










W nowoczesnej architekturze przedsiębiorstw danych rzadko znajduje się w jednym izolowanym miejscu. Zespoły rozciągają się na całym świecie, systemy rozwijają się niezależnie, a schematy baz danych muszą być zsynchronizowane bez przeszkód. Ta rzeczywistość tworzy konkretny wyzwanie: utrzymanie spójności w rozproszonych diagramach encji-związków (ERD). Gdy wiele grup projektuje modele danych dla tego samego domeny logicznej, rozbieżność jest nieunikniona bez ścisłego zarządzania.
Niespójne schematy prowadzą do błędów integracji, niejasnych definicji danych i istotnego długu technicznego. Ten artykuł omawia metody strukturalne i proceduralne wymagane do utrzymania synchronizacji rozproszonych modeli danych. Skupimy się na standardach, przepływach pracy i technikach weryfikacji zapewniających, że architektura danych pozostaje solidna niezależnie od miejsca, w którym odbywa się modelowanie.
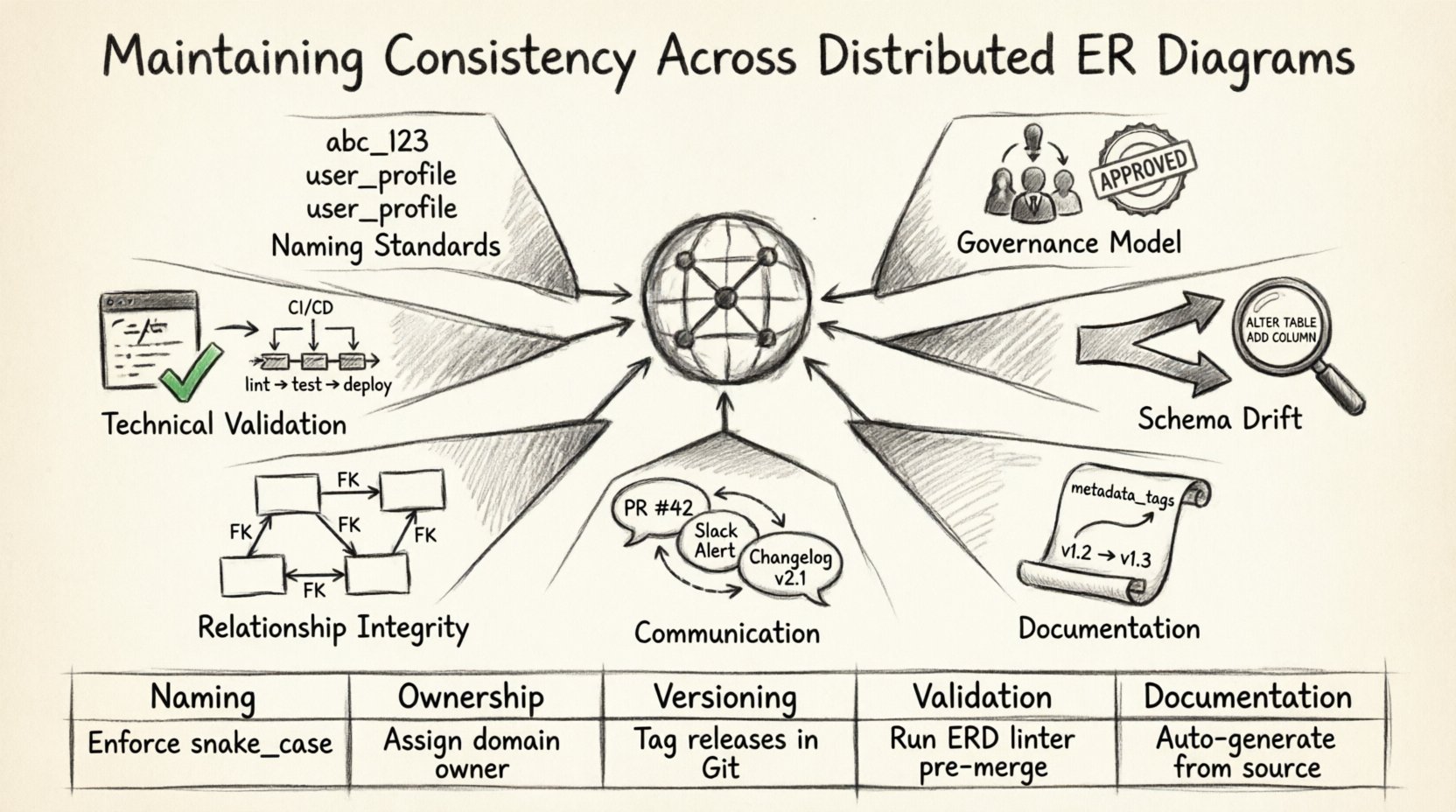
🔍 Dlaczego spójność ma znaczenie w środowiskach rozproszonych
Spójność danych nie dotyczy jedynie dopasowania wizualnego na diagramie. Chodzi o integralność semantyczną. Gdy dwie zespoły inaczej definiują encję „Klient”, aplikacje zewnętrzne cierpią. Jedna może traktować ją jako jedną tabelę, a druga podzielić ją na „Profil” i „Faktury”. Ta fragmentacja utrudnia łączenia, raportowanie i tworzenie interfejsów API.
Zalety zintegrowanego podejścia obejmują:
- Integralność danych:Relacje kluczy obcych pozostają poprawne między usługami.
- Wydajność zapytań:Optymalizowane ścieżki łączenia opierają się na przewidywalnych strukturach schematów.
- Efektywność wdrażania nowych pracowników:Nowi inżynierowie szybciej rozumieją system, gdy standardy są jasne.
- Bezpieczeństwo refaktoryzacji:Zmiany rozprzestrzeniają się logicznie, a nie powodują uszkodzenia zależnych systemów.
📏 Ustanawianie standardów nazewnictwa
Pierwszą linią obrony przed niespójnością jest ścisła zasada nazewnictwa. Bez niej zespół w jednym regionie może nazwać tabelęużytkownicy, a inny używakonta_użytkowników. Z czasem te różnice powodują zamieszanie i powielanie.
Zasady nazewnictwa encji
- Mnogość: Zdecyduj wcześnie, czy tabele powinny być liczba mnoga (np.
zamówienia), czy liczba pojedyncza (np.zamówienie). Przestrzegaj jednego stylu we wszystkich diagramach. - Podkreślniki vs. CamelCase:Standardy SQL często preferują snake_case dla nazw tabel, podczas gdy warstwy zorientowane obiektowo mogą preferować camelCase. Upewnij się, że diagram ERD odzwierciedla warstwę przechowywania danych.
- Domeny z prefiksem: Używaj prefiksów, aby oznaczać domeny biznesowe (np.
fin_zamowienia,hr_pracownicy) aby zapobiec kolizjom w wspólnych przestrzeniach schematów.
Zasady nazewnictwa atrybutów
- Znaczniki czasu: Używaj standardowych sufiksów takich jak
_utworzono_wi_zaktualizowano_wdo śledzenia audytu. - Klucze obce: Nadaj kolumnom nazwy oparte na odwoływanym do tabeli (np.
id_klienta), a nie nazwę relacji. - Flagi logiczne: Przedrostek kolumn logicznych to
is_lubhas_dla jasności (np.is_active).
🛡️ Modele zarządzania dla rozproszonych zespołów
Kto odpowiada za schemat? W rozproszonym środowisku centralizacja często jest niemożliwa, ale całkowita dezentralizacja prowadzi do chaosu. Zwykle najlepiej działa hybrydowy model zarządzania.
Centralny Komitet Standardów
Mała grupa definiuje zasady. Nie tworzą każdego schematu, ale zatwierdzają standardy. Ta grupa utrzymuje dokumentację i rozwiązuje spory dotyczące nazewnictwa lub struktury.
Zdecentralizowane zarządzanie
Zespoły odpowiadają za swoje domeny, ale przestrzegają wspólnego kontraktu. Na przykład zespół Finansowy odpowiada za płatności schematu, ale muszą używać user_id standardu zdefiniowanego przez zespół Core.
Cykle przeglądu
Regularne przeglądy zapobiegają rozbieżnościom. Zaplanuj miesięczne sesje, podczas których przedstawiane są zmiany schematu. Zapewnia to, że nowa encja nie narusza istniejących ograniczeń relacji.
🔄 Zarządzanie rozbieżnościami schematu
Rozbieżność schematu występuje, gdy fizyczna baza danych odbiega od dokumentowanego modelu ERD. Jest to powszechne w systemach rozproszonych, gdzie wdrożenia odbywają się asynchronicznie.
Mechanizmy wykrywania
- Automatyczne porównywanie: Porównaj strukturę działającej bazy danych z kanonicznym modelem ERD.
- Skrypty migracji: Traktuj zmiany schematu jak kod. Każda zmiana musi być wersjonowana i śledzona.
- Tagi metadanych: Wstaw informacje o wersji w metadanych bazy danych lub komentarzach do tabel.
Strategie naprawy
Gdy wykryta zostanie rozbieżność, nie należy jej ignorować. Utwórz zgłoszenie w celu skorygowania różnicy. Optymalnie, model ERD powinien zostać zaktualizowany tak, aby odpowiadał stanowi produkcyjnemu, jeśli zmiana była celowa, lub baza danych powinna zostać cofnięta, jeśli zmiana była nieautoryzowana.
| Typ rozbieżności | Poziom ryzyka | Zalecana czynność |
|---|---|---|
| Brak indeksu | Średni | Zarejestruj w dzienniku zmian; zaplanuj optymalizację. |
| Zmieniony typ danych | Wysoki | Natychmiastowa analiza; potencjalne ryzyko utraty danych. |
| Usunięta kolumna | Krytyczny | Cofnij wdrożenie; przywróć dane, jeśli to możliwe. |
| Dodana kolumna | Niski | Zaktualizuj dokumentację ERD w celu odzwierciedlenia zmiany. |
📄 Dokumentacja i metadane
Diagramy to reprezentacje wizualne, ale metadane zapewniają kontekst. Dobrze utrzymywany ERD zawiera więcej niż tylko linie i prostokąty.
- Definicje biznesowe: Zdefiniuj, co konkretny pole oznacza w terminach biznesowych. Czy to
status„aktywny” czy „zakończony”? - Zasady ograniczeń: Dokumentuj unikalne ograniczenia, ograniczenia sprawdzające i wartości domyślne bezpośrednio na diagramie lub w towarzyszącej wiki.
- Właścicielstwo: Jasną wskazać, która drużyna odpowiada za utrzymanie konkretnych tabel.
- Historia wersji: Śledź, kiedy encje zostały utworzone, zmodyfikowane lub wycofane.
Bez tych metadanych diagram jest tylko obrazkiem. Z nimi diagram staje się umową.
🔗 Integralność relacji
W systemach rozproszonych relacje są często najbardziej kruchą częścią modelu. Klucze obce są klejem, ale mogą stać się wąskimi gardłami lub punktami awarii.
Integralność referencyjna
- Wymuszaj na poziomie bazy danych: Używaj ograniczeń kluczy obcych tam, gdzie jest to możliwe, aby zapobiec powstaniu zaniedbanych rekordów.
- Sprawdzanie na poziomie aplikacji: W mikroserwisach wymuszaj logikę na warstwie aplikacji, jeśli ograniczenia na poziomie bazy danych nie są możliwe.
Zgodność liczby elementów
Upewnij się, że liczba elementów (jeden do jednego, jeden do wielu) zdefiniowana w ERD odpowiada rzeczywistemu wykorzystaniu danych. Relacja jeden do wielu narysowana na diagramie nie może być zaimplementowana jako jedno do jednego w kodzie.
🚧 Powszechne pułapki i jak im zapobiegać
Nawet przy istniejących standardach zespoły popełniają błędy. Rozpoznawanie tych wzorców pomaga zapobiegać przyszłym błędom.
1. Zespół „Złotej Tabeli”
Unikaj jednej tabeli zawierającej dane dla każdego obszaru. Powoduje to wąskie gardło podczas zapisu i sprawia, że schemat staje się monolityczny. Zamiast tego znormalizuj dane w powiązanych encjach.
2. Niejawne relacje
Nie polegaj wyłącznie na nazwach kolumn do definiowania relacji. Jeśli tabela mauser_id, musi być jawnie powiązane zużytkownicy tabelą w ERD.
3. Wartości stałe
Nie osadzaj logiki biznesowej w schemacie. Kolumna o nazwieis_manager jest lepsza niż kolumna o nazwierole_id jeśli rola jest stała. Jednak elastyczne role powinny korzystać z osobnej tabeli odnośnika.
🛠️ Wdrożenie techniczne i weryfikacja
Zasady muszą być stosowane technicznie, a nie tylko słownie. Automatyzacja zmniejsza błędy ludzkie.
- Lintery: Używaj linterek schematu bazy danych, które sprawdzają zgodność z zasadami nazewnictwa.
- Bariery CI/CD: Zablokuj wdrożenia, jeśli różnica schematu nie odpowiada zaakceptowanemu planowi migracji.
- Rejestr schematów: Utrzymuj centralny rejestr wszystkich zaakceptowanych encji i ich wersji.
🤝 Protokoły komunikacji
Technologia to tylko połowa walki. Ludzie muszą skutecznie komunikować zmiany.
- Dzienniki zmian: Każda aktualizacja schematu musi mieć powiązany wpis w dzienniku zmian.
- Analiza wpływu: Zanim zmienisz tabelę, zapisz, które usługi od niej zależą.
- Kanały powiadomień: Używaj dedykowanych kanałów dla alertów schematu, aby zespoły wiedziały, kiedy aktualizować swoje lokalne modele.
Łącząc surowe zasady z otwartą komunikacją, rozproszone zespoły mogą osiągnąć jednolity obraz krajobrazu danych. Celem nie jest kontrolowanie każdej decyzji, ale zapewnienie, że każda decyzja jest zgodna z szerszym wizjonerskim widzeniem architektury.
📊 Podsumowanie najlepszych praktyk
| Obszar | Kluczowa czynność |
|---|---|
| Nazywanie | Wymuszaj zasady snake_case i liczby mnogiej. |
| Prawo własności | Przypisz jasne prawo własności domen zespołom. |
| Wersjonowanie | Śledź wszystkie zmiany schematu jako kod. |
| Weryfikacja | Automatyzuj wykrywanie rozbieżności i raportowanie. |
| Dokumentacja | Utrzymuj metadane aktualne wraz z kodem. |
Spójność między rozproszonymi diagramami ER to ciągły proces. Wymaga on dyscypliny, regularnych audytów oraz zaangażowania w wspólne standardy. Poprawnie wykonane, przekształca rozdrobnione środowisko danych w spójny, wiarygodny zasób.