dziecko
Podczas pracy z relacjami jeden do wielu tabela potomna często rośnie znacznie szybciej niż rodzic. Jeśli partycjonujesz tabelę potomną według ID rodzica, wszystkie powiązane rekordy potomne znajdują się na tym samym węźle.
- Zaleta: Zapytania pobierające rodzica i wszystkie dzieci nie wymagają komunikacji między węzłami.
- Zaleta: Usuwanie kaskadowe jest wykonywane efektywnie w ramach jednej partycji.
- Ostrzeżenie: Jeśli jeden rodzic ma znacznie więcej dzieci niż inne, może wystąpić zniekształcenie danych.
Relacje wiele do wielu
Relacje wiele do wielu zwykle obejmują tabelę pośrednią. Ta tabela może stać się węzłem zatkania wydajności, jeśli nie zostanie poprawnie partycjonowana.
- Strategia: Partycjonuj według jednego z zaangażowanych kluczy obcych.
- Strategia: Upewnij się, że zapytania zawsze filtrowane są według klucza partycji, aby uniknąć pełnych skanowań tabel.
- Strategia: Unikaj łączenia tabel pośrednich między wieloma partycjami, chyba że jest to absolutnie konieczne.
⚖️ Obsługa operacji łączenia
Łączenia są życiodajnym elementem baz danych relacyjnych, ale stają się kosztowne, gdy dane są podzielone. Zrozumienie sposobu działania łączeń między partycjami jest kluczowe dla utrzymania wydajności.
Partycje współlokalizowane
Jeśli tabela A i tabela B są partycjonowane tym samym kluczem (np. Tenant_ID), łączenie między nimi odbywa się lokalnie. Silnik bazy danych nie musi przenosić danych między węzłami.
- Wymóg:Obie tabele muszą używać tej samej metody i klucza partycjonowania.
- Wymóg:ERD musi logicznie wspierać tę zgodność.
Łączenia typu scatter-gather
Gdy tabele są partycjonowane inaczej, system musi pobrać dane z wielu węzłów, zagrupować wyniki i następnie zwrócić ostateczny zestaw. Operacja ta nazywa się operacją typu scatter-gather.
- Koszt wydajności: Wysokie obciążenie sieciowe.
- Koszt wydajności: Zwiększone opóźnienie.
- Zalecenie: Minimalizuj te łączenia w fazie projektowania ERD.
🛡️ Utrzymanie integralności między partycjami
Ograniczenia integralności danych są trudniejsze do zapewnienia, gdy dane są rozproszone. ERD definiuje te zasady logicznie, ale implementacja musi radzić sobie z fizycznym rozłożeniem danych.
- Integralność referencyjna:Zapewnienie istnienia rekordu potomka przed wstawieniem rekordu nadrzędnego jest skomplikowane, jeśli znajdują się na różnych węzłach.
- Ograniczenia unikalności:Unikalność globalna wymaga koordynacji między wszystkimi partycjami.
- Wyzwalacze:Wyzwalacze na poziomie aplikacji często zastępują wyzwalacze na poziomie bazy danych w środowiskach rozproszonych, aby uniknąć problemów z blokadami.
- Transakcje:Transakcje rozproszone mogą wpływać na przepustowość. Prócz tego, utrzymuj transakcje lokalne w jednej partycji, jeśli to możliwe.
📊 Porównanie strategii partycjonowania
Poniższa tabela podsumowuje, jak różne strategie oddziałują na typowe scenariusze ERD.
| Strategia | Najlepsze dla scenariusza ERD | Złożoność łączenia | Skalowalność zapisu |
|---|---|---|---|
| Partycjonowanie haszowe | Wymagana równomierna dystrybucja, bez określonego zakresu | Wysoka (losowa dystrybucja) | Wysoka |
| Partycjonowanie zakresowe | Identyfikatory oparte na dacie lub sekwencyjne | Niska (jeśli dopasowana) | Średnia |
| Partycjonowanie listowe | Stałe kategorie (np. Region, Status) | Niska (jeśli dopasowana) | Wysoka |
| Partycjonowanie pionowe | Szerokie wiersze, rzadko używane kolumny | Średnia (wymaga ponownej konstrukcji) | Wysoka |
🔄 Ewolucja i migracja
Ewolucja schematu jest nieunikniona. Wymagania biznesowe się zmieniają, a do dodawanych są nowe atrybuty. Podczas modyfikacji ERD strategia partycjonowania musi zostać przeanalizowana.
- Dodawanie kolumn:Partycjonowanie pionowe ułatwia dodawanie kolumn, ponieważ mogą one być umieszczone na nowej partycji.
- Zmiana kluczy:Przepartycjonowanie istniejących danych to ciężka operacja. Zaprojektuj ją już na etapie początkowym.
- Archiwizacja:Partycjonowanie umożliwia łatwe archiwizowanie starych zakresów danych bez wpływu na aktywne partycje.
- Monitorowanie:Regularnie sprawdzaj rozmiary partycji, aby upewnić się, że żadna partycja nie stanie się punktem przepływu.
🚀 Wskazówki optymalizacji wydajności
Aby zapewnić, że system pozostaje reaktywny, należy zastosować konkretne optymalizacje w połączeniu z strategią partycjonowania.
- Routing zapytań: Upewnij się, że aplikacje wysyłają zapytania do odpowiedniego węzła partycji na podstawie klucza partycji.
- Indeksowanie: Lokalne indeksy są szybsze niż globalne indeksy. Projektuj indeksy tak, aby odpowiadały kluczowi partycji.
- Buforowanie: Często używane tabele wyszukiwania nie powinny być partycjonowane, jeśli są wystarczająco małe, aby zmieścić się w pamięci na wszystkich węzłach.
- Grupowanie: Grupuj operacje wstawiania i aktualizacji, aby zmniejszyć narzut transakcji między partycjami.
🔍 Ostateczne rozważania
Tworzenie systemu, który skaluje się, wymaga równowagi między jasnością logiczną a ograniczeniami fizycznymi. Model relacji encji zapewnia zasady spójności danych, podczas gdy partycjonowanie zapewnia mechanizm rozwoju. Gdy te dwa aspekty są zsynchronizowane, system pozostaje wydajny nawet przy wykładniczym wzroście objętości danych.
Skup się na relacjach zdefiniowanych w twoim modelu. Jeśli dane są naturalnie grupowane według określonego atrybutu, użyj tego atrybutu jako klucza partycji. Jeśli złączenia są często wykonywane, upewnij się, że powiązane tabele dzielą ten sam mechanizm partycjonowania. Unikaj nadmiernego skomplikowania schematu za pomocą partycji, które nie spełniają jasnego celu wydajności.
Przestrzeganie tych zasad pozwala stworzyć fundament wspierający długoterminową stabilność. Celem nie jest tylko przechowywanie danych, ale ich strukturyzowanie w sposób umożliwiający adaptację systemu do przyszłych wymagań bez konieczności kompleksowej przebudowy. Czynne planowanie na etapie projektowania oszczędza znaczne wysiłki inżynierskie podczas eksploatacji.